In it @rob, the scalliwag, has outlined how to use our new MusicBrainz Canonical Metadata dataset (link to dataset announcement) to write a semi-automated tagger in Python. It only has three steps!? That seems too few… ah well, I’m sure he knows what he’s doing. Anyway, if this is something you’re interested in, check it out, or give it a share to people who may be interested. With everywhere locking down on API usage lately it’s pretty cool to be releasing more open resources.
Also, just for the forums, a big pat on the back to the team that refreshed the MetaBrainz datasets pages, they’re now really clearly formatted, have an inviting button and info hierarchy, and there’s a new sign-up workflow! Really nice job.
And thanks to @lucifer, @reosarevok and @mr_monkey for all the hard work that went into creating the dataset and all the work around the new data-set pages. Thank you!
I think there’s a tiny typo in this code snippet from step 3 – the parameter is named artist_name, but it’s referenced as artist_credit_name in the body:
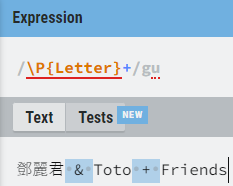
And just to mention it, it sounds from the docs like the \w here may preserve underscores. I’m not sure if that was the intent. \W may be clearer than a negated \w, too.
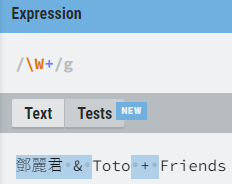
![[^]+](https://community.metabrainz.org/uploads/default/original/3X/d/2/d24207fb92340a11a8f4723aa90311e609e0d271.png)