I don’t want to overload the MB server with my Picard attempts, so I’ll ask.
I’m only interested in the Artist and Title fields in ID3tag.
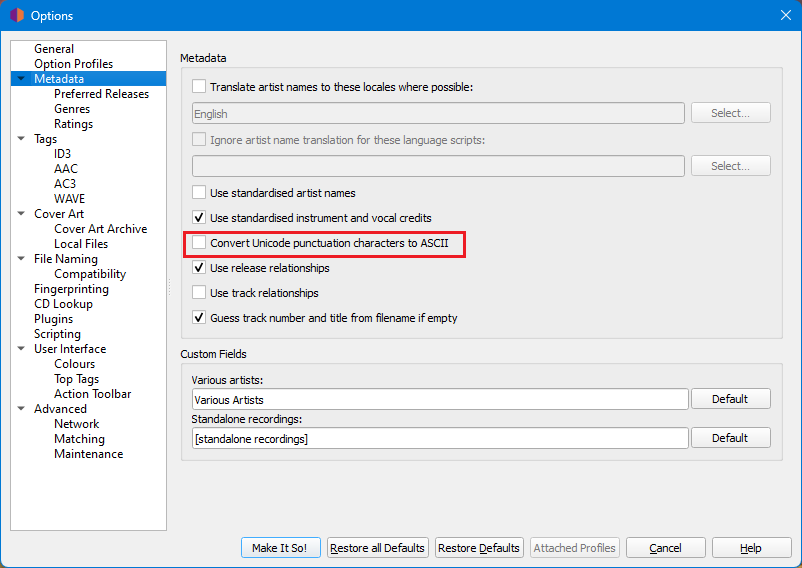
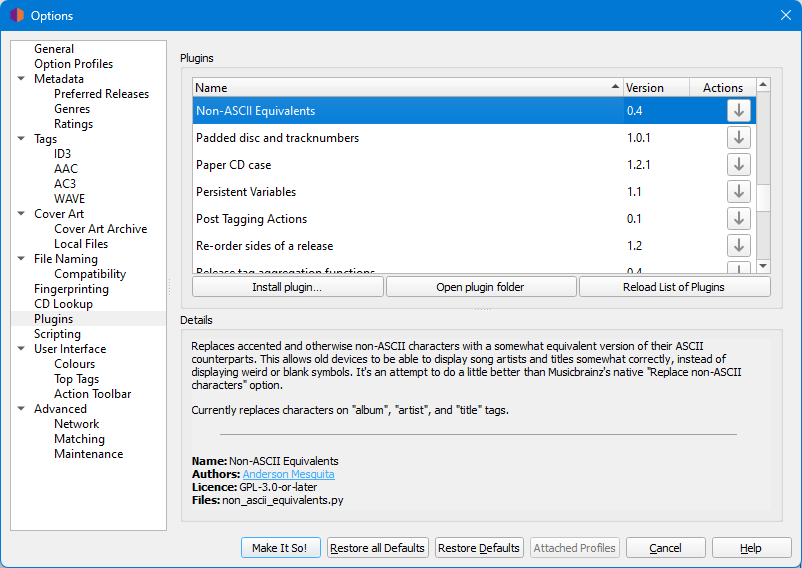
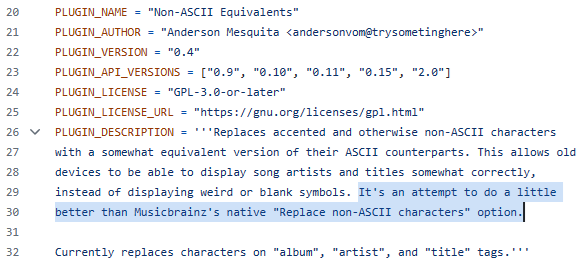
I would like Picard to fill in these two fields or all of them (there may be an easier solution) with only English letters, without French or Polish diacritics.
For example two songs:
St. Germain - Prélusion
Sven Väth - Sensual Enjoyments
Result achieved:
St. Germain - Prelusion
Sven Vath - Sensual Enjoyments