Contact Information
Name:
Email:
Matrix handle: @minus-1:matrix.org
LeetCode: https://leetcode.com/u/minus-1
Github: https://github.com/MinusOne-01
LinkedIn:
Mentor: @Bitmap
Co-mentors: @reosarevok @yvanzo
Timezone:
Languages: English
Introduction
I am minus1, a programmer with a strong interest in backend systems and database driven development. Over the past several months, I have been building projects that involve designing systems around async processing, background workers and relational database modelling.
One of them is a Job Queue system that models full job lifecycles (pending, processing, completed, failed, dead) and implements reliability mechanisms such as retry handling and failure recovery logic. Also storing job state and execution history to enable lifecycle tracing and failure diagnostics.
Github repo - GitHub - mns-one/job-queue-system · GitHub
You can also find my other projects in Python, Full stack development and Backend systems in the Programming Precedents section.
The Artwork-Indexer project closely aligns with what I have been learning and building. My projects taught me to think carefully about how background processes behave under failure conditions and how data consistency is maintained over time which is exactly the knowledge needed to understand the current architecture of Artwork-Indexer and extend it with new functionality.
Since deciding to apply, I have been actively exploring the MusicBrainz and Artwork_Indexer codebase to understand their architecture and schema design. During that I also engaged with the community and mentor to discuss open issues which helped me to contribute through PRs:
- MBS-13545 - Included cover art related data in Sample dump
- IMG-163 - Updated reload function to use custom config file path
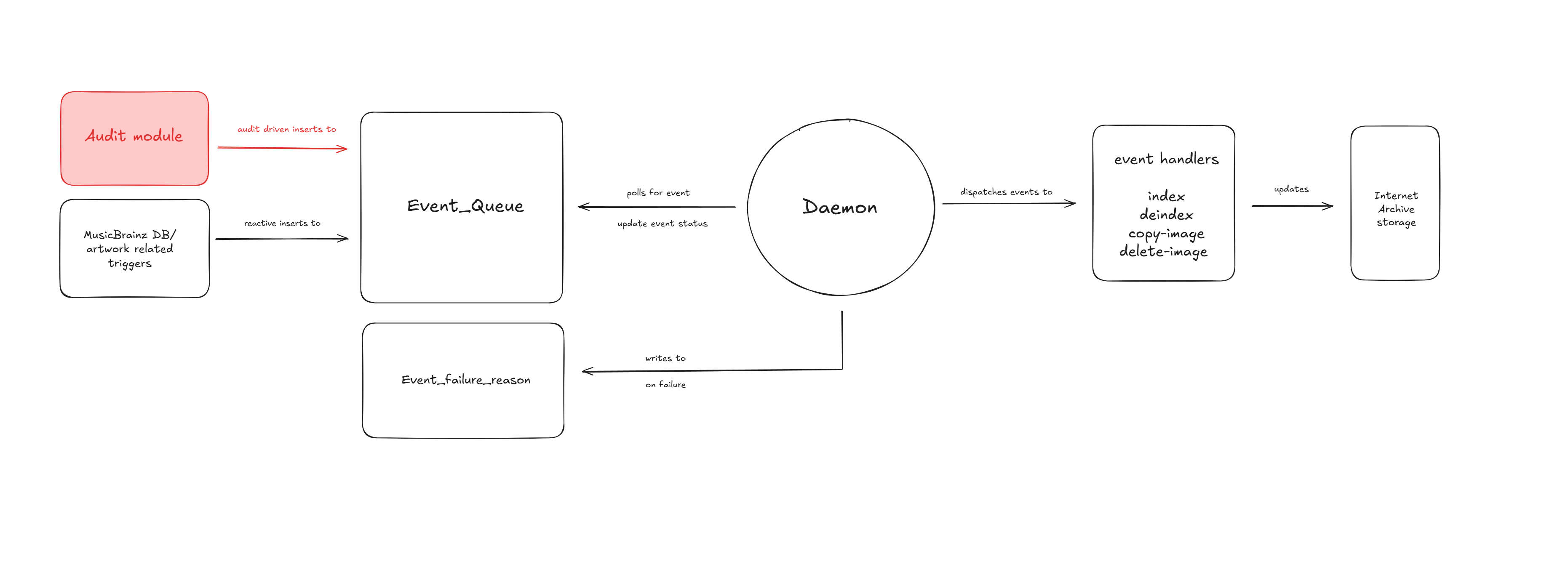
Current Architecture of Artwork-Indexer
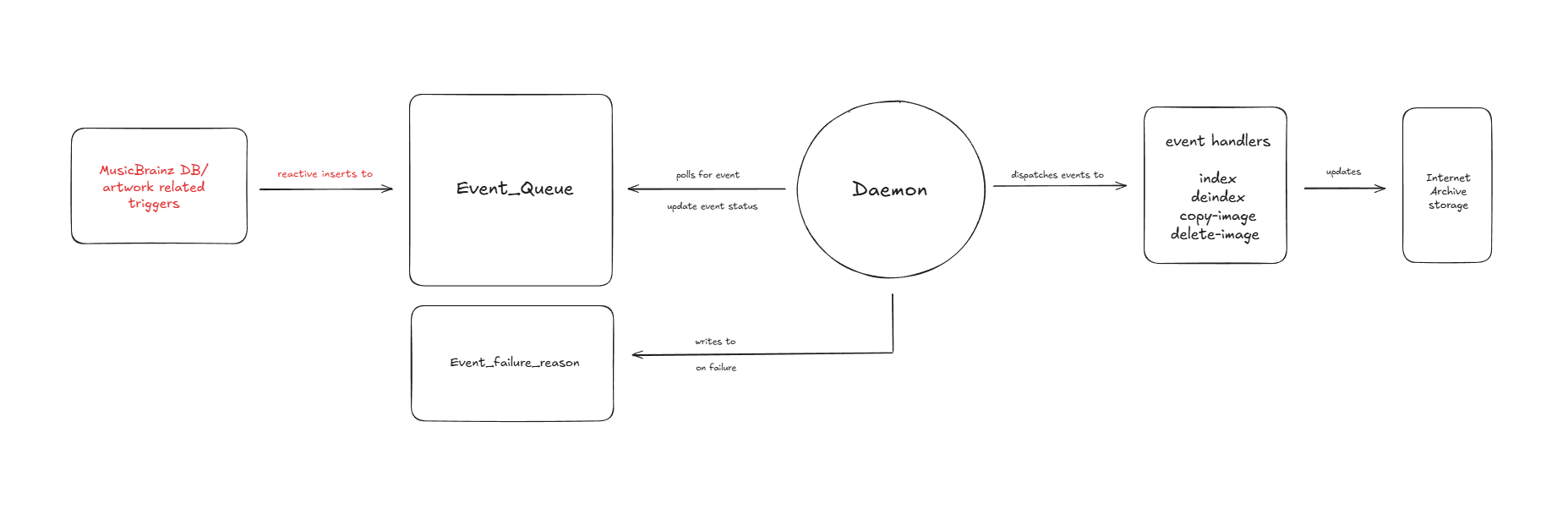
