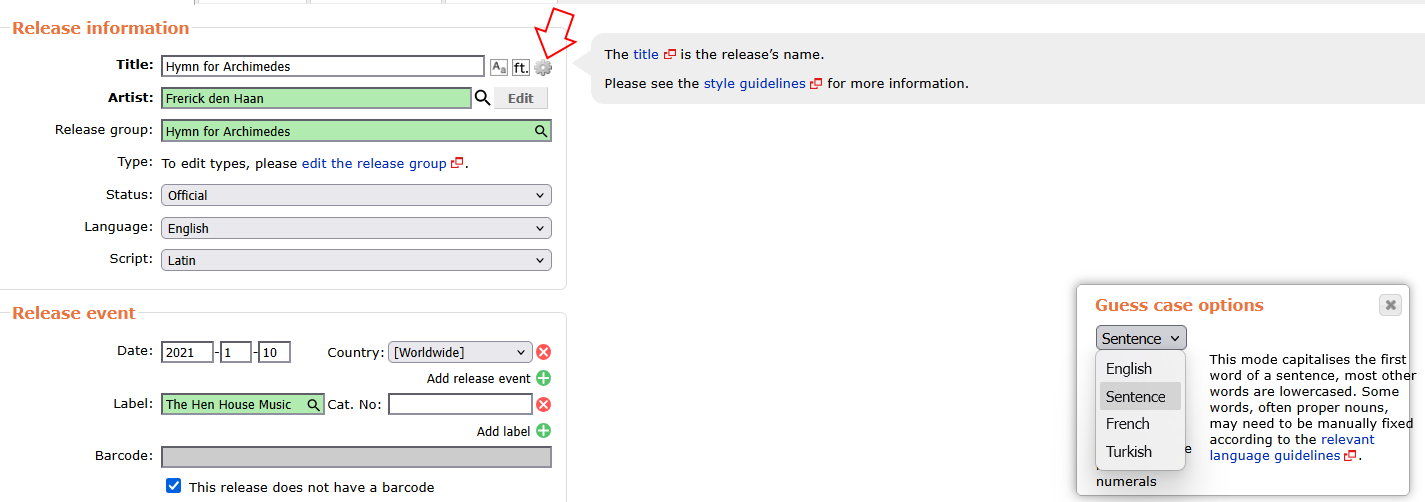
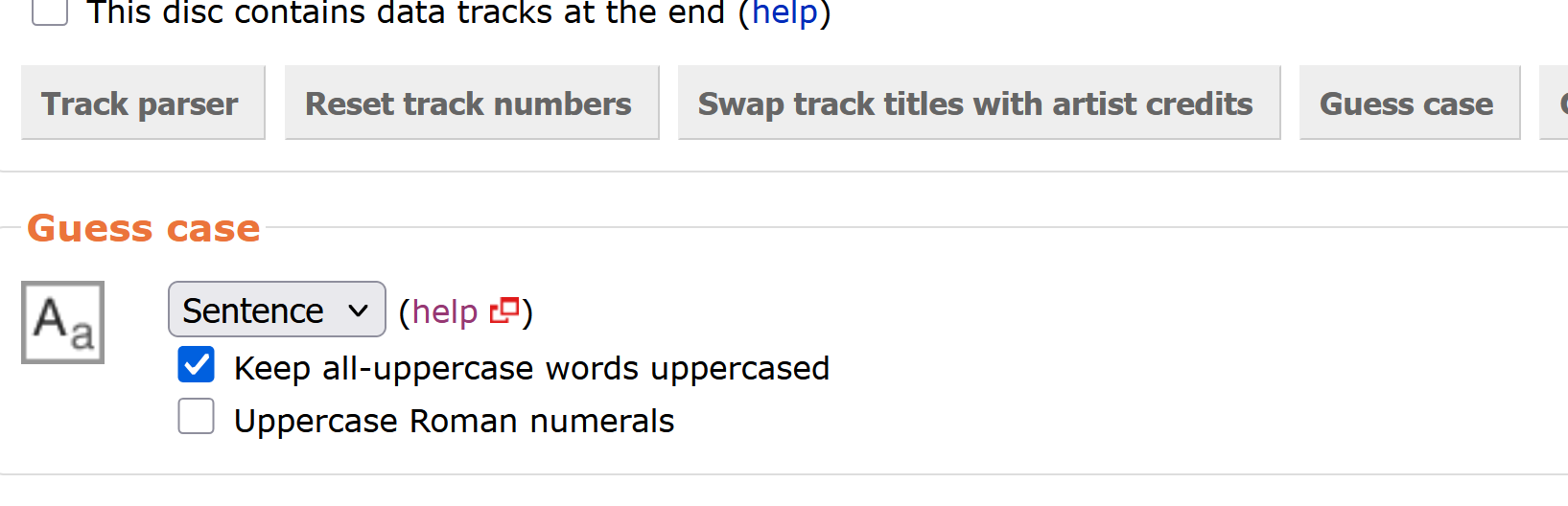
Sounds like you should use “Sentence case” for guess case. Click on the gear icon (red arrow) and change guess case options from “English” to “Sentence”:
That might be possible, but I don’t think it would be very easy. It would need to know the language (not just script) of each title and apply the right guess case algorithm for each. For Russian and English it looks like it’s easy because of the different scripts, but if the release actually has a mix of Russian and Spanish, then that would be different. Also, there are probably always going to be cases when the guess case algorithm doesn’t work even within a title, like if a track title is “English Title / Nederlandse titel”.
