BookBrainz: Data Importing
Personal information
Nickname: shivamt
IRC nick: bukwurm
Email: shivamtripathi0108@gmail.com
GitHub: shivam-tripathi (Shivam Tripathi) · GitHub
Twitter: aShivamTripathi
Blog: shivam-tripathi.github.io
Overview
This proposal is aimed at importing data into the BookBrainz database from third party sources, while at the same time ensuring that the quality of the data is maintained.
Data sources
Data can be possibly imported into BookBrainz in the following two major ways:
- Mass import the data using the third party data dumps/APIs
- Manual imports by users from various sources like online bookstores, review sites etc.
In this project, I will mass import the data from openlibrary.org, and if there is time left in the import phase I will work on Library of Congress dumps. The licensing information regarding the dumps can be found here and here. To aid the manual imports, I will write userscripts for goodreads.com and bookdepository.com if time permits, for amazon.com or any other source metabrainz community prefers.
Maintaining the quality of the imported data
To ensure that the quality of the data is maintained, each imported value will have to validated by the BookBrainz editors. To do this, the imported data is not added right away into the entity object in the database, but instead saved as an import object. Unlike the entity object, the import object cannot be revised - and can only be either promoted to an corresponding entity type or deleted. This promotion to an entity object is done after an approval from the editors. Similarly, it is deleted if discarded by the editors.
Proposed data flow
The data imported travels from source to finally become one of the entities in the BookBrainz database. This data life cycle has following steps:
- Data sources
These are the data dumps and the various websites that have the data in the raw form, which needs to be cleaned up and moulded according to the BookBrainz database. - The
importobject
Once cleaned up, the data will be inserted into the database as animportobject. This object cannot be revised, and simply serves as a temporary store of data before it is either accepted or discarded. - The
entitiesobject
Theimportsdata is presented to the user on the BookBrainz-site. The editor now makes one of the following choices:- Approves the
import
This then creates a newentityof the corresponding type in the database. - Discards the
import
In such a case theimportdata is deleted from database. - Decides to make some changes and then approve
In such a case, the editor is presented a form with pre-filled details, using which s/he can edit the details of theimportobject. Once satisfied with the details, the editor can either promote theimporttoentityor cancel the operation to return back.
- Approves the
The completion of the third step marks the end of the data flow. The proposed data flow could be better understood by the following diagram:
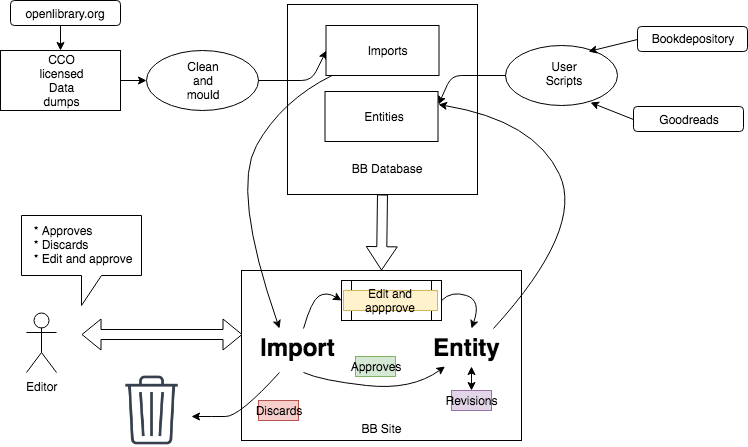
Figure: The imported data life-cycle
Implementation
The data to be imported has two attributes:
- Structure
How the data would reside inside the database. - Behavior
How the data would flow, interact with the editors and how it’s states would change fromimportto anentity.
Milestone 1
Milestone 1 would involve working on definition of the structure of the data that is imported. This involves properly working out schema design and then making relevant changes to bookbrainz-sql and bookbrainz-data code.
