Markdown version with SVG images and footnotes: GitHub
PDF version: Download
Table of Contents
- Contact Information
- Synopsis
- Overview: The Import Process
- Project Goals
- Implementation
- Datasets
- Timeline
- About Me
Contact Information
- Name: David Kellner
- Email: [redacted] (I will not publish my email address in a public forum, but you can find it in the PDF version of my proposal for the GSoC website.)
- Libera.Chat IRC: kellnerd
- GitHub: kellnerd
- Timezone: UTC+02:00 (Central European Summer Time)
Synopsis
BookBrainz still has a relatively small community and contains less entities than other comparable databases.
Therefore we want to provide a way to import available collections of library records into the database while still ensuring that they meet BookBrainz’ high data quality standards.
From a previous GSoC project, the database schema already contains additional tables set up for that purpose, where the imports will await a user’s approval before becoming a fully accepted entity in the database.
The project will require processing very large data dumps (e.g. MARC records or JSON files) in a robust way and transforming entities from one database schema to the BookBrainz schema.
Additionally the whole process should be repeatable without creating duplicate entries.
Overview: The Import Process
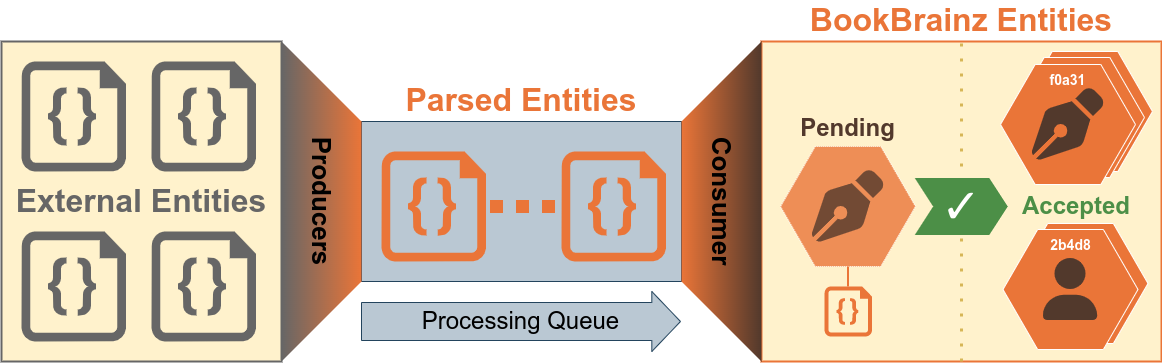
Before I will start to explain the software architecture of the import process, let us agree on common terms for the different states of the imported data:
External Entity:
An entity which has been extracted from a certain external data source (i.e. a database dump or an API response) in its original format.
Parsed Entity:
A JSON representation of the external entity which is compatible with the BookBrainz ORM.
The JSON may also contain additional data which can not be represented within the current BookBrainz schema.
Pending Entity:
The entity has been imported into the BookBrainz database schema, but has not been approved (or discarded) by a user so far.
The additional data of the parsed entity will be kept in a freeform JSON column.
Accepted Entity:
The imported entity has been accepted by a user and now has the same status as a regularly added entity.
Existing Infrastructure
Infrastructure to import entities into BookBrainz had already developed in a previous GSoC project from 2018 [1].
The architecture consists of two separate types of services which are connected by a RabbitMQ messaging queue which acts as a processing queue:
-
Producer: Extracts external entities from a database dump (or an API) and emits parsed entities which are inserted into the queue.
Each external data source has its own specific producer implementation although parts of it can be shared.
Since the parsed entities are queued for insertion into the database, there can be multiple producer instances running in parallel. -
Consumer: Takes parsed entities from the queue and validates them before they are passed to the ORM which inserts them into the database as a pending entity.
The processing queue acts as a buffer to make the fast parsing logic independent from the slow database insertion process.
It also allows the consumer to be stopped or interrupted without losing data and the import process can be continued at any time.
