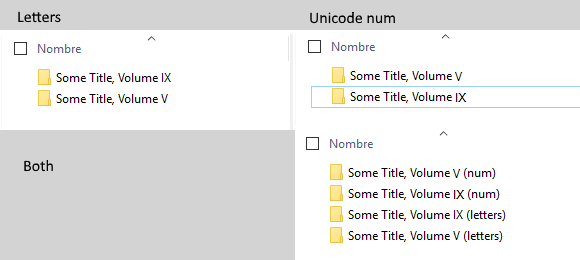
I was wondering If this topic has been discussed (I couldn’t find anything).
I’m aware that the Unicode Consortium discourages the use of this table stating that “For most purposes, it is preferable to compose the Roman numerals from sequences of the appropriate Latin letters”. I fail to see the reasoning behind that recomendation, and none is provided by them. But it is fact that has to be considered.
I do see various advantages in using them, and since they can be handled the same as other unicode characters (using search equivalents, and converted using the “Convert Unicode punctuation characters to ASCII” in Picard), no disadvantages. Here are some of the advantages.
-
They are logically considered numerical values, and as so, machines can understand unequivocally their meaning and value.
-
They are displayed more consistently and with better typographic handling (kerning, height (taller than samall‐caps, shorter than capital letters, mostly)) by fonts that support them (of which are plenty).
-
They can be correctly ordered alphabetically (e.g.: Ⅴ appears before Ⅸ, whereas IX appears before V).
I don’t know whether the server accept this substitution automatically (as it does for capitalization or " → “, etc), but an official stance in favor would mean it should; or one against, would mean to add a clarification note in the styleguide, I suppouse.