I’m busy working through some scripted tag standardisation/ enrichment to get the most out of my music when interacting with it though music servers.
Looking at musicbrainz_trackid I was hoping to clarify whether it’s unique to a particular artist performing a track or unique to the track regardless of performer (i.e. it identifies the composition)? The answer to this will determine the enrichment strategy deployed in respect of musicbrainz_trackid in the database I use for standardisation/ enrichment before writing out changes to underlying file tags.
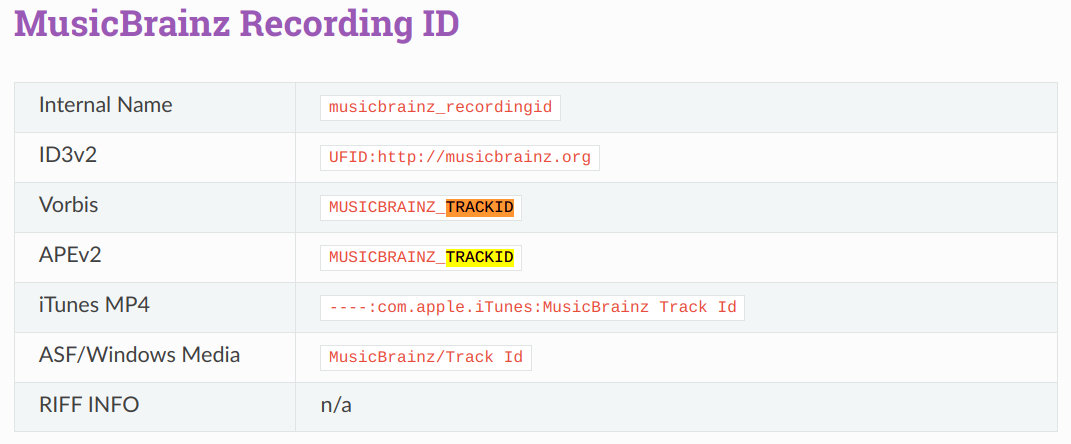
What is saved as musicbrainz_trackid is called nowadays %musicbrainz_recordingid% inside Picard (see the tag mapping docs for full information how this gets stored in the various file formats). It contains the MBID of the Recording.
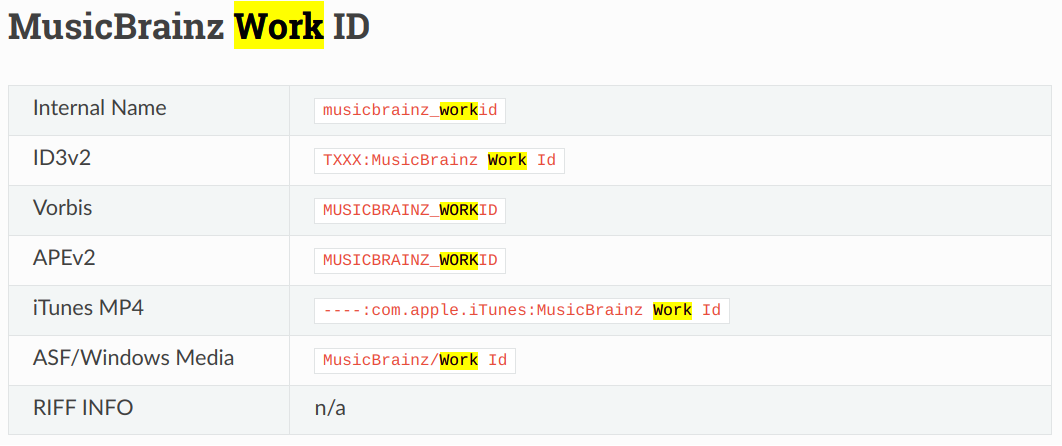
What you call the composition would be the Work. The work ID gets stored as musicbrainz_workid.
Thanks. I’m aware of the mapping docs you linked. Is there documentation that unpacks the meaning behind each of these as they’re rather obscure.
MB’s data model has some idiosyncrasies I’d love to better understand so I know how best to leverage its identifiers e.g.:
The ‘Internal Name’ provided in the link you referenced - that pertain to the musicbrainz database schema or some Picard internal?
musicbrainz_workid - does it relate to all compositions or supposed to be classical only?
