I have a very large music dataset that apparently has lots of duplicate tracks, of various matching level/score
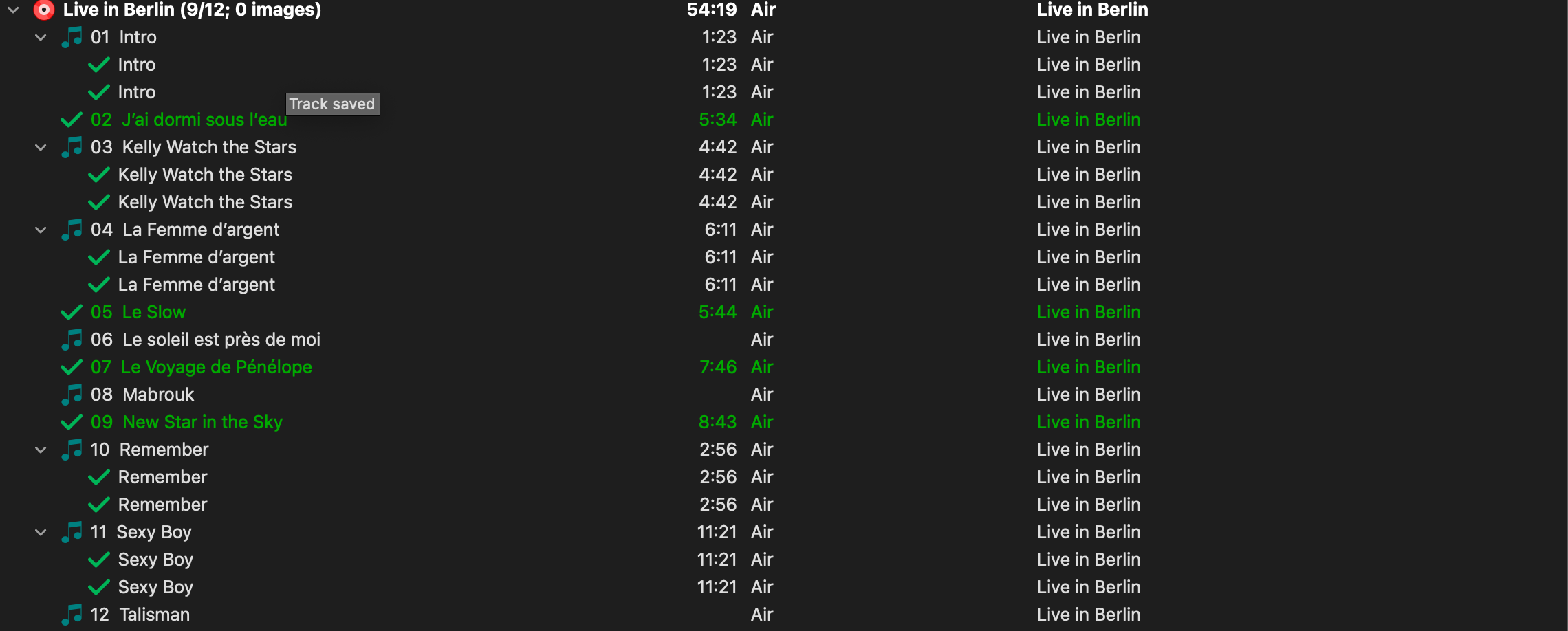
And I am left with lots of these cases as seen in the screenshot, where one track has 2 or more matches of different or equal match level (sometimes both are perfect matches, sometimes one is perfect and the others not, sometimes they just are all of different lower level matching)
I can impossibly go through all theses manually and right click “remove” for all those I do not want.
Is there something like a option/setting/plugin that lets me say:
- if matches are all perfect: just pick the first
- if matches are not all equal: just pick the best
- if all matches are equal but not perfect: just pick the first
I tried to find a plug-in but could not, and as for scripting, I am not sure how I even would start with it (although willing to, if it is the only solution!)
Welcome 
This has been discussed a few times over the years [1] [2] [3], but currently, file de-duplication falls outside the scope of Picard’s abilities.