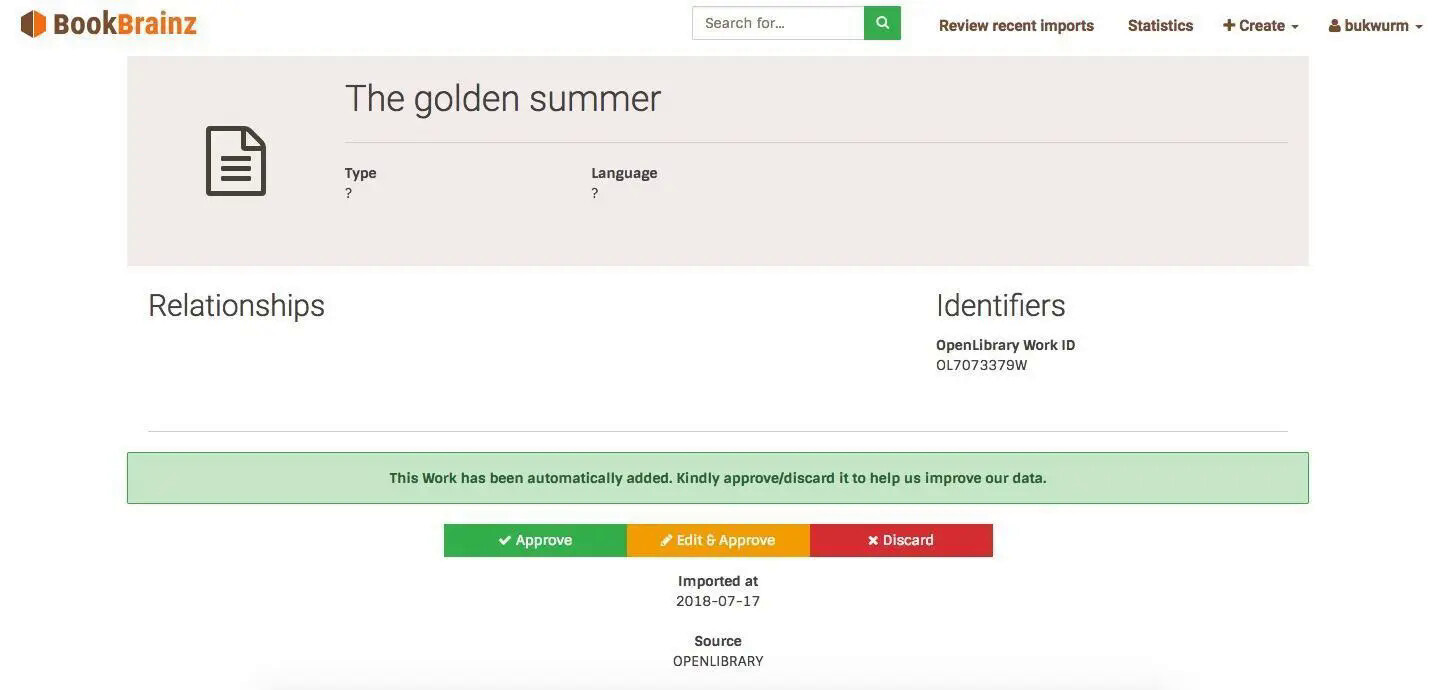
As soon as a pending entity is available in the database, it can be browsed on the website [2].
The page looks similar to that of an accepted entity, but provides different action buttons at the bottom.
Here the user can choose whether they want to discard, approve or edit and approve the entity.
Once an entity gets approved, the server assigns it a BBID and creates an initial entity revision to which the approving user’s browser is redirected.
While a pending entity can be promoted to an accepted entity by a single vote, the pending import will only be deleted if it has been discarded by multiple users.
This is done in order to prevent losing pending entities (which have no previous revision that can be restored!) forever by accident.
And usually we do not want to restore discarded entities when we decide to repeat the import process.
Shortcomings of the Current Implementation
No Support for Relationships Between Pending Entities
A producer reads one external entity at a time and only emits a single parsed entity without any relationships to other entities at that point.
It would be the consumer’s task to resolve the available names and identifiers of the related entities to existing pending entities or even accepted entities.
If the entity resolution does not succeed, the consumer additionally has to create the related pending entities with the minimal information that is currently available.
But pending entities currently only have aliases, identifiers and basic properties (such as annotation, languages, dates) which are specific per entity type.
Allowing them to also have relationships could potentially lead to relationships between pending and accepted entities, because BookBrainz uses bidirectional relationships (new relationships also have to be added to the respective relationship’s target entity).