Artwork-indexer is a database-driven daemon that processes the events from Event_Queue. These events are generated by PostgreSQL when relevant MusicBrainz/CAA/EAA data changes.
Right now, events are only added reactively upon new changes to database so it cannot detect or repair historical drift between MusicBrainz and Internet Archive data.
Current flow of daemon event loop:
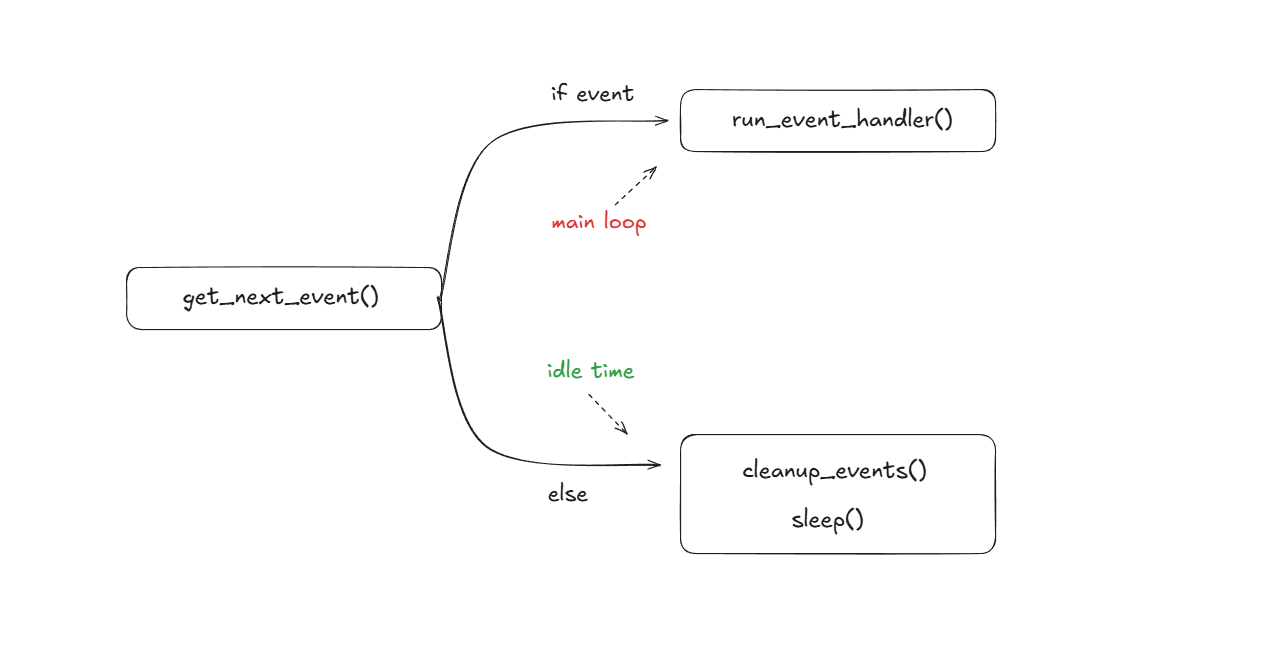
- Polls the event_queue for any available event to process via get_next_event()
- If event is available, dispatch it to correct handler via run_event_handler()
- If no event is available, periodically run cleanup_events()
- Then sleep with backoff and poll again
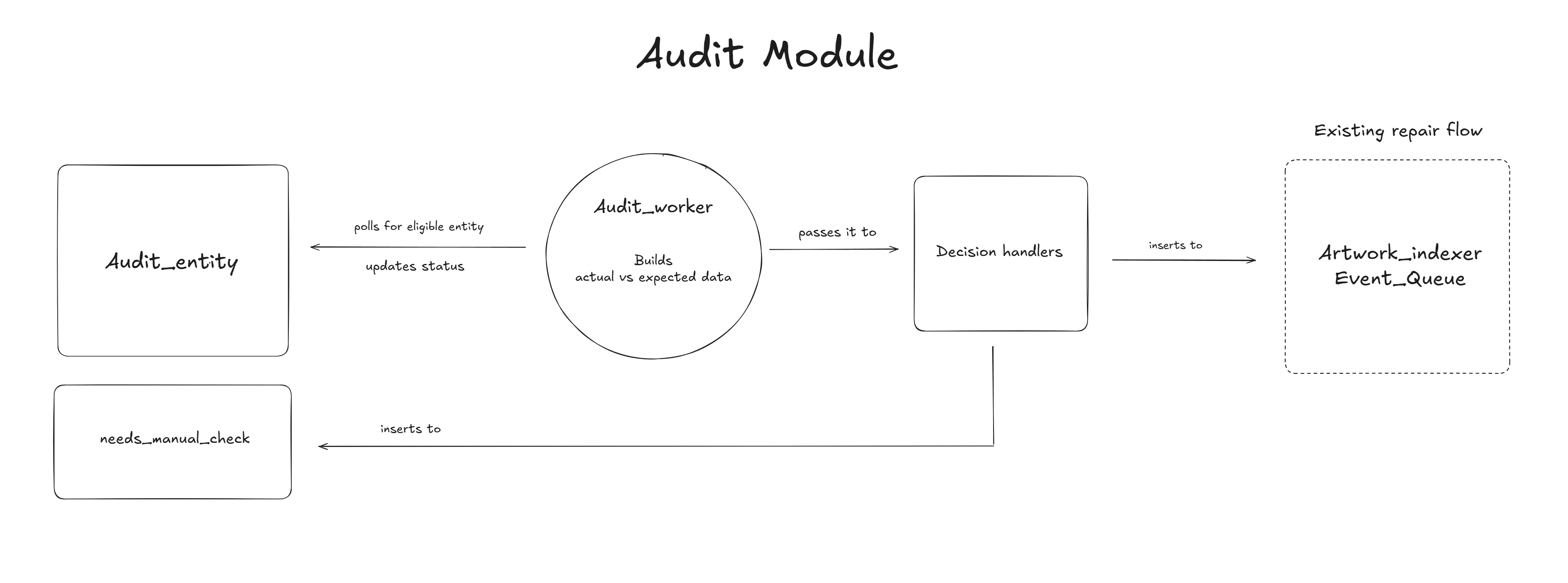
Proposed change
Within the existing daemon loop, add a secondary Audit loop that runs on idle time to audit entities and decide whether they can be repaired using the existing repair loop or need manual review.
