Discussion and support thread for my new userscript:
MusicBrainz: Parse Copyright Notice
Extracts all copyright and legal information from the given text.
Automates the process of creating release-label relationships for these.
Also creates phonographic copyright relationships for all selected recordings (userscript only).
Detects artists who own the copyright of their own release and adds artist relationships for these (userscript only).
Caches name to MBID mappings, so you don’t have to select the same label or artist twice.
I have also created a GitHub wiki page for this userscript to collect different copyright notice formats. @tigerman325 has been a great help with testing and finding these so far. You can also help by testing the userscript and discussing features on GitHub and in this topic.
You can do that, just typing (C) 2021 Labelname should already save you a bit of time (add relationship dialog opens automatically, selects the correct relationship type, fills in the date and triggers the auto-complete for the label).
But the primary use case is to paste copyright notices which you can find on other websites and which a-tisket lazily adds to the release annotation.
That’s actually one of my dream goals, to combine the credit parser and importer scripts with OCR to get the data out of the CAA:
Will (P)(C)2021 labelname be clever enough to add both in one go? That would have me jumping in an using this on CDs. I don’t use Tisket as I generally avoid digital media outside of Bandcamp.
But if you are doing something to get rid of those annoying blocks of text - well done!!
I have recently started to write a bit of documentation for this userscript as the code quickly became more complicated than I initially expected it to, thanks to the reports and suggestions of @tigerman325 and @vzell.
You can find it on a GitHub wiki page – feedback, corrections and improvements welcome (you should be able to directly edit it with a GitHub account):
I also wanted to take the opportunity to share this beautiful railroad diagram of the underlying regular expressions, which are used to parse the copyright notices, with you:
I would be very interested to know if this is also helpful for people without a coding background to understand what kind of text the copyright parser supports.
I’ve found an issue with the script.
If I swap the entity type manually while parsing a copyright notice using the script, it will give me results but I won’t be able to submit them. Clicking the “enter edit” button after this leads nowhere (it will act as if it’s submitting the edits and then stop).
Sorry, but I can’t reproduce this. I did a quick test with “(P) Test Artist”, clicked “Parse copyright notice”, changed the entity type from Label to Artist, selected the correct rel type again, searched and selected the MB test artist, confirmed the dialog with “Done” and hit “Enter edit”.
Although this is not the intended way to use the parser, it works for me (on the test server).
If you want to force an artist search instead of a label search, you can hold SHIFT while clicking “Parse copyright notice”.
If you did something else which did not work, I need more details (description or screenshot of what you did). Is there an error message on the page or in the browser console when you click “Enter edit”?
Apparently the userscript works reliably now as I haven’t received any improvement suggestions during the last months
Although there aren’t any new features in the classical sense, I’ve finally released a new version today which also supports the new React relationship editor (currently in beta).
So if there are any MBS beta testers among you which had to avoid the beta relationship editor because of all the broken userscripts, here’s at least one userscript that’s working again. (Another one is my Voice Actor Credits script which is using the same codebase.)
Indeed, I can reproduce this bug which affects both the copyright and the voice actor credit parser userscript. Thank you for reporting!
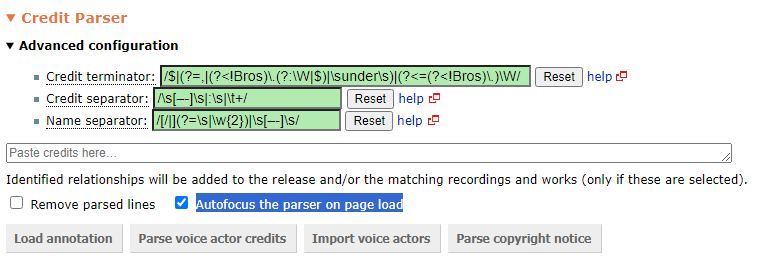
This used to work in the past, but now there seems to be a timing issue: The previous value of the checkbox had not been restored by the time the check for its state is performed.
I did not have the autofocus checkbox enabled recently, so I don’t know if this has been broken since the last userscript release or whether there was a recent MBS change which slightly changed the timing.
Unfortunately this doesn’t work for Mac users. I tried Control+click and Command+click, but the former only brings up the right-click menu and the latter does nothing.
Oh, I wasn’t aware that Control+click is the same as right click on a Mac.
I think I have added support to alternatively use Command+click but couldn’t test it.
Please install the new version from this development branch and let me know if it works for you, then I can release this version for everyone (it should continue updating to the main version).
Quick query from a new user of the script, sorry if this was asked before in a different thread: is there a good reason why the script uses the year in a copyright notice as an end date as well as a start date? I always assumed the notice meant the company held copyright from that year until some as yet unknown point in the future.