The proposed imports object is similar to the entities, except the fact it cannot be revised - it can only be upgraded to the status of entities or deleted from the database. Some of the attributes the import object may hold are:
- Id
- Votes by the editors to discard/approve the imported data
- Source of the imported data (for example, goodreads.com or openlibrary.com)
- Date added
Roughly, presently each entity has entitytype_header, entitytype_revision and entitytype_data table, which respectively store the relevant information about the present master revision, all entity revisions and the complete entity data per revision. The proposed new import object cannot be revised, so it will not need entitytype_revision table. Also, there can be no master revision, so entitytype_header table is also not required by the import object. Only the entitytype_data table is required, and the existing table can be used for the same.
Therefore, the changes to the schema roughly could be:
- Addition of a table
importwith the following fields:
a. id: Incremental index
b. type: The type (string) of the imported entity, for example creator, work, publisher etc.
c. date_added: Date of import
d. source: Source of data (string) - Addition of tables
entitytype_import, where entitytype signifies the type of the entity (namely creator, work, edition, publisher and publication) with the following fields:
a. import_id : The foreign key to table import(id)
b. data_id : The foreign key to table *_data(id) - Addition of table
discard_voteswhich stores all the votes casted to discard an entity. a. id: Incremental index
b. import_id: Id of the import type
c. editor_id: Id of the editor who cast his/her vote
d. vote_number: The sequence number of the vote cast
e. date_voted: Date of casting the vote
Thediscard_votetable ensures that the no two votes cast to discard the import are made by the same editor. This is done by making the tuple (import_id, editor_id) primary key.

Figure: Overview of proposed schema change
Here, the use of discard_votes in the table is based on the conservative approach to changing the state of an imported data which I will be explaining in detail later in this proposal.
Code structure
For the schema change, most of the code would reside inside bookbrainz-sql/schemas/bookbrainz.sql file. Commands to do this can be (creating tables and views):
CREATE TABLE bookbrainz.import (
id SERIAL PRIMARY KEY,
type bookbrainz.entity_type NOT NULL,
date_added DATE,
source TEXT NOT NULL DEFAULT '',
voter_list
);
/* Commands for creator import */
CREATE TABLE bookbrainz.import_creator (
import_id INT PRIMARY KEY,
data_id INT
);
/* Commands for voting table */
CREATE TABLE bookbrainz.discard_votes (
import_id INT,
editor_id INT,
date_voted DATE,
PRIMARY KEY (
import_id,
editor_id
)
);
/* Foreign keys */
ALTER TABLE bookbrainz.import_creator ADD FOREIGN KEY (import_id) REFERENCES bookbrainz.import (id);
ALTER TABLE bookbrainz.import_creator ADD FOREIGN KEY (data_id) REFERENCES bookbrainz.creator_data (id);
ALTER TABLE bookbrainz.discard_votes ADD FOREIGN KEY (import_id) REFERENCES bookbrainz.import (id);
ALTER TABLE bookbrainz.discard_votes ADD FOREIGN KEY (editor_id) REFERENCES bookbrainz.editor (id);
/* Sample view for creator */
CREATE VIEW bookbrainz.import_creator_view AS
SELECT
i.id, cd.id AS data_id, cd.annotation_id, cd.disambiguation_id, als.default_alias_id, cd.begin_year, cd.begin_month, cd.begin_day, cd.begin_area_id, cd.end_year, cd.end_month, cd.end_day, cd.end_area_id, cd.ended, cd.area_id, cd.gender_id, cd.type_id, cd.alias_set_id, cd.identifier_set_id, cd.relationship_set_id, i.type, i.date_added, i.source, i.discard_votes
FROM bookbrainz.import_creator ci
LEFT JOIN bookbrainz.import i ON i.id = ci.import_id
LEFT JOIN bookbrainz.creator_data cd ON ci.data_id = cd.id
LEFT JOIN bookbrainz.alias_set als ON cd.alias_set_id = als.id
WHERE i.type = 'Creator';
Case of edition_data
Edition includes fields containing BBID of publication. This would require some rewiring, or creating a separate table to store edition data.