In order to prevent opening that can of worms, relationships are currently stored in the additional freeform data of pending entities.
| Accepted Entity (Standard) | Pending Entity (Import) | |
|---|---|---|
| Basic properties | ✓ | ✓ |
| Aliases | ✓ | ✓ |
| Identifiers | ✓ | ✓ |
| Relationships [3] | ✓ | ✗ |
| BBID | ✓ | ✗ |
| Revision number | ✓ | ✗ |
| Freeform data | ✗ | ✓ |
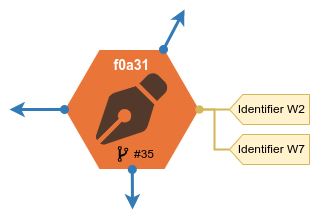
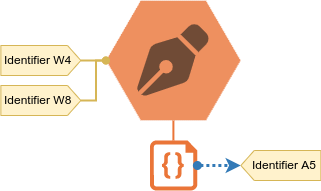
Table: Current features of pending entities
While this was an intentional decision to reduce the complexity of the project in 2018 [4], it is not a viable long term solution.
Importing e.g. a work without at least a relationship to its author saves little work for the users, so we really need to support relationships this time.
Performance Issues
If support for relationships would be the only thing that is currently lacking you might ask yourself why this feature is still not in production in 2023.
Part of the answer is that the developer of the system was not happy with their own results [5] although the project could be considered finished.
As a consequence, the producer and consumer services, which reside in the bookbrainz-utils repository [6], have never been used in production.
The import tables in the database are still empty as of today and therefore it also made no sense to deploy the changes from bookbrainz-site#201 to the website.
One major issue was already identified back then:
The self-developed asyncCluster module, which is used to spawn multiple parallel producer instances, proved to be neither performant nor really asynchronous.
It is based on the Node.js cluster API that creates a separate process for each instance (which also results in high memory consumption).
Since 2018 the newer worker threads API that only creates separate threads has become stable with Node.js v12.
The conclusion was to drop the entire asyncCluster module in favour of worker threads since the data processing seemed to be rather CPU-intensive than I/O-bound.
Outdated and Duplicated Code
Almost five years have passed since the initial implementation of the importer project for GSoC 2018.
Since BookBrainz has evolved in the meantime, the importer is no longer compatible with the latest database schema.
The following changes should be necessary to get the importer project into a clean, working state again:
-
Entity type names have been changed in 2019 from Creator to Author and from Publication to Edition Group in order to make them more consistent. The remaining occurrences in the importer code have to be renamed too.
-
Add import tables for Series entities (which were introduced by a GSoC project in 2021).
-
Update the importer software infrastructure to support Series entities and Author Credits (which were introduced in 2022).
-
Entity validators from
bookbrainz-site(which are used to validate entity editor form data) have been duplicated and adapted for the consumer. Ideally generalized versions of these validators should be moved into bookbrainz-data-js and used by both. -
The UI to list recent imports uses its own kind of pagination component, which should be replaced by the pagination component that is used elsewhere (and which was introduced shortly after GSoC 2018).
-
The pending website changes bookbrainz-site#201 have to be rebased onto the current
masterbranch, which also involves using the new environment with Webpack and Docker (… and the code should probably be refactored a bit more).
Project Goals
During GSoC I will try to achieve the following goals, only those marked as stretch goal are optional, the rest are required to consider this project a success:
- Update existing infrastructure to be compatible with the latest database schema
- Test the infrastructure by finishing the OpenLibrary producer (also from GSoC 2018)
- Update database schema to support relationships between pending entities
- Resolve an entity’s external identifiers to a BBID
- Create relationships between pending entities
- Add a consumer option to update already imported entities when an import process is repeated (with updated source data or an improved producer)
- Pending entities (automatically overwrite old data)
- Accepted entities which have not been changed in BookBrainz (update has to be approved again)
- Accepted entities which have been changed (requires merging) [stretch goal]
- Create a producer which parses MARC records
- Import MARC records from LOC (US Library of Congress)
- Import MARC records from DNB (German National Library) [stretch goal]
- Create type definitions for the parsed entity JSON exchange format
- Improve the performance by replacing the custom
asyncClusterimplementation - Document relevant new features while developing them and write test cases for critical code
- Dockerize the importer infrastructure (producers and consumer) [stretch goal]
Implementation
In this section I will focus on the weaknesses of the already existing importer infrastructure and how I intend to improve them.
