How can I delete or “merge” all of my duplicate music in Picard
Picard isn’t really the ideal tool for deleting duplicates, but you can use a pretty basic workaround.
Tag all of your music with Picard, and Picard will name duplicates of a song with a number on the end, eg:
01 Coffins.flac
01 Coffins (1).flac
Then you can search your whole music folder for ‘(1)’ (and (2) etc if necessary), and delete them all at once. It’s up to you to check that these are really the files you want to delete!
If you wanted something more specific or anything else, let us know!
4 Likes
Look for a program called Duplicate File Remover. You can chose what to delete.
Lately, I have been re-ripping my library to switch from mp3 to flac. I have been using MusicBee. What I like is that it automatically chooses to keep the “better” format (higher bitrate, I assume), so the cleanup has been very easy.
1 Like
Hi all,
any chance to have an option or an add-on to find and remove duplicates,
based on same acoustic fingerprint ?
1 Like
There’s several things going on here with duplicate music, I see at least these cases:
- Identical files with identical names
- Identical music but different quality
- Identical music but different format (m4a and mp3)
- Identical music, same quality and encoding but the files differ
Ideally I’d like something that solved all of these problems without a lot of work. Let me propose a solution and maybe this could be a plugin or perhaps a mod to MusicBrainz:
First and easiest, ‘Overwrite’ option that instead of creating (1), (2)… versions. Minimally you could ask like windows does ‘What do you want me to do, overwrite, create new name, do this for all the rest?’
Second, when the two formats are identical and it’s only the bitrate that is different, there could be a check box to prefer greatest or least bitrate. This may not actually translate to best fidelity but that could be much harder and this is probably good enough 90% of the time!
Third, when there are multiple formats, you could simply have a list in the options which order to prefer when overwriting. Again, you could ask this in a popup (which to keep? The .m4a or mp3 or both?) And this would be triggered if the Overwrite option was selected.
On using an acoustic fingerprint, I don’t now if Picard does this or not but it does seem to find a large percentage of the music correctly.
1 Like
[quote=“m_grant, post:7, topic:20495”]
Let me propose a solution and maybe this could be a plugin or perhaps a mod to MusicBrainz
[/quote]Pretty much the only way that any of that is going ot happen is if you do it yourself (or get/pay someone to do it), or file a ticket here:
http://tickets.musicbrainz.org/
There’s a few similar/related tickets already, here’s some I’ve found:
http://tickets.musicbrainz.org/browse/PICARD-170
http://tickets.musicbrainz.org/browse/PICARD-131
http://tickets.musicbrainz.org/browse/PICARD-117
