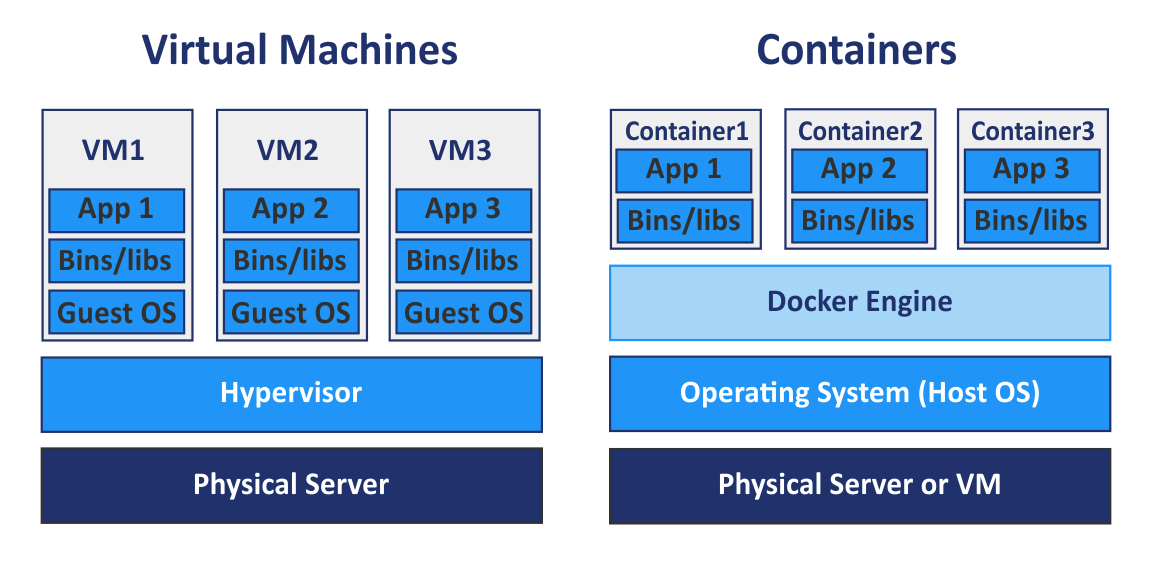
I read about the possibility to setup your own local MusiBrainz server.
It might be an interesting thing for me to try, but…
While I am savvy with Windows, my experience with- and talent for Linux is less then mediocre.
In the past I have build a nas-server running on NAS4Free (freebsd based), and I managed to keep it running and updated for many years, but using ssh, console and related Linux commands where a big challenge and a kind of self-torture for me.
(I abandoned it after a while and am now using a Windows Server nas)
So, my question is this:
For as far as I understand after a quick-read, I could setup a Windows pc for the task, use VirtualBox , and then load some sort of a largely pre-configured MB database image?
Considering my above admittance of being terrible with Linux, and usually only succeeding after lots of help from experienced users that are willing and able to give some sort of spoon-feeding support, would it be better for me to just forget about even trying this, or is it not that difficult and would I have a chance in getting it to work?