I wonder if a feature request to split the guess case button out into one button per algorithm would be better? Then you could click “guess English case” or “guess sentence case” for each track without needing to change the selection box each time. And maybe support cursor selection, so you could select part of a title and click the button to only guess the case for that part? Dunno how easy that would be or how cluttered the UI would get, just an idea.
I bet this doesn’t happen often. And how would you fix it? You would need to recognize language in general. Fix can be made out of MusizBrainz anyway via script of any kind. In general case just copy/paste to AI and you are good, its perfect for this case.
Guess case literally does what it says: guessing
It’s based on regular expressions and not ideal for grammar. Otherwise the function would be named “fix case”
I’d also suggest to try copying the tracklist from the tracklist parser into a proper spell checker or only apply for individual tracks:
Idk the logic of the current “Guess Case” script, and I’m not much of a coder myself.
First of all, there is some symbol recognition in place, since the script can’t be applied to hiragana, for example. But if I were to implement logic similar to this:
Check: If the sentence is Latin, then implement current rules.
Check: If the sentence is Cyrillic, then apply: the first word starts with a capital letter.
This alone will cover all Cyrillic languages. And some ultra specific cases with mixed-up letters (in the same sentence) are an absolute minority and can be covered with manual editing.
No, language detection will always have flaws and would have a high cost of additional maintenance.
We know what language we want.
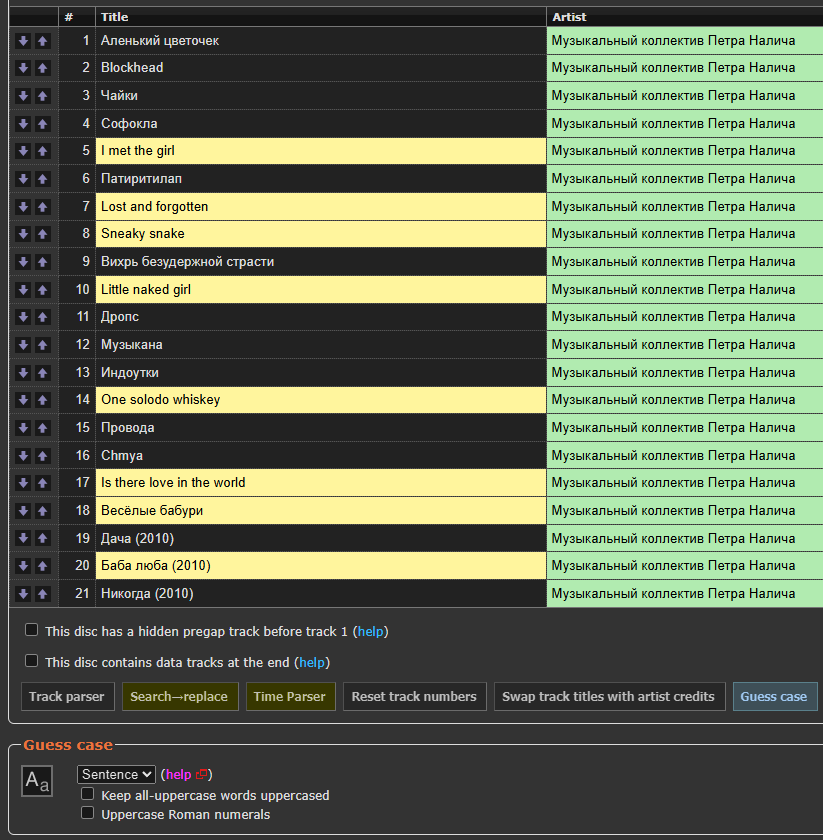
Select a language shared by most tracks then Guess Case.
Then select the minority language then use reach track Guess Case Aa button.
Guess Case button is already a burden to maintain, with all possible exceptions.