There are two possible solutions to the problem:
- Make publication_bbid field nullable for all imports, and enforce that it has to be non-null in the code for entities. This essentially means that the imported editions will not have publications attached. The editors can add them when upgrading to entity in the edit and approve page.
- Use UUIDs for imports as well, and add a separate column in the edition_data table to mark type of entry publication_object_entity - if it’s an
importor if it’sentity. Upon upgradation, assign the same UUID of theimportto theentityas well, and update all publication_object_type toentityfromimport.
Keeping other relevant data
While importing the data, we may come across some relevant information about the objects which we cannot introduce yet into the import data in the database due to it lacking the status of a full entity. For example, import objects will have no relationships (as proposed). They will exists as single standalone objects, which will gain all the priviliges once they are upgraded to the entity. Any form of relationship exiting in the dump object will be lost.
To avoid this, a separate table could be constructed containing text field only which will hold all the metadata extracted out from the dump in form of a json field. Postgres 9.4 has the ability to store JSON as “Binary JSON” (or JSONB), which strips out insignificant whitespace (with a tiny bit of overhead when inserting data) but provides a huge benefit when querying it - indexes.
It needs to be decided how the to keep this metadata table linked to the object after it is promoted to state of an entity.
An example could be:
CREATE TABLE import_metadata (
import_id INT, /* For imports */
entity_id UUID, /* For promoted entities */
import_id integer NOT NULL,
data jsonb
);
/* Querying */
SELECT data->>'publisher' AS name FROM import_metadata;
/* Output */
name
----------------
IGC Code
International Code of Signals
IAMSAR Manual Volume III
Nautical Charts & Publications
(4 rows)
Interacting with the import data
The bookbrainz-data module will have to be updated with functions to access and modify import objects. As the present direction of the module is to write separate functions per query returning Immutable.js objects, I will follow that approach. This will also aid in testing, as results of each function could then be easily tested. Also, it will help to write pure SQL queries to interact with database. Roughly, functions for accessing different import objects, upgrading an import object, deleting an import object and adding a new import object will require to be added. Apart from that, handling addition tables like discard_votes etc. will have to be managed.
Milestone 2
The second step would be to import actual data into the BookBrainz database. I will be utilising openlibrary.org and Library of Congress data dumps for this purpose. For this, I will write scripts to read the data, clean it up and then execute SQL queries to insert data from the dumps into the database. To facilitate bulk insertion of data, I will consider the best practices to populate the database. I will cover some of them in more detail later in this proposal.
Handling large dump files
Dumps upon unzipping can easily acquire enormous sizes. For example, edition data from OL is a TSV file which exceeds 30GB upon expanding. To manage this, I propose to break down each file into small manageable chunks (of sizes around ~250MB to ~500MB) and run the code separately on each of them. As each line containing is very much independent of the other, we can split the entire document easily line by line. This can be done easily in UNIX system using:
split -l [number of lines] source_file dest_file
This will split the source_file into multiple files with dest_file prefix. Once converted into manageable chunks, we can extract the data from them one by one, transform them into the desired format and then load them into the database.
Approaching dumps
One of the first thing to do would be to know what all fields exist in a particular dump. Once clear about the various fields in the dumps, it could be figured out how to classify the various data fields and fit them into the BookBrainz data model. This would also help in understanding the edge cases and different forms of data that could creep in.
This would greatly help in validating the data, and testing the validation functions.
Structure of the dumps
In this section I will analyze the structure of the various dumps.
