Just wondering, is everything looking alright on MusicBrainz’s Google Search Console and sitemaps and such get refreshed in reasonable timeframes?
I’m asking this because even when specifically searching for artists on Google I really haven’t noticed any MusicBrainz results, which is IMHO strange because MusicBrainz is a good source of information in many cases.
This is definitively an issue, I’m doing a lot of searches for artists and can confirm sites like discogs, allmusic, and metalarchives often appear on 1st google results page, and MB is perfectly invisible even when it’s the sole site of this kind having infos about an artist.
Sitemaps are submitted, googlebot is crawling, but it seems to me there’s an issue. We know the site is likely to be ranked down because it isn’t mobile compatible (but devs are working on react move, that should let us to fix that in near future).
But still my feeling is that something is wrong, because searching for a not very popular band which is in MB since years still doesn’t yield to results.
https://duckduckgo.com/?q=onmyo-za “nowhere” with Latin alias (I think we should add all aliases in keywords in meta tags of the artist page, same for works, etc.)
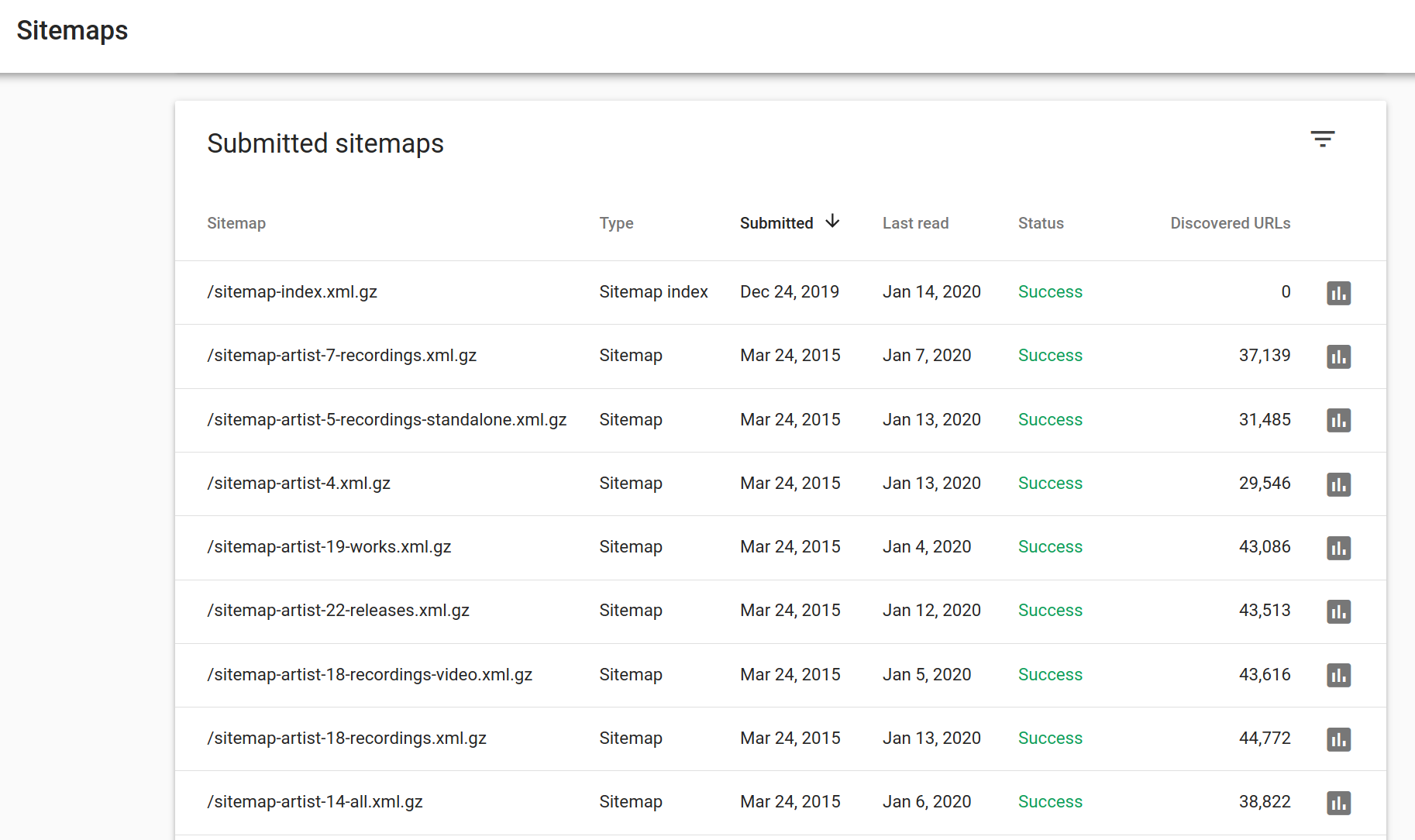
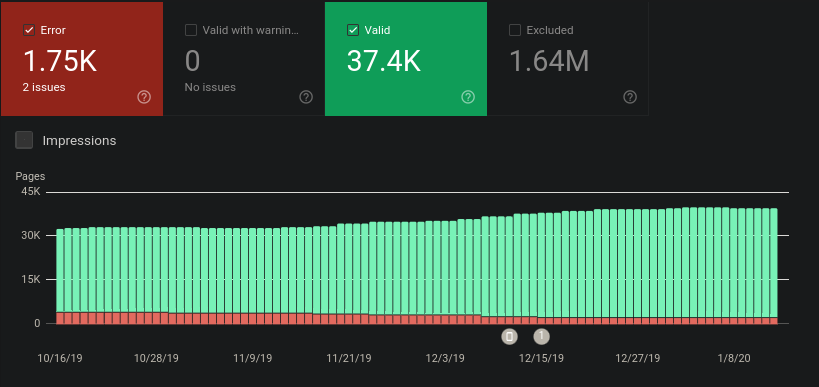
If it’s not a secret, what does the “Coverage” page on search console show? And does the “Sitemap” page show the sitemap list and all the sitemaps?
