As you know, we’ve been working hard on building recommendations and other music discovery tools as part of ListenBrainz. Our frustrations with online streaming providers and their questionable discovery features have long been a source of frustration for us, so we worked hard to build recommendations with as little bias as possible.
Fortunately, we’re not alone in our frustration with the steaming providers – researchers at Aalborg University, Denmark and Lille University, France are currently questioning the fairness of these music recommendations and have asked ListenBrainz and its community to help them with this task.
This is such an important project!! So glad that LB users + data can be part of something like this, which could have a big impact.
I’m not sure if it’s mentioned anywhere, but based off the available countries in the profile creation list they are looking for EU users only, so little Aotearoa New Zealand can’t be of any help this time. But if you’re a EU LB user and your data is already public via LB, it would be awesome if you could help shed some light on some of the bigger, possibly eeeeevil, streaming algorithms…
Hey, I didn’t say “Spotify”, you just immediately thought “Spotify”. Nothin’ to do with me!
Thank you for your question. You’re using something like Ampache? Unfortunately, we won’t be able to connect to this type of music server, as our goal is to analyze recommendations from streaming services, which are essentially a “black box.”
Dear @aerozol
Thank you for your feedback and support - we’ll do our best to make an impact in the sector!
Indeed, for legal purposes, we shouldn’t consider data from outside the EU.
The LB database is impressive (I’m also contributing now), but to analyze it fruitfully, we need some contextual information about donors. This will help ensure the validity of your research as much as possible. For that, we just need your id and you to answer to few questions.
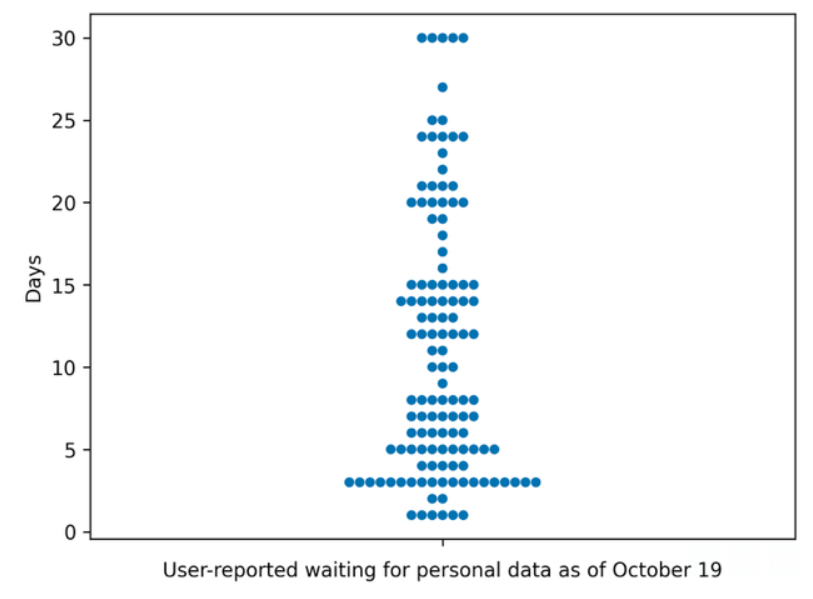
I tried to link my LB account, but failed, though. The original process failed with some error message I don’t remember. I ended up creating an account on fairmuse.eu, which worked. But now I cannot link my LB account name. Following the link on Fair MusE Portal – Listen Brainz – portal.fairmuse.eu now just shows the “Thank you for your donation!” message, but my LB account name is actually not linked to my profile.
Hello @antoinefairmuse. Could you tell a bit more about your analysis strategy? What I have gathered from the FairMusE website is that you will be calculating some sort of diversity scores and a “fairness score” from various listening histories. What I do not understand is how this will inform you about the workings of the recommendation systems of streaming providers. The only way I can think of accomplishing this is to compare diversity of individual listening history to the diversity in the recommendation list, but I don’t think you have access to this information. So I am actually interested in how you are trying to pull this off.
Dear @biocv,
We try as much as possible not to recruit friends and family yet of course, people of the consortium spread the campaign in their own country (where we could have some relays). That’s also contribute to explain why there is an overrepresentation.
If you’re interested, we’re hosting a workshop on January 17th in Paris (and it’s also possible to attend online). Would you like me to extend an invitation?
Regarding your query, we’ll also be collecting playlists created by Spotify or Apple Music at the same time. Furthermore, we have data on song popularity and songs broadcasted on radios - this is part of our analytical approach.
That’s what I suspected; I was just making a teasing remark (sorry). I know it can be really hard to get a representative sample. You will undoubtedly be aware that the respondents from LB will not be representative of the general populace either.
Oh nice! My research background is somewhat different (biology, as you can tell from my handle), but I am interested in the data analysis.
Ah, so you will be collecting recommendations. But you do not have access to the recommendations that match the submitted listening histories right? How do you correct for the fact that your participants may have above-average diversity in their listening habits?