-
Open Library
The dumps are generated monthly, and have been divided into the following three subparts for convenience-
ol_dump_editions.txt
- Size: ~27 GB
- Relevant json in the data dump (after being cleaned):
edition_dump_sample.json
-
ol_dump_works.txt
- Size: ~9.5 GB
- Relevant json in the data dump (after being cleaned):
works_dump_sample.json
-
old_dump_authors.txt
- Size: ~2.23 GB
- Relevant json in the data dump (after being cleaned):
authors_dump_sample.json
-
-
- Books All (A series of 41 dumps)
- Size: ~500 MB to 800 MB per dump
- Relevant xml in the data dump:
books_all.xml
- Classification
- … Other dumps
- Books All (A series of 41 dumps)
Code structure
Theoretically, the entire toolkit to import data can be separated into two parts:
- bookbrainz.import.generate_import
Data dump specific tools, which cleans up the data into a predetermined format. - bookbrainz.import.push_import
A tool which works on a predetermined data format, validates it and imports the data into the database.
In a nutshell, the role of the bookbrainz.import.push_import can be summarised as follows:
- Validate individual data fields
- Encapsulate the data field into data objects
- Validate the data objects
- Push the data object into the database
The role of bookbrainz.import.generate_import can be summarised as:
- Read each text files of the specific dump.
- Extract relevant data field from the text file
- Construct a generic object from the field and pass it to sub-module of bookbrainz.import.push_import to construct the import object.
The bookbrainz.import.push_import tool could readily be reused for importing other dumps in future also. One of the breakdowns possible is developing bookbrainz.import.push_import within the bookbrainz-data already existing as a npm module, which could then be used for reading and pushing data into the BB database the data generated by bookbrainz.import.generate_import.
Another case can be to write a separate module in javascript or any other language which could be used by all bookbrainz.import.generate_import scripts.
I plan to write bookbrainz.import.push_import using javascript, containing the following subparts (roughly):
bookbrainz.import.push_import
- validators
* common (including for encapsulated objects)
* validators specific to each import type- create_objects
* create import objects of each type using the validators per field- push_objects
* push the constructed valid object into the database
This can be placed either inside the bookbrainz-data module or it can exist as an separate module. Using javascript here would automatically mean using node to read data from the dumps.
The dump facing scripts would require to include the bookbrainz.import.push_import module to perform validation and construction of import objects. As it mostly depend on the kind of dump being handled presently, a generic module structure (based on logic flow) could be:
bookbrainz.import.generate_import
- read data: Run the script to input each text file.
- extract data: Extract the required data fields from the objects
- construct a generic object: Construct the generic object to be used to contruct the import object.
- construct and push import object: Call the relevant submodules from the push_data module to construct the relevant import object and push it into the database.
Validators and testing
The bookbrainz.import.push_import module involves validating the individual data to form a complete valid import entity. This requires the validation functions to be robust to the type of data thrown at them. Thus, thorough testing needs to be done to ensure that it can handle any form of data we will throw at it.
Writing validators will be greatly helped by the existing bookbrainz-site/src/client/entity-editor/validators. All these validators would require unit testing to check if they perform as they are intended to.
Secondly, we need to check also if the insertion of imports object occurs as required. This would require populating the bookbrainz-test database using sample input data and then push_objects submodule, and then querying it to check if the final value inside the database is as expected. Similarly, other unit tests can be written to ensure that the system is robust to different forms of data and performs as it’s intended to.
One of the most necessary part of testing the validators would be the sample prototype dataset we would use as arguments. This dataset is to contain all corner cases so as to ensure that the validators are thorougly tested and they do not pass any invalid data into the system. It would be build by sampling and adding some extra records which cover all different forms of values the data can take. It is necessary to work on this thoroughly, as the tests written presently would not just work on dumps presently being using to import, but also the future ones.
Bulk populating the database
Some techniques to bulk import data can be:
- Creating a batch sequence of sql queries and executing them after a fixed batch size. In this case, I will disable autocommits and commit at the end of the batch. In case there is some error, the entire batch will be redone.
- Write the validated imported objects to a flat file per dump subset, and then use COPY. Since it is a single command, it does not need to disable autocommit.