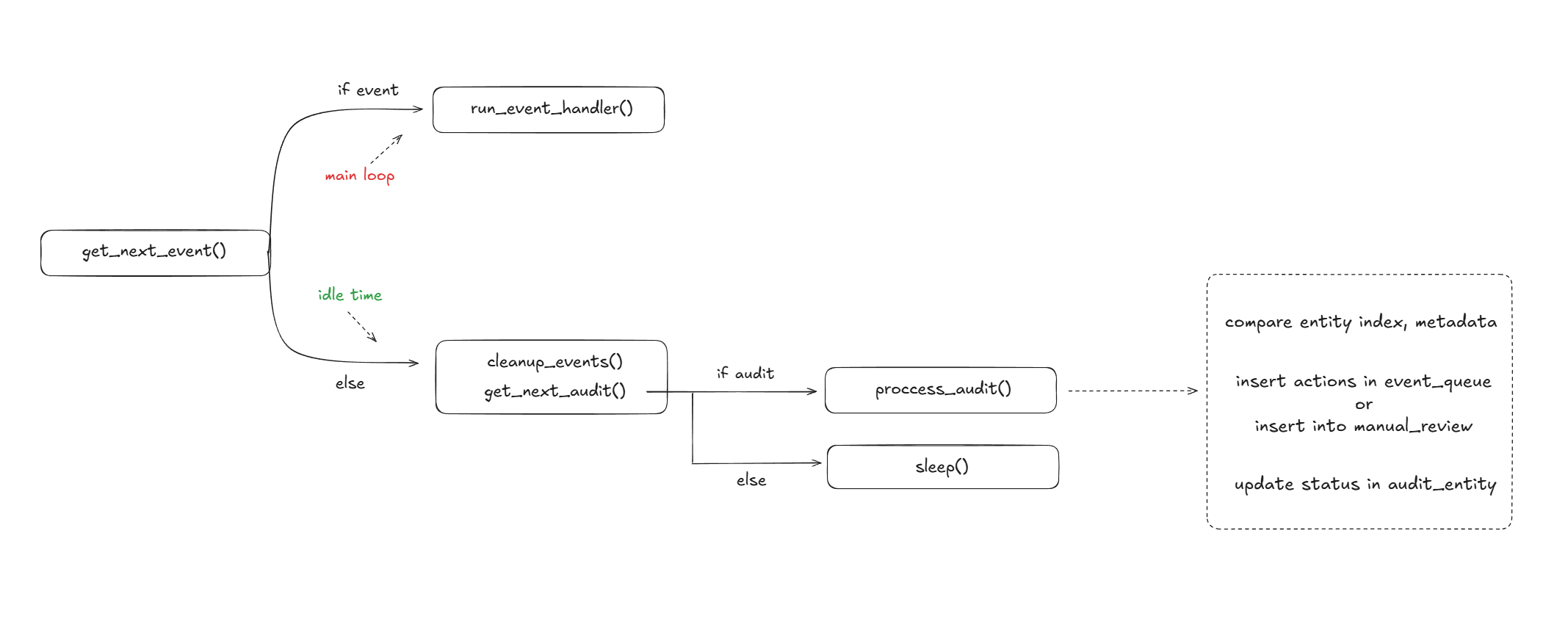
Initially the number of entities to audit will be quite high so in order to not hammer the IA with constant daemon execution, we can add a limit to audit X entities per hour or per day as necessary.
The Audit_Entity row will be selected using FOR UPDATE SKIP LOCKED and status will be changed to ‘audit_in_progress’ to avoid other instances claiming the same row.
Updated flow in Idle time when no event is available,
- periodically run cleanup_events()
- run get_next_audit() with guardrails/limit
- if entity available for audit, update status ‘audit_in_progress’ and run process_audit()
- else sleep with backoff and poll again
Schema
To track which entities are available for audit and persisting their audit results, 2 new tables will be added to the current schema.
Audit_Entity table
Structure:
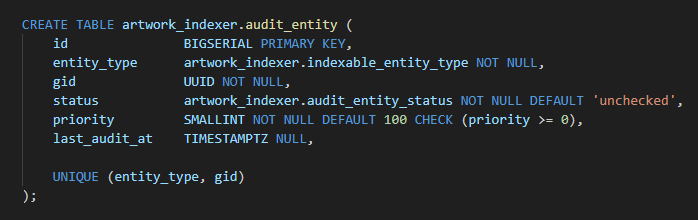
CREATE TABLE artwork_indexer.audit_entity (
id BIGSERIAL PRIMARY KEY,
entity_type artwork_indexer.indexable_entity_type NOT NULL,
gid UUID NOT NULL,
status artwork_indexer.audit_entity_status NOT NULL DEFAULT 'unchecked',
priority SMALLINT NOT NULL DEFAULT 100 CHECK (priority >= 0),
last_audit_at TIMESTAMPTZ NULL,
UNIQUE (entity_type, gid)
);
Use of column(s):
entity_type, gid will uniquely identify which entities exist under Audit tracking.