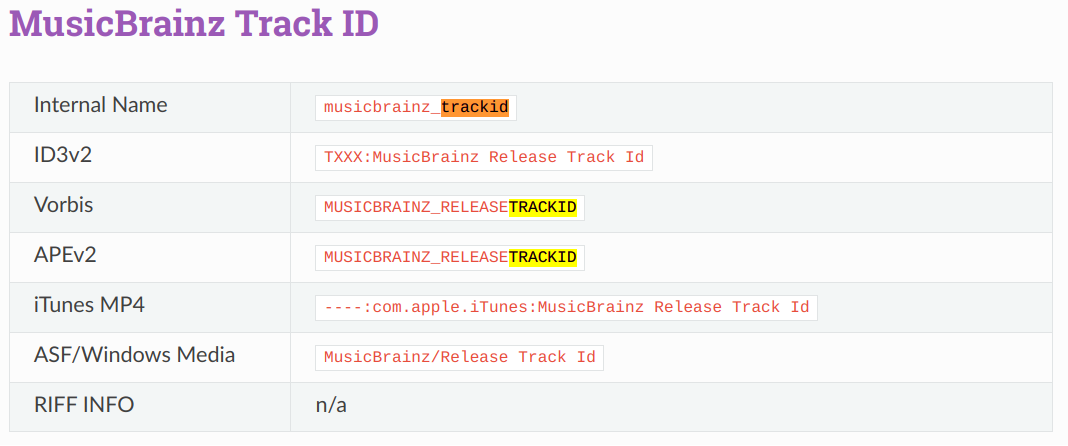
MUSICBRAINZ_TRACKID vs MUSICBRAINZ_RELEASETRACKID - what’s the distinction between the two?
MUSICBRAINZ_TRACKID maps internally to musicbrainz_recordingid; MUSICBRAINZ_RELEASETRACKID maps internally to musicbrainz_trackid. Could it be any more confusing?
And if WORKID is how compositions should be identified why does Picard not write it for popular music? Here’s a freshly tagged file from Fleetwood Mac - Rumours:
In the greater scheme of things what I’m wanting to achieve is the following:
All individuals in artist, albumartist or performer have a UUID attached that enable disambiguation throughout my music collection
for non-classical music: all songs/compositions/works/tracks or whatever MB chooses to call them they have a UUID that identifies that song, regardless of who is performing it. That enables me to answer questions like show me all performances of the song ‘Jersey Girl’ composed by ‘Tom Waits’ regardless of who the performer is.
for non-classical music: enable all composers/lyricists/writers (for my purposes conflating all to the composer tag is sufficient) to have a UUID that enables me to identify all compositions (i.e. tracks/songs/works) that a person has had a hand in.
For classical and non-classical Enable me to be able to browse my collection by Composition (I guess 5. below is the same thing where Classical music is concerned)
For classical , allow me to identify all instances of a Work or a Part in my library, regardless of who’s performing and regardless of who’s conducting
I realise that the above takes a music server that’s aware of these constructs - but it begins with having the metadata to leverage in the first instance.
It’s how Picard names this tag. You use that name for example in scripting (by using the %musicbrainz_recordingid variable) or when manually adding a new tag.
In general all recordings can have works. E.g. look at the work for Bob Dylan’s All Along the Watchtower. If a recording is linked to a work Picard will add the work ID to the tags by default. It also stores the work name.
There is some debate around this as some users would only like to store the work name in the tags for classical music. The “Work & Movement” plugin will hence clear the work related tags for works it does not consider works consisting of multiple parts, as it is typical for classical.
MUSICBRAINZ_TRACKID is the recording ID. MUSICBRAINZ_RELEASETRACKID is an ID for a specific track on a release. I once even saw a rare case where the same recording was included twice on a release (it was some multi-disc release). Both tracks would then have the same recording ID, but different track IDs.
It does unless you have configured it not to do so, e.g. by unsetting the work tags with scripting or using the “Work & Movement” plugin.
This needs a bit more explanation. First of all: The internal names of Picard and MP3Tag are really only names for the respective software. And they don’t have to match. The important thing is, which tags they fill. And so we have the following mapping:
Picard
MP3Tag
ID3
MP4
Vorbis
musicbrainz_recordingid
MUSICBRAINZ_TRACKID
UFID:http://musicbrainz.org
----:com.apple.iTunes:MusicBrainz Track Id
MUSICBRAINZ_TRACKID
musicbrainz_trackid
MUSICBRAINZ_RELEASETRACKID
TXXX:MusicBrainz Release Track Id
----:com.apple.iTunes:MusicBrainz Release Track Id
MUSICBRAINZ_RELEASETRACKID
So there is a consistent mapping, only the internal names are a bit confusing and somehow twisted. This has historical reasons.
