[UPDATE: March 23] I have heavily revised this proposal for my official GSoC submission. I updated the database architecture, added detailed execution flowcharts, and refined the UI mockups based on community guidelines. I would love any final feedback from the team!

ListenBrainz: Playlists Sorting and Organization
Contact Information
Name: Akshay Jaiswal
Nickname: @Akkii05jaiswal
IRC / Matrix handle: @akkii_jaiswal:matrix.org
Email: jaiswalakshay2709@gmail.com
GitHub: https://github.com/Akki-jaiswal
LinkedIn: www.linkedin.com/in/akkii-jaiswal
Proposed Project
ListenBrainz users rely heavily on playlists, but the current infrastructure lacks robust personal organization and dynamic sorting. My project addresses four main deliverables:
-
Implementing a personal labeling/folder system (LB-1302).
-
Allowing dynamic track sorting within playlists (LB-1374).
-
Enabling personal playlist search.
-
Integrating MusicBrainz collections as read-only playlists (LB-961).
Part A: Playlist Organizing (LB-1302)
A naive approach would be to create a playlist_tag mapping table linking a tag_name to a playlist_id. However, because playlists can be collaborative, labels need to be personal to the user viewing them, not globally applied.
Proposed Database Schema: I will create a new table via migration that ties the label to both the playlist and the specific user.
CREATE TABLE playlist.user_playlist_label (
id SERIAL PRIMARY KEY,
playlist_id INT NOT NULL REFERENCES playlist.playlist(id) ON DELETE CASCADE,
user_id INT NOT NULL REFERENCES public.user(id) ON DELETE CASCADE,
label_name TEXT NOT NULL,
created TIMESTAMP WITH TIME ZONE DEFAULT NOW() NOT NULL,
UNIQUE (playlist_id, user_id, label_name)
);
The UNIQUE constraint ensures a user cannot apply the exact same label to the same playlist twice, silently ignoring duplicate requests at the DB level.
Backend Python API:
I will add endpoints in webserver/views/playlist_api.py to handle CRUD operations for labels, verifying the user_id via the validate_auth_header() function before execution.
*# pseudocode for adding a personal label*
def add_label_to_playlist(db_conn, playlist_mbid, user_id, label_name):
playlist_id = db_playlist.get_id_from_mbid(db_conn,
playlist_mbid)
Frontend (React) UI Additions:
For the UI, I will implement the “Gmail-style” sidebar mockups to filter playlists by label_name, and render pill-shaped label tags on the PlaylistCard components.
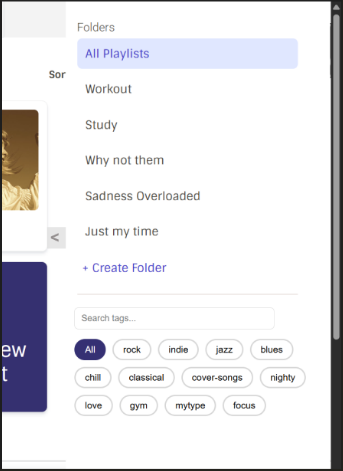
(Figure: High-fidelity mockups of the sidebar and tags are actively attached and discussed in my MetaBrainz Community Forum post under the gsoc-applications tag*.)*

This will include:
-
A sidebar component to filter playlists by label_name.
-
Pill-shaped label tags rendered on the PlaylistCard components.

Part B: Playlist Ordering (LB-1374)
I will implement a dynamic client-side sorting dropdown (Title, Artist, Date). Once the user previews the new order in the React UI, they can click ‘Save’, which will trigger a POST /playlist//item/reorder request to update the playlist_recording.position values in the PostgreSQL backend.
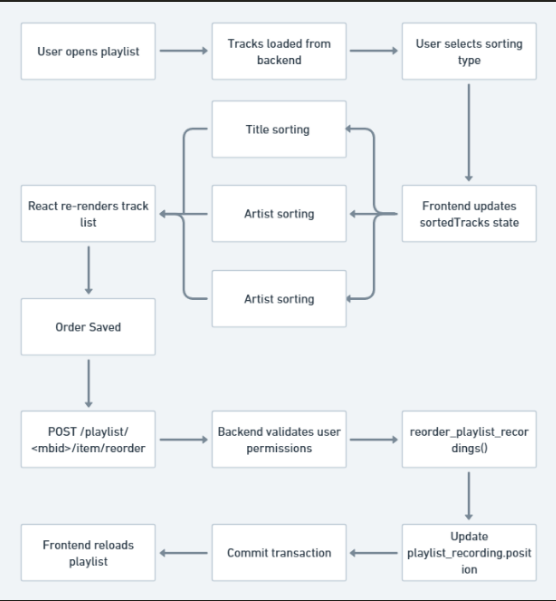
Backend Modification:
# webserver/views/playlist_api.py
def get_playlist(playlist_mbid):
sort_by = request.args.get('sort', 'position')
# Valid options: 'position', 'created', 'title', 'artist', 'random'
# Pass sort_by to db_playlist.get_by_mbid
to dynamically alter the ORDER BY clause
Frontend Implementation:
In the React frontend, a new dropdown component will trigger a refetch of the playlist data with the selected query parameter, updating the PlaylistItemCard renders without a full page reload.