Hence I will not write much about the parts which are already supposed to be working [7] and will not propose to change the user-facing components or provide mockups for these.
The only user-facing change which I intend to do on top is displaying pending entities the same way as accepted entities, only with a special marker next to the entity name.
In listings such as the relationship section or entity tables, pending entities will be displayed after the accepted entities.
Ideally they can also be filtered and sorted in the future, but these are general features which BookBrainz is lacking so far and probably out of this project’s scope.
Importing Entities With Relationships
General Considerations and Entity Resolution
Ideally we want to keep relationships between external entities, especially to preserve the authors and publishers of editions and works.
In order to achieve this without creating duplicate target entities every time they appear in another relationship, we have to do a lookup of pending (and maybe even accepted) entities at some point.
Generally, let us keep the specific producer implementations dumb and have all the database lookups on the common consumer’s side, because that way the mapping logic has to be implemented/used only in one place and not in every producer implementation.
Also, directly accessing the database from a producer would defeat the purpose of having a queue that reduces the database load.
The process of looking up relationship target entities is what I called entity resolution previously.
It will take all the available data about relationship target entities from the parsed entity, which includes names, identifiers and possibly other data (such as dates and areas).
Based on this data, it tries to find a single pending or accepted entity which matches the given data with high certainty.
In case of doubt, it will suggest to create a new pending entity using the available data, which can be merged later (if necessary).
Once we have such an entity resolver, there are two possible approaches to model relationships between pending entities:
-
Store representations of the pending entity’s relationships as additional freeform data and create proper relationships only when the user accepts the import.
-
Allow pending entities to also have proper relationships (and deal with the consequences of having relationships between pending and accepted entities).
Pending Entities with Relationship Representations
For this approach, the consumer stores relationship representations in the additional freeform data of the relationship source entity.
Each representation includes the BB relationship type ID and the available data about the target entity, which has no BBID but an external identifier.
When an import is being accepted, we can use the external identifier to resolve it to a target entity among all pending and accepted entities.
If the target entity is also pending, we inform the user that it will also be accepted (on the source entity’s preview page).
In the rare case that there are multiple entities which have the external identifier, we ask the user to select one or merge the entities.
Once we have an accepted target entity, we can use its BBID to convert the relationship representation into a real relationship.
The resulting new relationship sets will be added to the data of each involved entity.
This approach avoids accepted entities ever having relationships to pending entities by simply not using bidirectional relationships.
While this would simplify the consumer implementation, the code to promote pending to accepted entities would be complexer.
We would also need separate code to display pending relationships instead of reusing the existing code for regular relationships.
Hence we will not follow this approach further.
Pending Entities With Proper Relationships
Currently the data of pending entities is stored in the regular bookbrainz.*_data tables (e.g. bookbrainz.edition_data) that are also used for accepted entities.
Only the additional freeform data and other import metadata (such as the source of the data) are stored in the separate bookbrainz.link_import table.
In order to support relationships between two pending entities, we have to assign them BBIDs if we also want to store relationships in the regular tables.
This is necessary because the source and target entity columns of the bookbrainz.relationship table each contain a BBID.
| Accepted Entity (Standard) | Pending Entity (Import) | |
|---|---|---|
| Basic properties | ✓ | ✓ |
| Aliases | ✓ | ✓ |
| Identifiers | ✓ | ✓ |
| Relationships | ✓ | ✓ |
| BBID | ✓ | ✓ |
| Revision number | ✓ | ✗ |
| Freeform data | ✗ | ✓ |
Table: Proposed features of pending entities
Assigning imports a BBID would require a schema change.
Currently the SQL schema of the entry table for pending entities (which are linked to their data via bookbrainz.*_import_header tables for each entity type) looks as follows:
CREATE TABLE IF NOT EXISTS bookbrainz.import (
id SERIAL PRIMARY KEY,
type bookbrainz.entity_type NOT NULL
);
When we alter the id column (and all foreign columns which refer to it) to be a UUID column, the bookbrainz.import table would basically be identical to the bookbrainz.entity table.