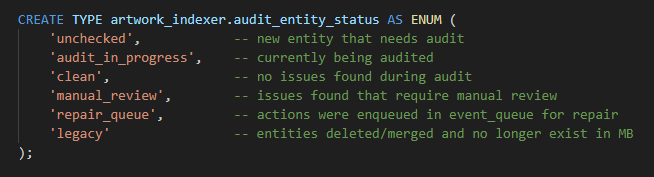
status will have these states for each entity:
CREATE TYPE artwork_indexer.audit_entity_status AS ENUM (
'unchecked', -- new entity that needs audit
'audit_in_progress', -- currently being audited
'clean', -- no issues found during audit
'manual_review', -- issues found that require manual review
'repair_queue', -- actions were enqueued in event_queue for repair
'legacy' -- entities deleted/merged and no longer exist in MB
);
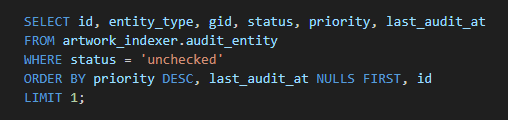
status, priority, last_audit_at will be used to determine which entity needs to be audited next, example query:
SELECT id, entity_type, gid, status, priority, last_audit_at
FROM artwork_indexer.audit_entity
WHERE status = 'unchecked'
ORDER BY priority DESC, last_audit_at NULLS FIRST, id
LIMIT 1;
Indexing:
entity_type, gid - via UNIQUE constraint
Used for lookups to get entities that does not exist in Audit_Entity.
Example query:
SELECT gid FROM release
WHERE NOT EXISTS (
SELECT 1 FROM audit_entity
WHERE entity_type = 'release'
AND gid = release.gid
);
priority, last_audit_at, id
Used for getting next entity to audit:
CREATE INDEX audit_entity_idx_unchecked_priority_last_audit_id
ON artwork_indexer.audit_entity (priority DESC, last_audit_at, id)
WHERE status = 'unchecked';
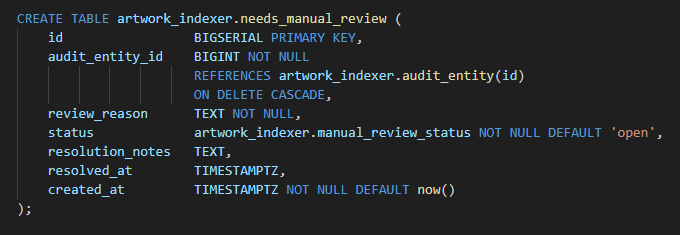
needs_manual_review table
Structure:
CREATE TABLE artwork_indexer.needs_manual_review (
id BIGSERIAL PRIMARY KEY,
audit_entity_id BIGINT NOT NULL
REFERENCES artwork_indexer.audit_entity(id)
ON DELETE CASCADE,
review_reason TEXT NOT NULL,
status artwork_indexer.manual_review_status NOT NULL DEFAULT 'open',
resolution_notes TEXT,
resolved_at TIMESTAMPTZ,
created_at TIMESTAMPTZ NOT NULL DEFAULT now()
);
Use of column(s):
audit_entity_id - links review record to audited entity in Audit_Entity
review_reason - defines why a manual intervention is needed
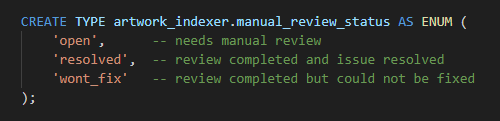
status will have these states:
CREATE TYPE artwork_indexer.manual_review_status AS ENUM (
'open', -- needs manual review
'resolved', -- review completed and issue resolved
'wont_fix' -- review completed but could not be fixed
);
resolution_notes - description for what was actions were taken