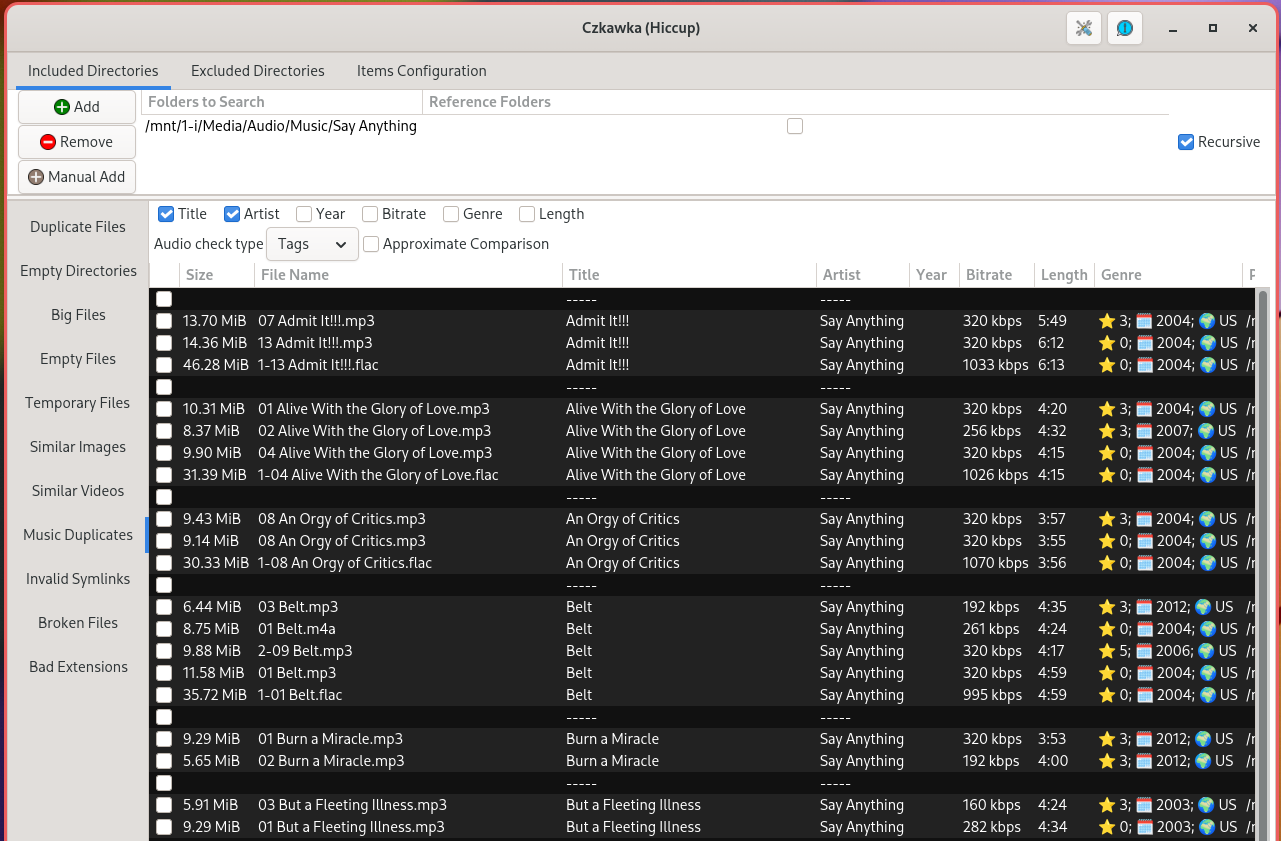
Not sure what system you’re running on, but there’s likely an application available that’s suitable for de-duplication. On Linux, Windows, macOS and FreeBSD, there’s the excellent and free Czkawa, which can scan for files with similar tags, or by audio content using something similar to AcoustID.
2 Likes
Thanks.
Meanwhile I discovered the files are not duplicated. In fact, the origin folders hold always only one file.
It’s Picard that mixes things up from other albums 
For example, I found that it thinks a certain track from another album (sometimes not even the same author) is the “same” as the current album > track. And, that track then will be missing on the other album from which it took it… and when I move it, it says it is a low match.
I am not sure if this has to do with errors in my local file tags?
I will keep testing to see if I can spot some patterns that trigger this behavior.
Based on the green checkmarks in your screenshot, it looks like you’ve saved the metadata to the file’s tags. As this is part of what the similarity logic uses to calculate the match, it’s likely bad embedded tags, along with track length discrepancies contributing to the results you’re describing. If so, you’re going to need to untangle them by ear, matching them to their correct releases manually, or trying the “Scan” option instead of “Lookup”. Note that false positives are fairly common when scanning, and there’s no magic bullet when the data is mangled (garbage in, garbage out, etc.).
5 Likes