I had trouble Google ignoring my sitemap list (the sitemaps in it weren’t listed and crawled) and had to make a script to submit every index page into the sitemap list, maybe this is the case here too?
What does it say as the explanation for the excluded pages? (“Crawled but not indexed”?) Just wondering also if there are any missing sitemaps or sitemaps that haven’t been read for years as well?
I tried a lot of things, noticed that the only noticeably working “cure” was to reduce the amount of errors, for every fixed error page Google seems to be willing to index tens if not hundreds more pages. My hunch is that Googlebot crawls one site until it encounters an error and then it enters some massive cooldown period, skips the broken page sometimes and continues.
This sounds a bit suspicious, especially in this amount, is this intentional or has Google missed a bunch of sitemaps?
In the sitemaps, we actually only list pages that have embedded JSON-LD markup, to ensure those are fully ingested by Google (we even supply hourly, incremental sitemap updates to them). The only reason we have sitemaps to begin with is because they contracted us to embed semantic markup (JSON-LD) in our pages, and needed a way for us to ping them when any of the markup changed.
So I’m not surprised if it says a ton of pages aren’t in the sitemaps.
200k page is a lot, what does it count as a duplicate? Is the canonical URL configuration correct?
The “issue” is that ?va=0 is sometimes not a noop, so it does sometimes affect page content. Maybe the solution would be to not include that link for artists where it wouldn’t display/change anything? Edit: The problem with that solution would then be that users wouldn’t be “trained” to having it be there, which might (or might not!) be UX issue. Whatever we do, it’s always a compromise…
This seems like a fair compromise? IMHO the lack of visibility on search engines seems a bit worse than not having users being trained to have the parameter there.
The thing is that Googlebot is fairly active, it’s crawling our websites almost permanently, so no, Googlebot (but also BingBot and others) are activily crawling.
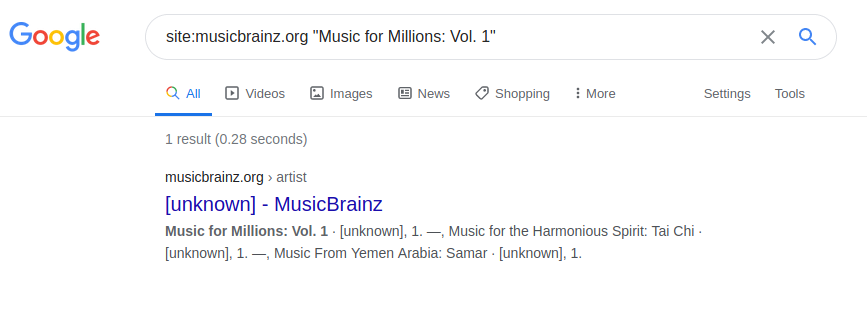
But we still don’t appear in results, even for entities being in the database since years.
It appears on second page for me, when searching on title.
I think what is a big factor is the fact most pages have no original textual content, we have mostly links to external resources, and bits of data, titles with only few words (tracklist), birth date, etc… for most bots I think our pages look “empty”. Also since they are text-empty, short excerpts shown are rather unattractive, not sure many people select them.
We don’t provide audio player, or ways to buy the actual music either, biographies shown are coming from Wikipedia mostly, and reviews are done elsewhere (CritiqueBrainz).
We don’t even have cover art and/or artists photos and/or label imprint images shown by default (or not at all). Also we have good quality data, but we lack quantity (if one wants to know all LP releases of one album he has better chance on discogs, plus he would be able to buy one directly from there).
And MusicBrainz website isn’t really mobile-compatible yet (this doesn’t help).
In short, I think our bad ranking is more due to the very nature of MusicBrainz, rather than the lack of indexation.