resolved_at - timestamp when review was closed
created_at - timestamp when entry was created
Indexing:
Partial index on audit_entity_id to check for open issues:
CREATE UNIQUE INDEX needs_manual_review_open_uniq
ON artwork_indexer.needs_manual_review (audit_entity_id)
WHERE status = 'open';
status, created_at for quick issue listing:
CREATE INDEX needs_manual_review_idx_status_created
ON artwork_indexer.needs_manual_review (status, created_at);
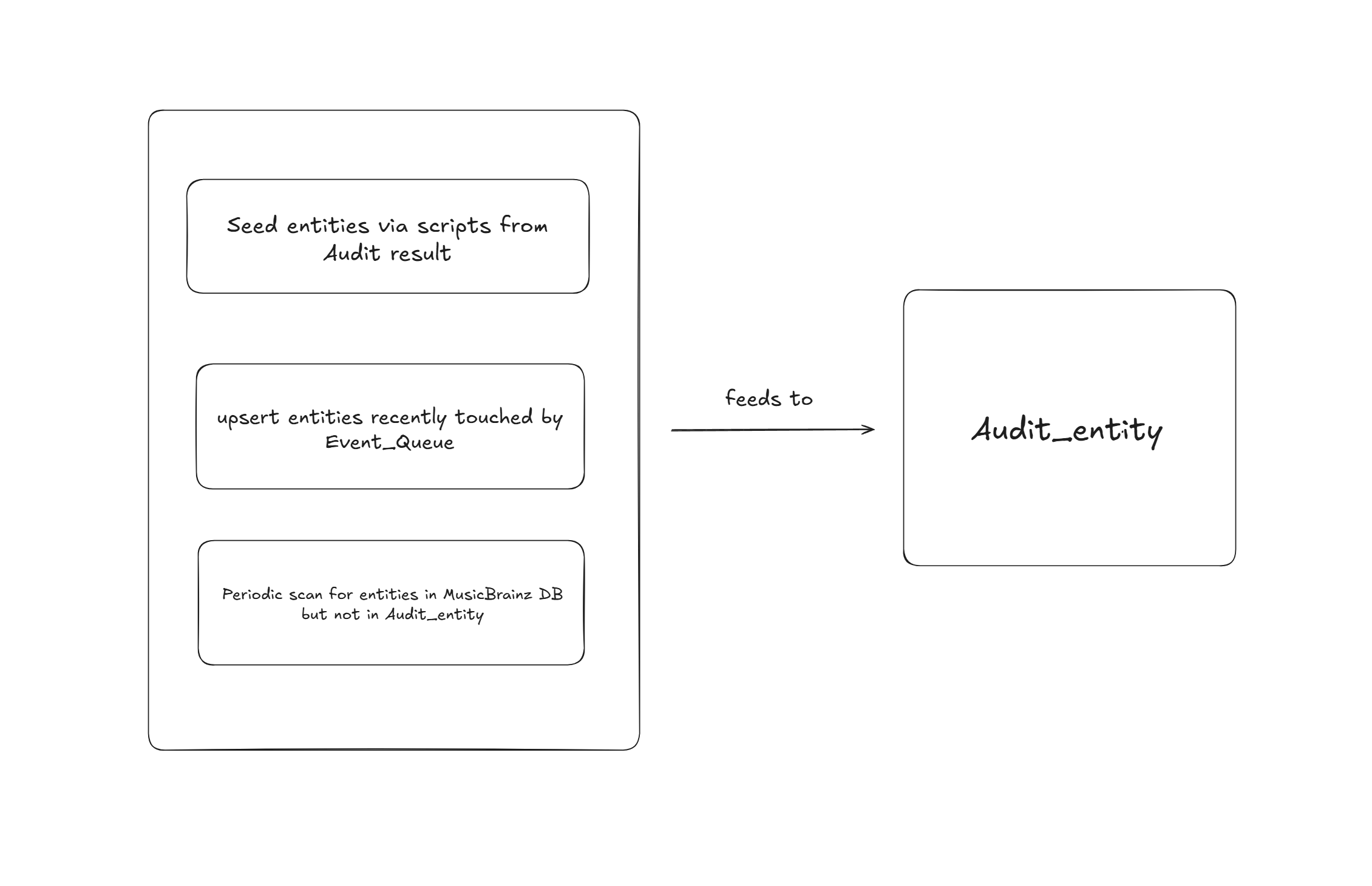
Seeding entities into Audit_Entity
Fresh data using existing event loop
The current event loop already reacts to any change in the CAA/EAA database. Upon completion or failure of an event in event_queue, we can upsert the associated entity into Audit_Entity (if missing) and update the status accordingly.
That way using the existing loop Audit_Entity will have the latest status for each entity and any new entity previously not there will be inserted.
IMG-129 Audit results
Auditing data of IMG-129 have well organised results in structured format. A lot of entities in them might not exist in MusicBrainz DB anymore so we can use them to check if any orphaned files still exist on IA.
Since this Audit data is quite old now, it should not be directly inserted into event_queue. First the available entities need to be fetched, normalized and inserted into the Audit_Entity table so fresh decisions can be made for those entities.
MusicBrainz Database
Scripts will be used to backfill entities not in Audit_Entity from the MusicBrainz database.
Example:
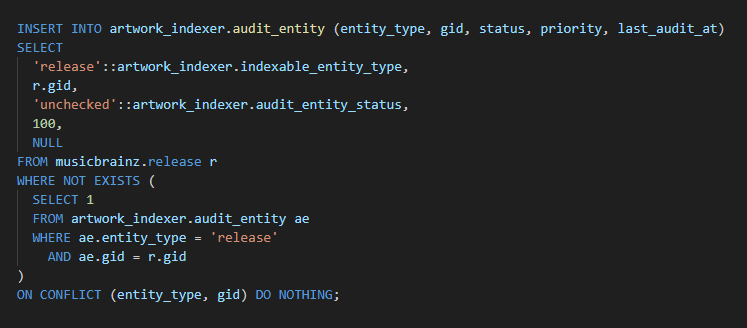
INSERT INTO artwork_indexer.audit_entity (entity_type, gid, status, priority, last_audit_at)
SELECT
'release'::artwork_indexer.indexable_entity_type,
r.gid,
'unchecked'::artwork_indexer.audit_entity_status,
100,
NULL
FROM musicbrainz.release r
WHERE NOT EXISTS (
SELECT 1
FROM artwork_indexer.audit_entity ae
WHERE ae.entity_type = 'release'
AND ae.gid = r.gid
)
ON CONFLICT (entity_type, gid) DO NOTHING;
Orphaned Items from IA
Scripts will be used to scan the IA CAA and EAA collections via the IA Search API, extract gid from each IA item identifier and upsert that gid into Audit_Entity to get all orphaned/legacy items.