- Before COPYing the data, dropping foreign key constraints and indexes and then importing the data leads to faster data load. Later the contraints can be added back. It would be programmatically ensured that the data being imported satisfies the constraints while creating the import object. The recreation of foreign key constraints and indexing can be greatly sped up by increasing maintainance_work_mem configuration variable.
- Run ANALYZE after altering the data contents of a table. ANALYZE (or VACUUM ANALYZE) ensures that the planner has up-to-date statistics about the table.
Import Endpoint
I will add an import endpoint route to the site, which will come in handy when adding the data via HTTP POST requests. Later if an API is developed, this end point can be removed. This will be crucial with respect to the implementation of various ways by which one tries to send the data object to this end point, requiring the data sent to become an import instead of an entity. Building it would involve designing a fixed data object which encapsulates all the necessary details for building any one or multiple import or entity object. This would require changes in bookbrainz-site/src/server/routes and bookbrainz-site/src/server/helpers modules.
Milestone 3
The third milestone will be to add the behaviour of the data. Once inside the database, the import objects have to travel to the editors via the bookbrainz-site so that they could reach the next stage of it’s life cycle.
I propose to do this via two means:
- Show up the imported data in the search results
- Separately allow the users to see and choose to review what all data has been imported and is waiting for review.
Search results
Presently, BookBrainz uses Elasticsearch to facilitate search. I will update the Elasticsearch indexing so that imported objects appear in the search results on the bookbrainz-site. The front-end on the website will be modified to reflect these changes, so that upon search the users of the site would know if the search result is one added by another editor or if it has been automatically added and awaits review. One of the plausible ways to do this can be:
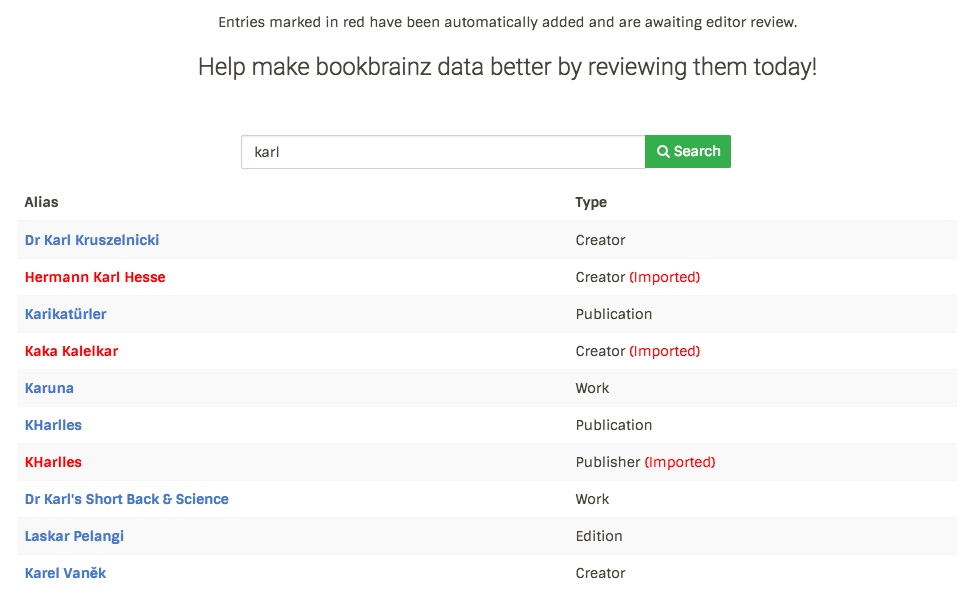
Image: Proposed search results page with imported data highlighted
Upon clicking an imported data, the user will be directed to the imported entity page.
Elasticsearch indexing update would need updating generateIndex function in bookbrainz-site/src/server/helpers/search.js which would add the imports when indexing the ES after a restart.
Also, separate functions would be required to insert new imports and delete the approved imports from the Elasticsearch index. The function to insert new imports into the index would also be useful for add import endpoint, so that as soon as an import is added to the database, it also is added in the ES index.