http://tickets.musicbrainz.org/browse/PICARD-311
If you can think of the absolute best way to do this, and what exactly would have to be implemented to make it work (breaking it up into little parts/ tickets, new or existing), and figure out any layout or interface changes that would be needed, please vote and comment on the relevant tickets and in here.
Quite frankly, this is unlikely to happen soon because I think people are pretty busy, but if you can noodle out the absolute best way to do this I’m sure it would be helpful, eventually anyway ![]()
3 Likes
I use:
fdupes -rdN .
I just realized that the solution I proposed above only work if the files are EXACTLY the same. If you have two files that differ this will not work. Another solution would be to use:
find . -regex '.* ([0-9]).*' -delete
But keep in mind that this will keep the first file created and delete the remaining duplicates.
1 Like
As mentioned in other thread https://community.metabrainz.org/t/color-coding-or-sorting-files-based-on-validity-of-match/337276 we could remove duplicate music outside musicbrainz if quality can be found in filename.
But: In some other thread I found something of “only 1st 2 minutes are counting for quality” - so you wouldn’t find bad endings like “that was song xxx from band yyy” in the last 15 seconds of your song…
So for me I see 2 steps:
1st derive song quality from whole song
2nd not writing song song(1) song(2)… - writing song(85) song(90) song(75) song(85)(1)…
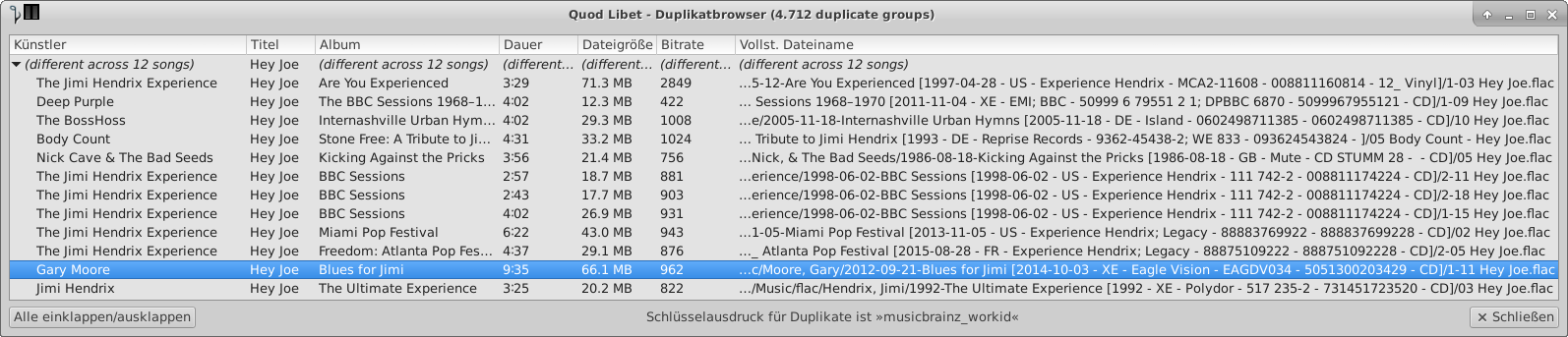
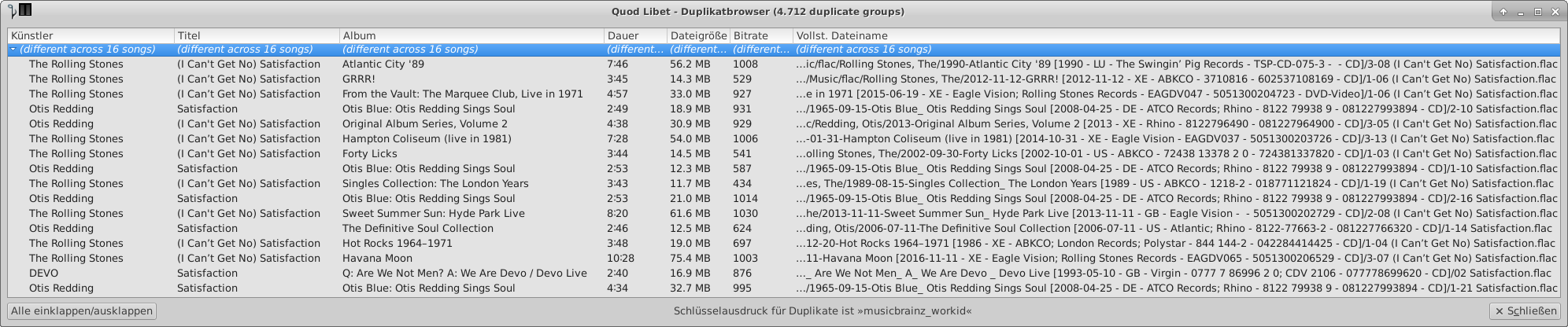
For the great audio player Quod Libet exists a plugin called duplicate browser. You could group on any tag field. I’ve experimented with:
- musicbrainz_trackid
- acoustid_id
- musicbrainz_recordingid
- musicbrainz_workid
As it works on internal file tags it doesn’t matter if file/track naming is different or file type is mp3/flac/ogg/whatever…
Interesting results ![]() Give it a try. Makes fun to experiment with
Give it a try. Makes fun to experiment with
- Some example screenshots for acoustid_id grouping:

The last three I really have to check:

- Some example screenshots for musicbrainz_workid grouping:




4 Likes
Interesting, I haven’t tried QL’s grouping feature for this. Using work or AcoustID is smart. Is there a way to do an approximate search of Chromaprints?
Rather than trying to find things visually, I like the idea of using beets or maybe Quod Libet’s “pluggable query expressions” to find all tracks with a non-unique AcoustID, recording ID, or work ID. Looking at work ID will return many false positives for certain collections, though, like those with lots of standards, art music, or audiobooks.
Doing a lookup against the AcoustId API with the Chromaprint fingerprints is basically doing this. If two Chromaprint fingerprints are similar enough they will share the AcoustId.
1 Like