So I would suggest to combine both tables and use an additional column to distinguish imports and accepted entities:
CREATE TABLE bookbrainz.entity (
bbid UUID PRIMARY KEY DEFAULT public.uuid_generate_v4(),
type bookbrainz.entity_type NOT NULL,
is_import BOOLEAN NOT NULL DEFAULT FALSE -- new flag
);
Combining the tables (and dropping the bookbrainz.import table) has two advantages:
-
We no longer have to move pending entities into the
bookbrainz.entityonce they have been accepted, we can simply update the newis_importflag. -
The
source_bbidandtarget_bbidcolumns of thebookbrainz.relationshiptable have a foreign key constraint to thebbidcolumn ofbookbrainz.entity.
Having a separate table for imports would have violated that constraint.
Alternatively we would have needed a new flag for both relationship columns in order to know whether the BBID belongs to an accepted entity or to a pending import.
When the consumer now handles a parsed work which has an author, it can add a relationship to the created pending work that points to the resolved author entity.
This works regardless of whether the author is an accepted or a pending entity as both have a BBID now which can be looked up in the bookbrainz.entity table.
Since relationships are (usually) bidirectional, they have to be added to the relationship sets of both involved entities.
While it is unproblematic to update the relationship sets of pending entities, changes to an accepted entity’s relationship set would result in a new entity revision.
Bidirectional relationships between pending and accepted entities cause some problems:
-
Accepted entities might become cluttered with lots of relationships to pending entities of doubtful quality.
-
We do not want to create new revisions of already accepted entities every time a new related pending entity (e.g. a new book by the same author) is imported.
The first problem can be considered a feature as it makes pending entities more discoverable when they are visible in the relationship section of accepted entities’ pages.
After all, we want our users to approve or discard imports related which are related to entities they are familiar with.
Ideally we would provide a way to hide relationships to pending entities, of course.
To solve the second problem, we only create unidirectional relationships from a pending entities to accepted entities initially, i.e. updating the accepted target entities’ relationship sets will be delayed.
There are multiple times during the import flow when we can upgrade these unidirectional relationships to full bidirectional relationships:
-
When the pending entity becomes an accepted entity.
This would be the simplest solution which would also avoid the first problem, but since we consider this to be a feature, we will not do that. -
When an import process run has finished and the consumer is done with importing all the parsed entities in the queue.
This way we will create one new entity revision for each accepted entity at most.
For this compromise we have to keep track of the relationship IDs which have to be added to (or removed from) the relationship set of each accepted entity which is affected.

Repeating the Import Process
Since we do not want to import duplicates every time we rerun an import script (with updated dumps or after code changes, e.g. parser improvements), the pending entities need a unique identifier which is also available in the external entity data.
Using this identifier we will know which external entity already exists as a pending entity and to which entity it corresponds in case we want to update the data.
Identifying Already Imported Entities
Already imported external entities can be identified by the composite primary key of bookbrainz.link_import.
Because the naming of these columns is suboptimal and we already have to do a schema change change for these empty tables, I also suggest alternative names for them:
-
External source/origin of the data (e.g. OpenLibrary):
origin_source_id INT NOT NULL→ origin and source are somewhat redundant terms, rename the column to
external_source_id(and the referenced table toexternal_source) -
External identifier (e.g. OpenLibrary ID):
origin_id TEXT NOT NULL→ naming pattern
*_idis usually used for foreign keys, rename toexternal_identifier(orremote_identifieror simplyidentifier)
Using this information, the consumer can easily identify parsed entities which have already been imported.
The current implementation simply skips these because they violate the condition that a primary key has to be unique.
Taking the proposed relationships between pending entities into account, the consumer will now also create pending entities for missing relationship targets.
Since these entities contain only a minimal amount of data, we want them to be updated as soon as the complete parsed entity comes out of the queue.
When we are doing a full import of an external source, we can assume that it still contains the complete desired entity.
This means that updating pending imports is a desired behavior and we should not skip duplicates at the consumer.
If we want to that, duplicates should be identified as early as possible to avoid wasting processing time, i.e. by the producer at the external entity level.
Since we do not want the producer to permanently ask the database whether the currently processed entity is already pending, and as the entity could also still be queued, there is only one reliable way to do the duplicate detection:
The producer has to load the list of external identifiers, which have already been processed previously, during startup.