In the distant past, when metadata was wild and chaotic, MusicBrainz had a simplified scheme: there were Releases, and Releases had Tracks. A track had an MBID, the MusicBrainz Track ID. If the same recording of a song appeared on another release, it was still a different track, with a different ID. In Picard, the tag was called musicbrainz_trackid, with the mapping to UFID and MUSICBRAINZ_TRACKID.
Then in 2011 came the MusicBrainz NGS (Next Generation Scheme), which fundamentally expanded the data model (essentially, it is the data model that still exists today). One of the changes was that there was now the concept of Recordings. A Recording is a recording of a piece of music, and the same Recording can be linked to tracks from different releases. However, since it was not reliably possible to automatically group the existing tracks into Recordings, when migrating to the NGS, each former Track became a Recording, while keeping the IDs. I.e. the former track IDs eventually became recording IDs. Important: In this model there were initially no more Track IDs!
In Picard, however, nothing changed at first. Internally the tag was still called MUSICBRAINZ_TRACKID and was stored in ID3 as UFID. Keeping the mapping to the tags in the formats was important to keep already tagged files compatible. After all, the IDs were still valid.
However, MusicBrainz then reintroduced track IDs in 2013, meaning that a very specific track (e.g. track 5) on a release got a fixed identifier that was independent of the recording associated with the track.
To distinguish this new track tag in the files, it was stored in the tags as TXXX:MusicBrainz Release Track Id or MUSICBRAINZ_RELEASETRACKID as of Picard 1.3. In order to at least use names within Picard that were consistent with the database schema, the internal name for the old musicbrainz_trackid was changed to musicbrainz_recordingid. However, a new tag internally called musicbrainz_trackid was also introduced, which was then mapped to TXXX:MusicBrainz Release Track Id or MUSICBRAINZ_RELEASETRACKID.
Probably it would have been better to use musicbrainz_releasetrackid here instead, to keep the confusion at least a bit more in check
For MP3Tag I don’t know the history that well, so I can only guess. But it looks like MP3Tag just stayed with the name musicbrainz_trackid for the original tag (pre-NGS “Track ID”, afterwards “Recording ID”). And the new track IDs were then internally named MUSICBRAINZ_RELEASETRACKID.