Imported entity page
This is the landing page of the imported data. It will be very similar to the regular entity, except with the following options instead:
- Approve
- Edit and approve
- Discard
- Data source
One possible way to implement the page can be:
Image: The proposed ‘Imported entity’ page
Changing state of an import
As importing of data takes time and effort and discarding an import leads to permanent deletion, I propose keeping a conservative approach towards discarding an import, but being liberal while upgrading, i.e. we make it easy for an import to get included in the database as an entity, but difficult to be removed. I propose that we attach a field ‘votes against’ which is incremented every time an editor says that the import should discarded, and discard an import only if the number of votes reach a threshold. However, we immediately promote an import if an editor marks it approved. Whenever the import object is deleted or upgraded, we delete the search index to ensure it doesn’t turn up in the results. Upon upgradation, the new entity also needs to be inserted into the ES index.
Review page
Another way for the editors to interact with the imported data is to provide them with a page that displays only the imported data. That way, the editors could choose to review imported data from the list. This would include adding a review button at the top, next to ‘create’ button. Upon clicking the ‘review’ button, the user would be directed to the page containing a list imported data, with a limit on imported data shown per page. The user can browse through the list and can choose which import s/he intends to review. Upon clicking any item in the list, the user would be directed to the imported entity page of that particular import.

Image: Addition of the ‘Review’ option
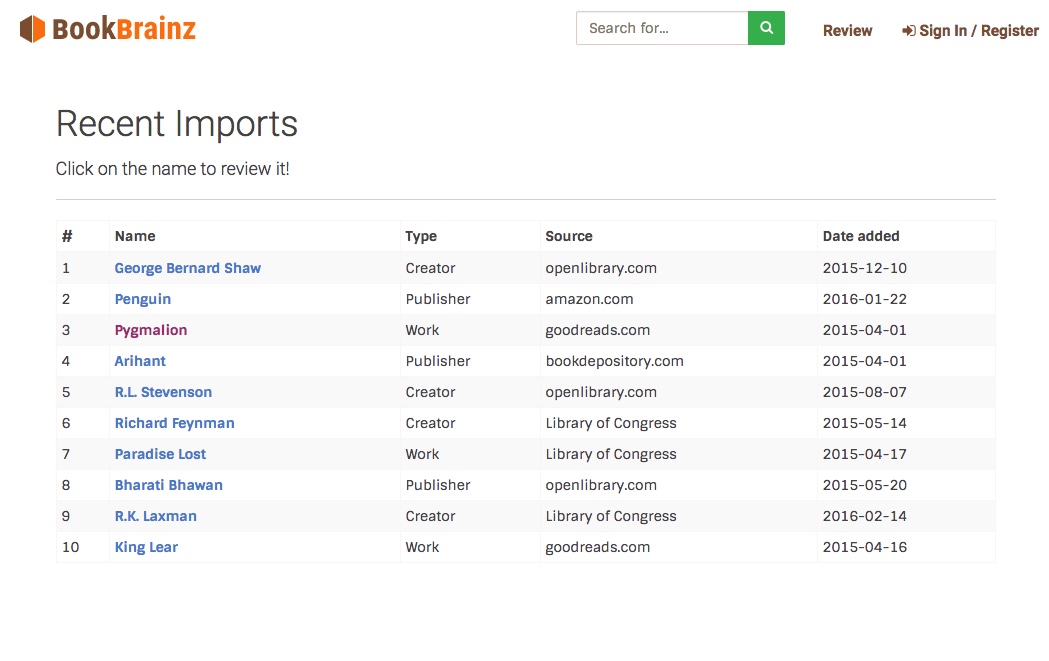
Image: The ‘Review’ page
Imported data and non-editors
Presently, the users which are not logged in can search the BookBrainz database view the results. Adding the imported data can now effect this search in two ways:
● Not allow the display of imported data to a user who is not an editor in the search result.