Part C: Personal Playlist Search
I will append a ?scope=personal parameter to the /search API to restrict results to the user’s library. This enables users to efficiently search strictly within their own saved playlists.

Figure : Frontend UI mockup for the personal playlist search. The dropdown integrates with the labeling system (Part A), allowing users to granularly scope their search queries by specific playlist names or custom-assigned folders/labels.

Figure : Detailed technical flowchart illustrating the full-stack execution flow of the proposed personal playlist search feature. It details the complete request lifecycle: (1) React frontend logic, including user input and 300ms debouncing, (2) Python API endpoint validation and user authentication check to determine viewer_id, and (3) PostgreSQL backend operations, spanning SQL query construction, similarity scoring and filtering, and final dynamic sorting and pagination before returning results to the frontend for rendering.
Part D: MusicBrainz Collections as Playlists (LB-961)
As outlined in the official ideas list, MusicBrainz collections will be accessible via a separate tab and will not function as standard ListenBrainz playlists. To prevent unauthorized track reorganization, these collections will not be imported into the local playlist database table. Instead, I will map the external MB API data (focusing first on recording collections, then exploring release groups) to the ListenBrainz JSPF format on the fly. This payload will be rendered using the existing React component with a strict canEdit={false} prop to natively disable drag-and-drop sorting, while still building the API hooks necessary to support the requested “add/remove items” functionality directly back to MusicBrainz.
Backend Data Mapping:
# Proposed mapping logic in webserver/views/mb_collection_api.py
def fetch_and_map_mb_collection(collection_mbid: str, user_token: str) -> dict:
# Fetch from external MB API
mb_data = fetch_from_musicbrainz(collection_mbid)
# Map to ListenBrainz JSPF
jspf_payload = {
"playlist": {
"title": mb_data.get('name'),
"track": map_mb_recordings_to_tracks(mb_data.get('recordings', [])),
"extension": {
"[https://musicbrainz.org/doc/jspf](https://musicbrainz.org/doc/jspf)": {
"is_mb_collection": True,
"read_only": True # Security flag
}
}
}
}
return jsonify(jspf_payload)
Frontend (React) Integration:
I will create a new tab for “MB Collections”. When rendering these specific JSPF payloads, I will utilize the existing Playlist.tsx component but pass a strict canEdit={false} prop.
JavaScript
//React implementation ensuring read-only state
<Playlist
playlistData={mappedMBCollection}
canEdit={false}
hideDeleteButtons={true}
/>
This elegant component reuse ensures the UI natively disables drag-and-drop sorting and track deletion without requiring us to build an entirely new “Read-Only Playlist” view from scratch.
(Community Feedback Note: This proposal is currently live on the MetaBrainz Community Forum under the gsoc-applications tag to gather feedback. Additionally, I have engaged with the core team on Jira to investigate related API string limits (LB-1957), successfully coordinating with maintainers to ensure my future database schemas align with their upcoming mapper architecture ).
_______________________________________________________________________________
Timeline
| Week | Hours | Key Deliverables |
|---|---|---|
| Week 1 | 14 hrs | Database Migrations: Implement raw PostgreSQL migration scripts to create the playlist.user_playlist_label table. Add corresponding SQLAlchemy models in db/model/playlist.py and write DB unit tests for UNIQUE constraints. |
| Week 2 | 15 hrs | Backend API (Labels): Build CRUD endpoints in playlist_api.py for adding, deleting, and updating personal labels. Integrate validate_auth_header() for strict security. Write backend API tests. |
| Week 3 | 15 hrs | Frontend UI (Labels): Scaffold the “Gmail-style” React sidebar for label navigation. Create pill-shaped UI tags and integrate them into the existing PlaylistCard components. |
| Week 4 | 15 hrs | Integration: Connect the React sidebar to the new backend APIs. Ensure state updates locally without errors. Submit Pull Request #1 (Playlist Organization). |
| Week 5 | 15 hrs | Backend Sorting: Update GET /<playlist_mbid> endpoint to accept ?sort parameter (title, artist, created, random). Implement the dynamic SQLAlchemy ORDER BY logic. |
| Week 6 | 15 hrs | Frontend Sorting: Build the React dropdown component for sorting. Integrate React Query to trigger refetches of playlist data dynamically without triggering a full page reload. Submit Pull Request #2 (Playlist Ordering). |