Turns out I did have that plugin enabled so that Picard would do its thing for Classical music. Never realised that using it means MUSICBRAINZ_WORKID get stripped from non Classical. Crazy that a plugin is allowed to do that without an ability to explicitly enable that behaviour. A classical (sic) example of overreach and scope creep.
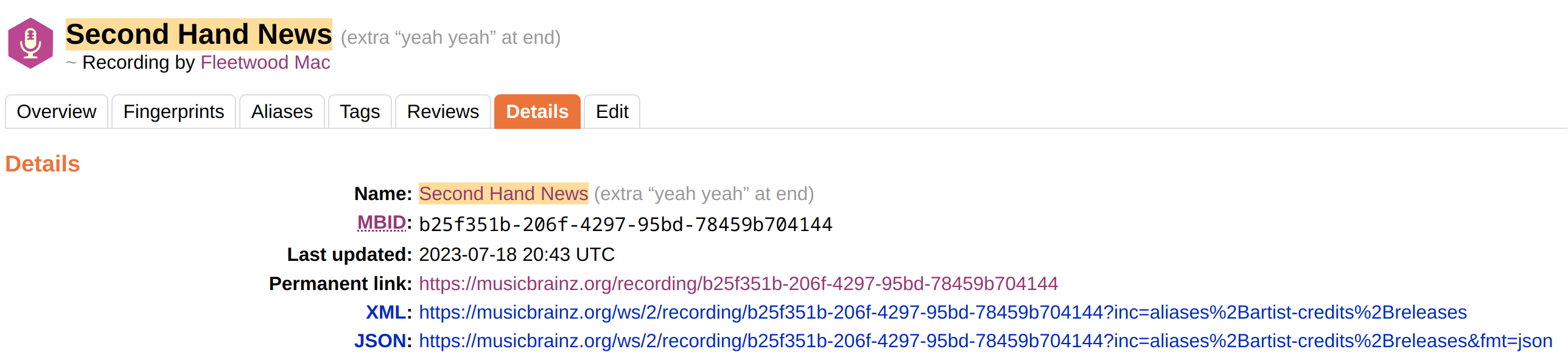
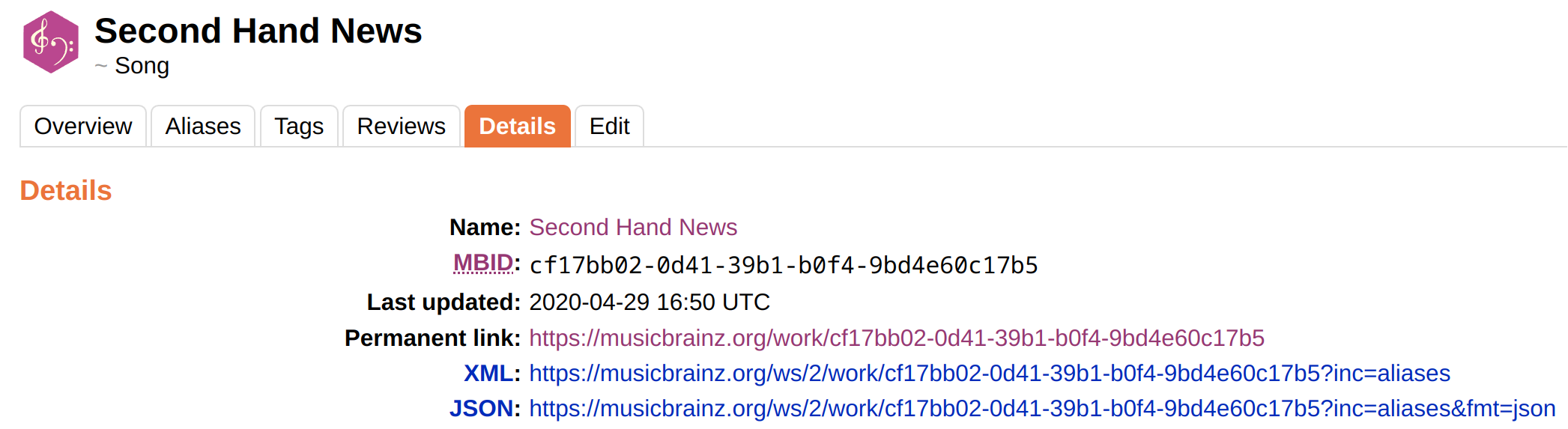
Back to being able to identify a “song” regardless of who performs it. If I look at FM’s Second Hand News:
Per Picard’s tagging I have MUSICBRAINZ_WORKID=cf17bb02-0d41-39b1-b0f4-9bd4e60c17b5 which differes from the MBID of a recording of the work, which in turn differs from the MBID of the “Song”
Which is the MBID I need to write to my files to enable me to pick out all performances of the Song, regardless of who is performing it? If it’s the MBID shown under Song above, can/does Picard pull it or would it be simpler for me to pull it directly from a dump of the MusicBrainz DB?
That plugin was a direct response of the discussion at https://tickets.metabrainz.org/browse/PICARD-1050, where it was requested that Picard actually should never set the work tags unless it is a classical work.
But actually the plugin provides the variables _recording_work and _recording_workid that still holds the data. If you use a script like this it would set the IDs to the tags again:
That is exactly the work ID that is set to musicbrainz_workid (or the variable _recording_workid if you use the Work & Movement plugin). See Song “Second Hand News” - MusicBrainz
Thanks. It’s strange to me that Picard wouldn’t be configured to write these MBIDs by default to enable servers that seek to serve more than a list of Artists & Albums can leverage them for disambiguation and identification purposes. Clearly the concept of compositions or Songs is lost insofar as it might be something people might want to navigate within their music collections.
In any event, I’ll be bypassing Picard and pulling the musicbrainz_workid directly from a download of the musicbrainz database. My tags are good, I definitely won’t be letting Picard or any other tagger loose on them again, at least not on an en-mass basis.
Once I have all the musicbrainz_workid’s added I may be in a position to then further enrich my tagging database by pulling additional metadata directly from a database dump.
Just to avoid any misunderstanding: Picard absolutely does write those tags by default. They only get unset when using the “Work & Movement” plugin, which specifically was created for some users who explicitly requested that Picard should not write those tags unless the work is a complex multi-level work.