Audit process for each entity
Currently MusicBrainz uses 2 files to provide necessary information about an Entity (Release/Event) to Internet Archive,
- mb_metadata.xml
- index.json
mb_metadata.xml
This file contains all the text based info like:
- title, status, language
- credited artist info - name, sort_name, country
- release event info
- barcode
- asin
- boolean info about cover art availability
- event name
- event setlist
- supporting artist details
index.json
This file provides the details about all available binaries (artworks) for an Entity.
Currently the Artwork-Indexerer uses fetch_image_rows() to get all cover_art rows for an Entity, then build_image_json() converts the info from that row into an object.
That way, all artwork objects under an Entity are packaged together into a json file that is sent to IA as index.json.
These 2 files will be used for the Audit process flow:
- Build States
- Compare
- Decision handling
Build states
Expected State
This is the Source of truth from the MusicBrainz database.
The json file is already generated by Artwork-Indexer for CAA/EAA so those functions/logic can be reused to build that file.
The xml file will be fetched from mb web server using these endpoints,
Release - https://musicbrainz.org/ws/2/release/{mbid}?inc=artists
Event - https://musicbrainz.org/ws/2/event/{mbid}?inc=artist-rels+place-rels
Actual State
Entity files and metadata fetched from the Internet Archive server.
IA provides this endpoint to get metadata of an Entity,
https://archive.org/metadata/mbid-
It includes entity metadata and list all available files for entity like:
- index.json
- mb_metadata.xml ( metadata from MB side )
- meta.xml ( metadata from IA side )
- original artwork
- derived files such as thumbnails, metadata log
Then mb_metadata.xml and index.json can be fetched using these endpoints,
https://archive.org/download/mbid-{mbid}/index.json
https://archive.org/download/mbid-{mbid}/mbid-{mbid}_mb_metadata.xml
Compare
Both State files will be compared by:
- Does this entity exist on MB DB?
- Does IA have the necessary files?
- Field and values in xml and json file
- Types used by values like string, int
- Ordering of images in index.json
Decision Handling
Multiple checks will run in sequence and a flag method will be used to determine the final decision. So if the manual_review flag is set at any point then no event_queue actions will be inserted.
Also if an entity needs more than one action then execution order will be taken into account like if both delete_image and index action is required then index will be dependent on delete_image.
Overview of checks,
Entity only exists on IA ( Orphaned entities )
-
if IA file listing has index.json or main image,
Parse artwork-id from filename check if it exists in cover_art db if exists delete_image action as its probably a leftover after merge/update else manual_review to check whether it needs to be preserved or purged deindex entity only if none of the images need manual_review -
any other leftover file like log, xml, thumbnails,
manual_review as IA side intervention needed
Entity exists on MB Database
-
if mb_metadata.xml or index.json is missing on IA,
index action -
if mb_metadata.xml on IA has mismatch in fields or values,
index action -
Also the meta.xml file contains metadata fields like collection, noindex, mediatype. If these are missing or incorrect then index action as these fields are sent via the http headers in index handler function.
-
if index.json on IA has extra images,
check if that artwork exists in cover_art db if exists delete_image action as its probably a leftover after merge/update else manual_review to check whether it needs to be preserved or purged -
if index.json on IA side has:
-
incorrect json shape
-
missing fields or images
-
mismatch in url or field values
-
mismatch in types used by fields like string, int
-
mismatch in image ordering
index action
-
Timeline
Community bonding period ( May 1 to May 26 )
- Trace the Artwork-Indexer execution flow end to end, discuss any remaining doubts with mentor
Week 1
- Finalize and implement the structure for Audit_Entity and needs_manual_review table
Week 2
- Draft Implementation details, execution flow, retry and backoff mechanisms for the Audit process
- Draft functions to build index.json and fetch xml files
- Draft decision handler logic to compare states
Week 3
- Test Audit process flow, execution and reliability mechanisms with sample data
Week 4
- Wire the Audit flow in daemon loop
- Test the Audit flow for any issues with existing loop
Week 5
- Write scripts to scan, normalize and fetch gids from IMG-129 results
Week 6
- Process the gids fetched from IMG-129 results
- Write and test scripts to backfill gids from MusicBrainz database
Week 7
- Backfill gids from MusicBrainz database
- Test scripts to scan IA collection to find orphaned items
Week 8
- Scan and fetch all orphaned item gids
Week 9
- Analyze and discuss the entities needing manual review with mentor
Week 10
- Write documentation
- Buffer for any edge cases/issues that might arise
Stretch Goals for Remaining week
As this project could be completed in around 10 weeks, I’ve prepared an extra goal of creating a Dashboard UI to utilize the remaining time.