| Week 7 | 15 hrs | Personal Search API: Midterm evaluation. Modify the /search API to accept a ?scope=personal parameter. Ensure the backend logic strictly filters results based on the logged-in user’s library. |
| Week 8 | 14 hrs | Frontend Search UI: Connect the frontend search bar to the updated /search API, ensuring clean handling of the new personal scope parameters. Test query latency. |
| Week 9 | 14 hrs | MB Collections API: Write the backend mapping logic in webserver/views/mb_collection_api.py to fetch external MusicBrainz API data and map it on the fly to ListenBrainz’s JSPF format. |
| Week 10 | 14 hrs | Frontend Collections UI: Implement frontend integration for Collections. Reuse the existing <Playlist /> component, passing a strict canEdit={false} prop to ensure read-only status natively. |
| Week 11 | 14 hrs | Testing: Write comprehensive frontend tests using Jest and React Testing Library for all new components (Sidebar, Sorting Dropdown, MB Collections view). Submit Pull Request #3 (Search & MB Collections). |
| Week 12 | 15 hrs | Final Polish: Address any lingering mentor feedback, fix edge-case bugs, polish UI transitions, and write comprehensive API documentation. Prepare and submit final evaluations. |
_______________________________________________________________________________
AI Usage Disclosure:
In accordance with the MetaBrainz guidelines, I want to transparently disclose that I utilize LLM tools as a development aid. Specifically, I use them for document formatting/structuring, correcting grammatical syntax, and as a “rubber duck” for bouncing initial database schema ideas before writing my own migrations. All core project ideation, technical architecture decisions, and final code submissions are entirely my own work, and I fully understand the implementation of all proposed code.
Community Affinities:
Music Tastes (MBIDs):
-
Blinding Lights - The Weeknd (MBID: 0bdaebde-7023-4416-a36c-dfc58eb190ea)
-
Shape of You - Ed Sheeran (MBID: b84ee85f-8d2a-43d9-abfc-f308a0ab6e58)
-
Tum Hi Ho - Arijit Singh (MBID: c3cc20ba-caeb-4589-a292-cc2de00947ba)
What aspects of the projects interest you the most?
I am deeply interested in Data Analytics and integrating machine learning workflows (such as my ongoing focus on MS Azure AI). ListenBrainz’s massive dataset and personal library infrastructure provide the perfect intersection of heavy database architecture and user-facing data visualization. Building robust systems to organize that data is a natural fit for my career trajectory.
Have you ever used Picard or other projects?
I am actively exploring the wider MetaBrainz ecosystem, focusing primarily on ListenBrainz’s scrobbling and playlist architecture to understand how data flows from the player to the backend databases.
Programming Precedents
When did you first start programming?
My formal programming journey began during my Computer Science studies, where I rapidly progressed from basic scripting to developing complex full-stack web applications and APIs.
Have you contributed to other open source projects?
Yes. Within MetaBrainz, I successfully deployed the ListenBrainz Docker environment and submitted a pull request (LB-812) to add React Testing Library tests for the PlaylistItemCard component. I have also submitted a pull request to the INCF (Brian2) open-source project, establishing their development environment. Furthermore,I have served as a Project Admin for GSSoC '25, which heavily honed my Git workflow and code review skills.
What sorts of programming projects have you done on your own time?
I developed FitLife Hub, utilizing a React frontend and a Python backend via Flask, mirroring the architectural separation used in ListenBrainz. I have also built an AI Fraud Detection System and a Fitness Chatbot, showcasing my ability to manage complex backend logic, machine learning integrations, and API routing.
Practical Requirements:
What computer(s) do you have available? I work on an ASUS TUF Gaming A15 (RTX 3050, Ryzen processor). It efficiently handles running the full ListenBrainz Docker environment, PostgreSQL databases, and message brokers concurrently without performance throttling.
How much time do you have available per week? I am fully committed to this project and will dedicate a minimum of 35 hours per week to ensure all milestones are met ahead of schedule. I will not be attending university courses or holding another job during the Summer of Code coding period, ensuring ListenBrainz has my full, undivided attention.
_______________________________________________________________________________