So just to clarify one last point then, from an enabling disambiguation and browsing/exploring a music collection MUSICBRAINZ_RELEASEGROUPID and MUSICBRAINZ_TRACKID are of little value other than disambiguating recordings and releases and thus in a typical music server use case have limited utility?
Where these are of use is if you have more than one of something.
Example - I own at least five copies of Dark Side of the Moon from different years. Importantly the MUSICBRAINZ_ALBUMID will keep them as separate albums. (one of the reasons I personally started to use MusicBrainz tags)
The MUSICBRAINZ_RELEASEGROUPID would let me group these four albums together and lookup data common to the albums (like the Wikidata link).
And as those four albums share the same Recordings I can link these with the Recording ID (MUSICBRAINZ_TRACKID) as being the same recordings. Which also lets me spot them on compilations that may use that same recording.
So to the average person they may be less needed… to a collector who may duplicate things in their collection they have some meaning.
Also note that from a RecordingID \ MUSICBRAINZ_TRACKID you can more easily lookup details in the main MB database as to who performers were, where it was recorded, and other details specific to that actual recording. For that reason alone I would store it in my own media centre database.
In addition to what have been said above, there are several ways how the recording ID is actively used. Two interesting use cases:
Picard uses the release and recording IDs from the tags to automatically load the corresponding release. This makes it easy to update tags in previously tagged files.
If you submit the music you are listening to to services like ListenBrainz or last.fm the recording ID can be submitted. It allows those services to properly identify the recording associated with the file you listened to. Many players or player plugins submitting to a listening service make use of the recording ID.
Is MUSICBRAINZ_RELEASEGROUPID exposed anywhere when browsing any of the releases - it doesn’t seem to be displayed when browsing and I kinda understand it’s not a meaningful datapoint to a person when browsing?
It would be really useful I think if Musicbrainz documentation included a short description of the meaning and purpose of each of the following as it’d go a long way to improving how apps leverage MusicBrainz. I see many of the links resolve to the same generic information whilst others don’t even have links.
I’m aware of two music servers that recently tried to tackle handling of different releases of albums and came up with all sorts of contrived solutions involving user specified fields, hash strings involving folder path etc. Turns out all that the long term solution would be to ask users to tag using Picard and then have the apps leverage MUSICBRAINZ_ALBUMID to stop conflating them whilst using MUSICBRAINZ_RELEASEGROUPID if they chose not to show each release alongside the next in a first order album browse.
Thanks, that’s also useful info to know. Is there perhaps a way to limit Picard’s tag editing to retrieving only those identifiers whilst leaving other metadata untouched?
At present I’m contemplating the viability of matching track titles from my metadata database to work titles in the musicbrainz work table. Without the track id its highly likely that a lot of conflation of works will be the end result.
But yes, maybe we could link those MBID tags in the Picard docs to the respective entity documentation instead of the documentation of MBIDs. On the other hand the documentation for MusicBrainz Identifier also links to the individual documentation of each entity and additionally explains how an MBID is structured and used.
That’s exactly what several players do, e.g. the Lollypop player for Linux or the Funkwhale audio server.
Picard is not really meant for updating only a few tags from MB. But it is possible by unsetting tags you don’t care about with scripting, adding tags that should not be changed (but can be set if they don’t exist) to the preserved tags list in options or by using the “keep” plugin.
There are several threads about this in the forums.
Honestly, as an outsider looking in the documentation is useful, but it doesn’t make it simple to understand where/how those particular MBIDs are used and what they signify, and I’ve looked at the documentation previously as well as taken a quick gander through the links you’ve just posted above. Unless I missed it, nowhere is there a page that states clearly the meaning of each of these identifiers:
(most link back to the generic MusicBrainz Identifier - MusicBrainz page) and nowhere is there a page that maps these identifiers to the database schema. It’s second nature to those that work with it everyday (because it has to be), but it’s a minefield coming in cold.
Having the identifier, its purpose and its mapping to the database schema would hugely simplify understanding for folk that don’t understand the innards of Picard or the MusicBrainz database schema.
MBIDs are also assigned to Tracks, though tracks do not share many other properties of entities.
Tracks are really a special case, as they are not much of an actual entity on their own. I mean mediums on a release can have several tracks of course, but apart from that they don’t represent much themselves.