● Allow display of all the data BookBrainz has in the search result. Upon clicking the result, the user will be led to log in page. Only after loggin in can user visit the imported entity page and approve/discard/edit and approve the import.
I would like to go with the latter implementation, unless decided otherwise.
Milestone 4
The last step would be to write userscripts to facilitate seeding of data from third party websites like goodreads, amazon, bookdepository. The import endpoint at the bookbrainz-site mentioned in the first milestone was developed specifically with this in mind. The userscripts written would be run using the tampermonkey or greasemonkey extensions in the user browser.
Functionality
Aim of this tool is to reduce the effort of an editor when s/he decides to add an entity’s information into the database by directly sending over the data to the BookBrainz database. If the user intends to make changes, s/he can do so at any point of time at the bookbrainz-site.
- When a user opens up a site containing data about books (for example, bookdepository.com), the browser fetches the website content.
- If the URL of the website is the one on which the userscript has to become active, the userscript starts and collects relevant data from the page (by analyzing the DOM).
- The userscript then constructs relevant import objects from the collected data
- The userscript also adds a
Import to BBbutton to the page at any location easily visible. - Upon clicking the button, a modal opens up containing a list of all the entities ( creator, work, publisher, publication etc.) which could be imported from the page followed by a button to search the entities on the bookbrainz-site and a button to import the entity.
- Upon clicking any one search button, a new tab opens up of bookbrainz-site search page with query of the entity’s name.
- Upon clicking any import button, the site either sends the data directly to the BookBrainz-site or opens up a search page in a new tab with query as name of the entity.

Figure: The sequence diagram on a timeline for the userscripts
The userscripts would be written separately in a different repository with name bookbrainz-scripts and made available to the users with a single click.
Code structure
Roughly, overall code can be broken into following two parts for every userscript:
- The part which returns UI components (button, form etc.) to be inserted into the relevant
URL. This is common to all userscripts. - The part specific to each URL - where to inject the button, from where to get data, how to
construct the data object etc.
The first part will be implemented separately. It can be included in all the all the userscripts either by bundling them together, or// @requirethem in the code. I intend to use React to build the relevant components. It is unnecessary to use any bundler, but it could be beneficial in case of writing more modular ES6 format code.
More specifically, the code can be split up as:
bookbrainz-userscripts
- src
- lib
- UI Components
- Application’s business logic to wrap up the extracted data according to the end point
- all userscripts
This design is taken from musicbrainz userscripts. It is robust to future additions, as the lib contains the generic userscripts including UI components design and other data cleaning and encapsulation methods, which are used by other scripts. The userscripts are written alongside the lib, and can directly include them in a CDN like manner using \\ @require lib/{script_name}.js tag in the header, if // @namespace is mentioned also.
Any new userscript can be written along side the lib package is it aims at providing site specific tools, or else add it in the lib package which hold all the common case scripts.
Documentation
Schema changes would require proper documentation for future purposes, which I will write in the official developer docs. Most of the remaining work would be in javascript, which will be covered by JSDocs. Additionally, in every buffer week I will spend time to record all the work carried out in the previous phase, which will cover developer side of documentation.
Addition of imported objects is a huge overhaul in the present state of site, and some users (old and new) might easily become confused about how to use the new features. To tackle this, I plan on writing a concise but complete explanation of the new import object in the website in a user friendly manner, which could be added on the website itself (with links to it lying all over the website) or on read-the-docs. Writing proper user documentation is as useful as addition of the new feature, as if the editors themselves are unaware of how to use it, the addition would be rendered useless. One of the ways to easily integrate FAQs into the site with search option embedded could be by using gitbook static site generator, which reads developer friendly markdown to convert it to a static site.
Additionally, I will open up multiple questions on the metabrainz community which answer some common FAQs regarding the new features and imports. I will also work on documenting some of the present features.
Timeline, Alternate Ideas, Detailed Information about yourself.