Admin Dashboard UI
A dashboard to view, filter and perform simple actions on records in the Artwork-Indexer schema making it easy to get a quick look and inspect the tables.
Since this repo uses python, I propose using the Streamlit and Pandas library. It can directly use the existing pg_conn_wrapper.py and config.ini to set up database connection, avoiding more infra work and a single dashboard.py file will be sufficient to set up everything in a clean way.
dashboard.py file will be organised into 3 sections:
- Config - reads config.ini and sets up db connection
- Query helpers - one function per query to fetch records, each can accept filter parameters
- Main UI - the Streamlit layout code
Dashboard will have multiple tabs and each tab will be associated with one Query helper.
For instance, the Failed events tab will use this helper function that can also accept params to display both Release and Event records. Returned rows will be turned into table view using st.dataframe():
def get_failed_events(conn):
query = """
SELECT id, entity_type, action, state, last_updated
FROM artwork_indexer.event_queue
WHERE state = 'failed'
AND entity_type = %s
ORDER BY last_updated DESC
"""
result = pd.read_sql(query, conn, params=["release"])
return result
rows = get_failed_events(conn)
st.dataframe(rows)
To perform simple actions like changing event status from ‘failed’ to ‘queue’, st.data_editor() will be used which enables checkboxes on each row to bulk select field values like id. So these can be passed to another helper function like this:
def requeue_events(conn, ids):
query = """
UPDATE artwork_indexer.event_queue
SET state = 'queued'
WHERE id = ANY(%s)
"""
with conn.cursor() as cur:
cur.execute(query, [ids])
conn.commit()
result = get_failed_events(conn)
rows = result.copy()
rows.insert(0, "select", False) # insert checkbox column
# making other columns uneditable for safety
edited = st.data_editor(
rows,
disabled=["id", "entity_type", "action", "state", "last_updated"],
hide_index=True,
)
# to get selected row ids and pass them to a helper function using button
selected_ids = edited[edited["select"] == True]["id"].tolist()
if st.button("Re-queue selected"):
if selected_ids:
requeue_events(conn, selected_ids)
st.success(f"Re-queued {len(selected_ids)} events")
st.rerun()
else:
st.warning("No rows selected")
Using these methods, many other table views and actions will be enabled on the dashboard UI.
Community affinities
What type of music do you listen to?
I love music that have feel good and fun vibes, recently I’m listening to these songs I discovered from shows and video games:
- Love dramatic - 8ebaff63-ecdf-49fb-a234-b3a9b960958f
- Giri Giri - ac1f8da0-21d7-426e-83b0-befff06f0871
- Ruler of my heart - a2999f63-5a97-4710-a0a3-9b3b25a2eedb
- DamiDami - dcabb48c-a428-4914-a2e7-cc7ad638d641
What aspects of MusicBrainz interest you the most?
The idea of preserving and maintaining information about the artists and their amazing work spanning across decades so they aren’t lost to time really piques my interest.
Have you ever used MusicBrainz picard to tag your files or used any of our projects in the past?
I have not used Picard to tag files yet but while researching this proposal I explored the MusicBrainz database, browsing entries for artists I listen to. This gave me an idea on how the metadata is structured and how inconsistencies in cover art metadata could surface to users.
Programming Precedents
When did you first start programming?
My journey into programming began over a year ago in March 2025 when I picked up C++. I started by solving DSA questions and building crud apps to build a strong foundation. After that I focused more on System Design and Backend concepts.
What sort of programming projects have you done on your own time?
I’ve been building everything from simple, fun Python apps for personal use to Full stack and Backend heavy projects to dive deeper into more complex topics, here are some of the recent ones:
-
YouTube Newsletter ( Python app )
-
Job Queue System ( Backend Service )
-
CitySync - Full stack meetup app with geospatial feed, async workers and s3 uploads
-
API Gateway service with API-key based access control
Practical Requirements
What computer(s) do you have available?
I have a Windows 10 desktop pc with specs:
Intel 12th gen i5-12400F
RTX 3060 ti
1TB SSD
32GB RAM
How much time do you have available per week, and how do you plan to use it?
25-30 hours/week, I don’t have any other internships or commitments so I will be fully available for GSoC.