This Modification in it’s current format requires you to build your own application and would have to be applied / merged into each subsequent release as desired or possibly added as a more complete option to the official build.
Having found many threads over quite a period of time on dealing with duplicates and managing to get pretty much the ‘perfect’ File Naming Script for my method of sorting / archiving…
I decided to take a stab at dealing with duplicates. There’s got to be -some- way.
My development experience is to where I can look at something and make out whats going on without too much trouble, and even make small modifications. I decided to have a look at the Plug-in docs for Picard and some of the existing plugins to see if there anything I could start from to deal with duplicate files and where they are placed.
I came to the conclusion that there wasn’t any way to deal with files pre-saving with the Plug-in structure. I might be wrong, but I get the idea that all I can do with files is post saving functions.
Right now as we know, Picard checks the generated filename just before saving against what is on disk. If it finds it’s there, it breaks it down, appends in the incremental number, checks it again, no? Write it. Yes? Add the next number to it. … and so on.
So being that at least from what I interpret from the documentation, doing anything with that handling isn’t, at least trivially, within the areas that can be intercepted with a Plug-in.
So I decided to stick a Fork in it.
I found that file saving was done in picard/file.py, and that the code responsible was in _rename(self, old_filename, metadata)
.....
new_dirname = os.path.dirname(new_filename)
if not os.path.isdir(new_dirname):
os.makedirs(new_dirname)
tmp_filename = new_filename
i = 1
while (not pathcmp(old_filename, new_filename + ext)
and os.path.exists(new_filename + ext)):
new_filename = "%s (%d)" % (tmp_filename, i)
i += 1
I thought on a quick hardwired fix, with the intention of dealing with an adding something in the Options section. Ask if you want the duplicates in the same directory as the targets, or somewhere else, which could probably be even defined using scripting functions eventually, but for now "At the File, or in the Directory above (in ‘parallel’)
However being unfamiliar with Python syntax, I asked for help in my circles. Based on my flowchart, a friend that is able to read the docs and chew that stuff up much faster than me came up with this:
tmp_directory,tmp_filename = os.path.split(new_filename)
new_directory = tmp_directory
i = 0
file_found = true
while not (pathcmp(old_filename, new_filename + ext) and file_found)
if not os.path.isdir(new_directory):
os.makedirs(new_directory)
if os.path.exists(new_filename + ext):
i += 1
new_directory = "%s (%d)" % (tmp_directory, i)
new_filename = os.path.join(new_directory, tmp_filename)
else:
file_found = false
I commented off the existing routine and added in this. It didn’t work, as I said, I 'm unfamiliar with Python syntax having never touched it before this. My weaknesses are primarily with the delimiters, separators and such. comma, colon, semicolon, underscore, declaring values, do they need to be bracketed/quoted or not…
So after a bit more reading and follow up chatting with another friend, I realized that Python is particular about the indents, and that there were some areas with parenthesis and colons that needed to be adjusted.
Fixed all that, great, lets run it!
Still didn’t work.
So I changed first i = 0 to i = 1. Nope.
Whats going on, lets look at the shell output instead running this in the blind.
file_found = true - true no defined. WTF?!?!
I totally stumbled on it accidentally. When I was retyping something on another line I noted that when I typed ‘True’ vs. ‘true’ the latter highlighted, the former did not.
**> You have got to be kidding me. WWWW … TtTtT … FfFfF over. ** Hah! Oh come on, this can’t be it!
Case sensitive reserved words? Seriously!?! I certainly don’t recall encountering this before. As best I can tell for Python it’s just the two, **True and False.
Okay!
So the result is now:
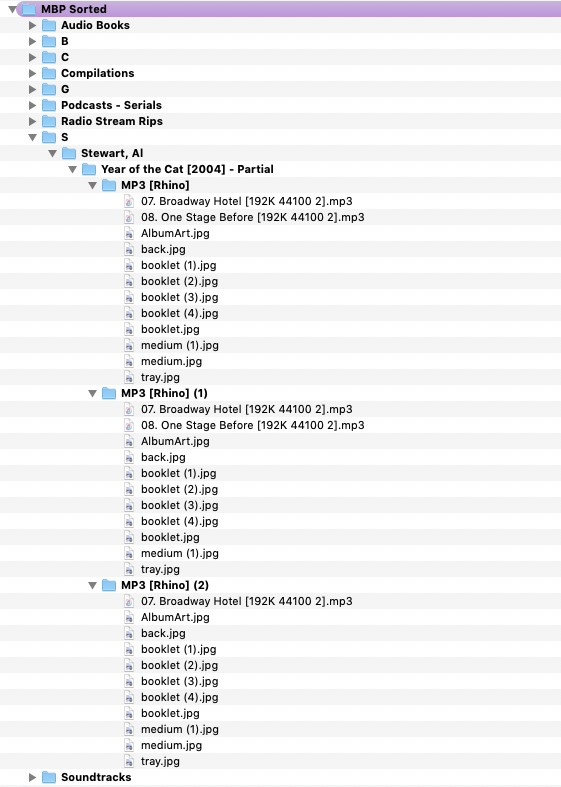
The code is:
def _rename(self, old_filename, metadata):
new_filename, ext = os.path.splitext(
self.make_filename(old_filename, metadata))
if old_filename == new_filename + ext:
return old_filename
tmp_directory,tmp_filename = os.path.split(new_filename)
new_directory = tmp_directory
i = 0
file_found = True
while not pathcmp(old_filename, new_filename + ext) and file_found:
if not os.path.isdir(new_directory):
os.makedirs(new_directory)
if os.path.exists(new_filename + ext):
i += 1
new_directory = "%s (%d)" % (tmp_directory, i)
new_filename = os.path.join(new_directory, tmp_filename)
else:
file_found = False
new_filename = new_filename + ext
log.debug("Moving file %r => %r", old_filename, new_filename)
shutil.move(old_filename, new_filename)
return new_filename
############ Original Code #############
# def _rename(self, old_filename, metadata):
# new_filename, ext = os.path.splitext(
# self.make_filename(old_filename, metadata))
#
# if old_filename == new_filename + ext:
# return old_filename
#
# new_dirname = os.path.dirname(new_filename)
# if not os.path.isdir(new_dirname):
# os.makedirs(new_dirname)
# tmp_filename = new_filename
# i = 1
# while (not pathcmp(old_filename, new_filename + ext)
# and os.path.exists(new_filename + ext)):
# new_filename = "%s (%d)" % (tmp_filename, i)
# i += 1
# new_filename = new_filename + ext
# log.debug("Moving file %r => %r", old_filename, new_filename)
# shutil.move(old_filename, new_filename)
# return new_filename~
############# Original Code #############
I don’t need the duplcated Cover Art, but that is inconsequential compared to having to search for (find. -name "().* so the directories that contain duplicates can be tagged and then dealt with individually.
So, I’ll just setup the DiscID stuff locally, and merge my stuff back in when things get released, as I doubt there’s interest in adding it this way.
The script is posted with the other scripts in the forum: