I only meant it was impossible for the human to verify all the results are good.
Yes, Picard can pull some miracles, but working on 15,000 will mean a small percentage of mistakes that go past unnoticed.
I only meant it was impossible for the human to verify all the results are good.
Yes, Picard can pull some miracles, but working on 15,000 will mean a small percentage of mistakes that go past unnoticed.
What’s the problem?
Isn’t it the case that Picard, regardless of the number of files loaded, puts them in a queue and does its job?
You were asking why your Intel i5 CPU was getting overloaded. And then said you were handing 15,000 files to it and hitting Scan. While Picard can manage to do that, it is certainly not how it was designed to operate.
You will find much quicker easier to handle results if you throw files into Picard in batches.
Write, when I asked about overload.
Overload was while executing debug.log with 15,000 files.
The second debug.log of 357 files takes 17MB. There was also no response for 15 seconds, but he finally opened the window.
They are trying to recreate the situation in the OP for @outsidecontext, to debug/test ![]()
Thanks for the log. I’ll take a look, but might take me a few days currently.
How will I know if it’s already fixed?
12,000 lines in Notepad.
How’s the progress @outsidecontext ?
Sorry, I didn’t have the time to look into this yet. Unfortunately the log seems to be gone from your Google drive, or at least there is no longer any permission to access it.
But I really don’t need a full scan. It’s enough to have a log of a couple of files that got automatched against standalone recording only.
When you thanked me for the LOG, I thought you saved it on your hard drive.
I kept it on Google Drive for 5 days. Then I deleted it because no one knows who will download it. ![]()
How many files are enough for the LOG. 10?
Sorry for that. I had previously answered from my phone, and that had refused to download the log.
But I have now looked into the log and debugged the behavior. The result is rather interesting:
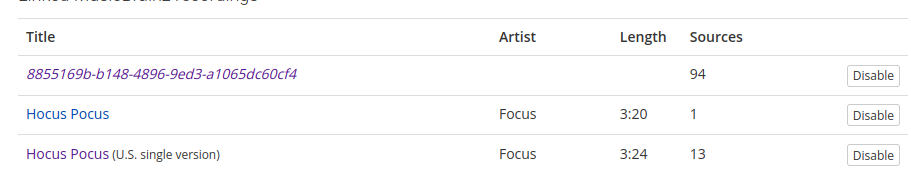
Nearly all of the found AcoustIDs contain a single MusicBrainz recording that has a very high number of submission, but which no longer exists as it got merged into another recording. Track "38338eff-b530-498c-a2ef-07e01d642187" | AcoustID is a good example:
The first track ID 8855169b-b148-4896-9ed3-a1065dc60cf4 has the most submissions (94), but the recording itself on MB got merged into Hocus Pocus (U.S. single version).
It was recently already noticed in Why does acoustID sometimes not show merged recordings? that AcoustId currently does not deal well with merges. Instead of also merging the recordings on the AcoustId side they just end up as essentially dead links. Not sure if this is currently by design or a bug, @lukz might be able to say more about this.
But it is also Picard who has some trouble making sense of the data. There are two issues:
Picard considers the submission count, relative to the highest submission. In cases where there is a recording with a significantly higher score this gets a much better ranking. This makes it prefer the recording with the high submission count even if it has no metadata associated.
There seems to be a general, unintentional bias towards recordings without releases. The reason is, that if there is no recording the entire similarity check for recordings gets skipped. But as similarities get multiplied and you usually never get a 100% score additional release comparison lowers the result compared to no release at all.
It definitely should be the other way around: matches with releases should be preferred. Also a recording MBID without any metadata definitely also should get a lesser match then one with well matching metadata. I’ll add a ticket and see we can get a fix out for a 2.10.1 release.
I shouldn’t, but I’m glad. ![]()
Because this problem is not an anomaly that cannot be explained.
There is a cause, there is an effect.
I find it interesting because the matching issues in Picard are real and definitely should be fixed. But they weren’t noticed that much in the past as recording MBIDs without releases are rare.
And the issues with how Picard gets confused by recording MBIDs in AcoustID that have no metadata attached were known. But again this didn’t happen that often, as it only is supposed to happen for a short time after adding new recordings until AcoustID syncs the database again.
But since some while AcoustID’s code that handles recording merges seems to be broken. That means many orphaned recording IDs have piled up. That’s also the reason why you see this decline of match quality compared to your previous runs.
I have also filed a bug report for AcoustID at MBID recording merges are not applied · Issue #114 · acoustid/acoustid-server · GitHub . I hope this gets fixed there as well.
I know. I read. I’ve added it to my bookmarks.
For reference, this is tracked at [PICARD-2792] Unlinked AcoustID results are preferred over results with metadata - MetaBrainz JIRA
I’ll see that we get this fixed soon and make it part of Picard 2.10.1
Thank you very much Philipp.
In short thanx. ![]()
The situation is getting worse. ![]()
There were 357 standalone files, there are 471.