This should be sufficient as we can assume that there are no duplicates within in the source dump file itself.
Updating Pending Entities
As discussed in the previous section, we want the consumer to update at least the pending entities.
These pending imports can automatically be overwritten with the new data from the queue, except for the following cases:
-
The import has already been accepted (
bookbrainz.link_import.entity_idis notNULL). -
The pending entity has already been discarded (
bookbrainz.link_import.import_idisNULL) and we do not want this data to be imported again.→
bookbrainz.link_importkeeps track of discarded imports while these are deleted frombookbrainz.import(respectivelybookbrainz.entityafter the proposed schema change)
Overwriting with new data is as trivial as it sounds, except for relationships (of course).
Here we have to compare the pending entity’s relationship set to the parsed entity’s relationship data and make as little changes as possible (because every change also affects the respective target entity’s relationship set).
Updating Accepted Entities
Now that we can update pending entities, we want to try updating already accepted imports with external data changes too.
Therefore we need a way to detect changes between…
-
freshly parsed entities and their pending entity counterparts to see if the parsed entity contains relevant updates (compared to its last import)
-
accepted entities and their pending entity counterparts to see if the accepted entity has been changed in BookBrainz since the import
Both of these checks require keeping a reference to the pending entity in import_id, even after it has already been accepted [8].
In order to detect changes in BookBrainz since the last import, we can simply compare the data IDs of the accepted entity’s current revision and its pending entity equivalent.
If they are identical, no further revisions have been made or the accepted entity has been reverted to the state of the last import.
Detecting relevant updates is harder, because we have to convert the parsed entity to a new (temporary) pending entity to be able to compare it to the old pending entity.
While comparing we have to ignore the internal database IDs of pending entities and only pay attention to differences between the actual values of the old and the new one.
This will also be important later when we want to create the data with the necessary updates while keeping the amount of changes to the already accepted entity minimal.
If there are no relevant changes we will not save the new pending entity.
Otherwise we assign a BBID to the new pending entity with which we will overwrite import_id while the BBID of the previously accepted entity will still be kept in entity_id.
The BBID of the new pending entity will be shown on the page of the accepted entity and suggests the user to review it and approve the changes (again).
When the accepted entity has not been changed in the meantime, approving the new pending entity as a new revision works as follows:
-
The new revision will simply replace the accepted entities data ID by the one of the new pending entity.
-
The same happens for the original pending import, it should always point to the latest accepted data ID (since we do not want to store the history of imports).
-
The new temporary import entry can now be discarded and its BBID in
import_idwill be overwritten with the accepted entity’s BBID again.
Pending updates can easily be recognized byimport_idandentity_idcontaining different values this way. -
Unfortunately relationship changes for pending entities also have to be reflected at the respective target entities.
If the accepted entity has also been changed in the meantime, it gets more complicated and we have to merge the new pending entity into the accepted one on approval.
The bookbrainz.link_import table will get a new boolean column to decide whether we can directly update (as described above) or whether we need to present the accepting user the merge tool first.
Ideally we accept the duplicate entity (without creating a revision) and immediately merge it without having to setup a redirect for the throw-away BBID (which would be merged in its second revision).
Since the merging feature might be quite complex, it is unclear whether it can be achieved during this project.
Blog post: GSoC 2018: Developing infrastructure for importing data into BookBrainz ↩︎
Once the open pull request with the website changes has been merged: bookbrainz-site#201 ↩︎
Refers to regular bidirectional relationships between two entities as well as implicit unidirectional relationships (which are used for Author Credits, Publisher lists and the link between an Edition and its Edition Group). ↩︎
Proposal: GSoC 2018: Importing data into BookBrainz ↩︎
Discussion between bukwurm and Mr_Monkey in
#metabrainz(IRC Logs: June 3rd 2019 | June 4th 2019) ↩︎Code of the importer software infrastructure: bookbrainz-utils/importer ↩︎
I can not guarantee or test that currently, because the code is outdated and has to be adapted to the latest schema version first. ↩︎
This causes no redundant data, as both the accepted entity and the pending entity will point to the same
bookbrainz.*_datacolumn (for the initial revision).
Currently imports (pending entity and associated data) are discarded once they are accepted, but that has to be changed now. ↩︎