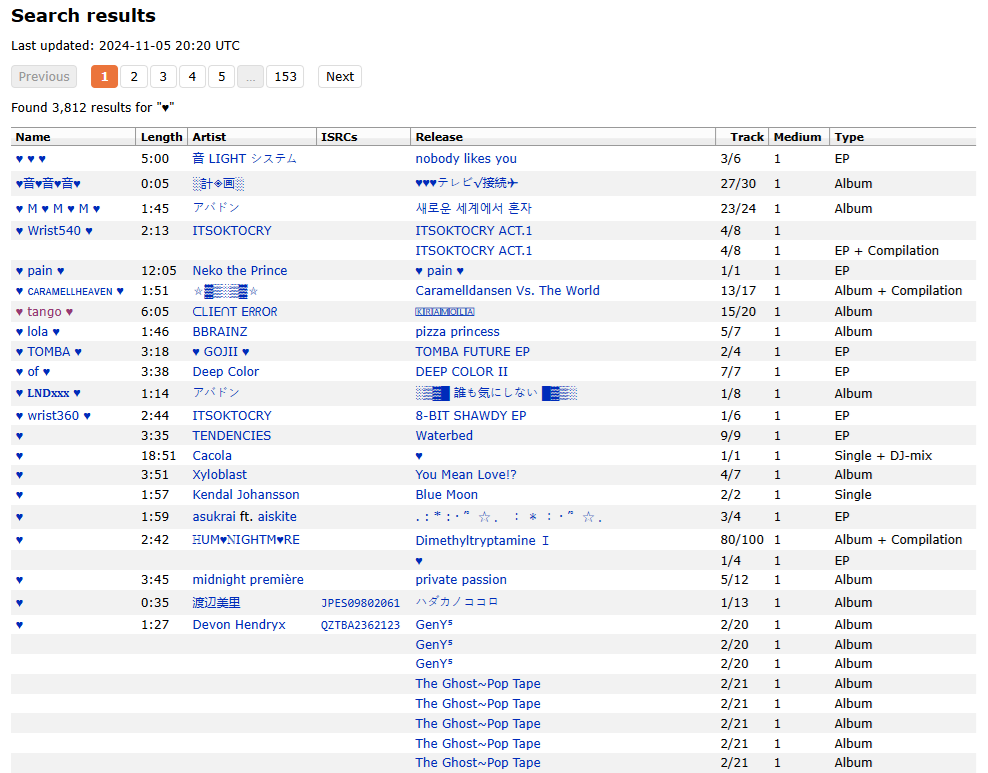
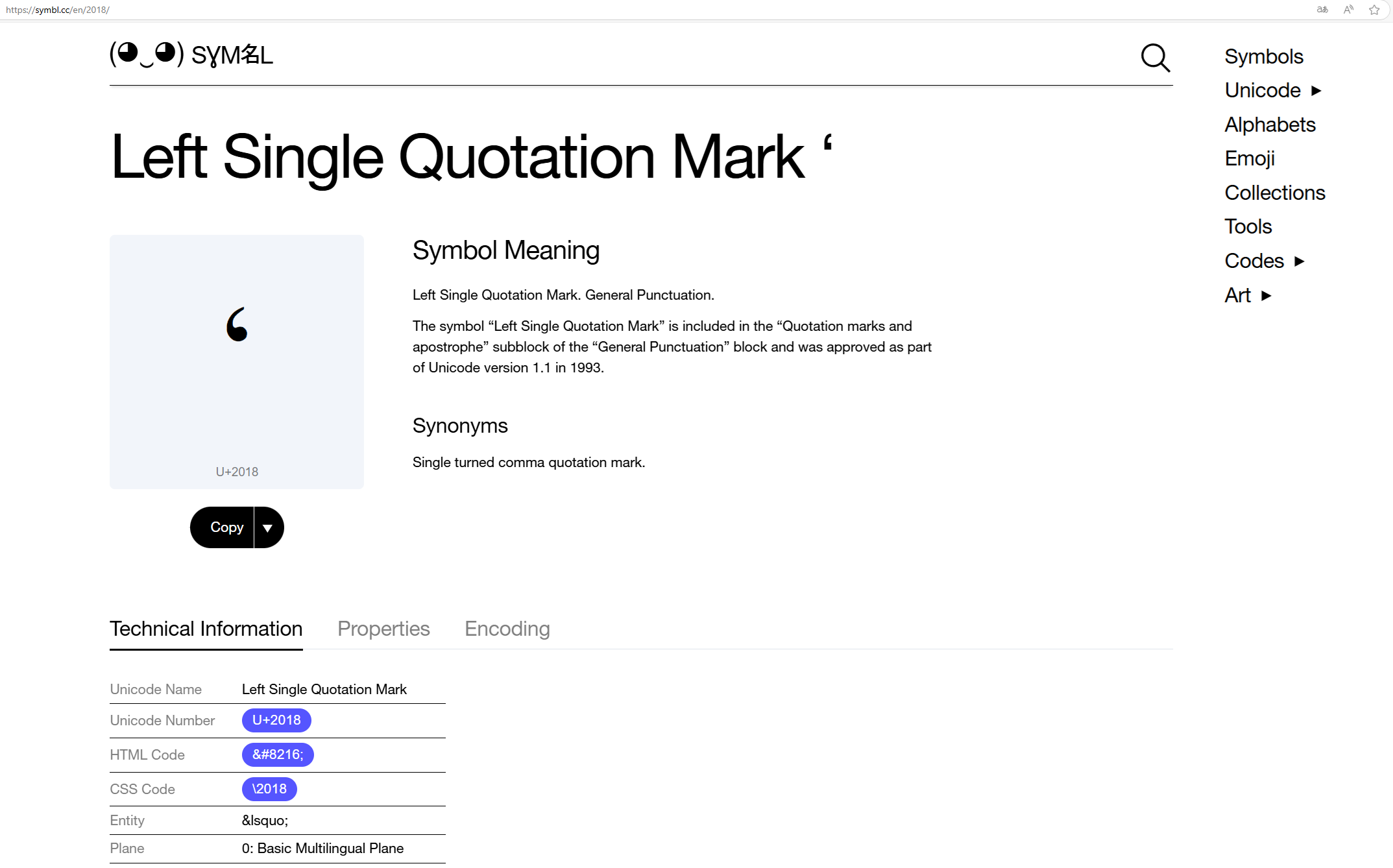
I added 40 new characters to the existing “Non-ASCII Equivalents” plugin without the knowledge of the author Anderson Mesquita.
My characters are: Polish and My others
Here is the code:
# -*- coding: utf-8 -*-
# Copyright (C) 2016 Anderson Mesquita <andersonvom@gmail.com>
#
# This program is free software: you can redistribute it and/or modify it under
# the terms of the GNU General Public License as published by the Free Software
# Foundation, either version 3 of the License, or (at your option) any later
# version.
#
# This program is distributed in the hope that it will be useful, but WITHOUT
# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more
# details.
#
# You should have received a copy of the GNU General Public License along with
# this program. If not, see <http://www.gnu.org/licenses/>.
from picard import metadata
PLUGIN_NAME = "Expanded Non-ASCII Equivalents"
PLUGIN_AUTHOR = "Anderson Mesquita <andersonvom@trysometinghere>, Peter69"
PLUGIN_VERSION = "0.5"
PLUGIN_API_VERSIONS = ["0.9", "0.10", "0.11", "0.15", "2.0"]
PLUGIN_LICENSE = "GPL-3.0-or-later"
PLUGIN_LICENSE_URL = "https://gnu.org/licenses/gpl.html"
PLUGIN_DESCRIPTION = '''Replaces accented and otherwise non-ASCII characters
with a somewhat equivalent version of their ASCII counterparts. This allows old
devices to be able to display song artists and titles somewhat correctly,
instead of displaying weird or blank symbols. It's an attempt to do a little
better than Musicbrainz's native "Replace non-ASCII characters" option.
Currently replaces characters on "album", "artist", and "title" tags.'''
CHAR_TABLE = {
# Acute # Grave # Umlaut # Circumflex
"Á": "A", "À": "A", "Ä": "A", "Â": "A",
"É": "E", "È": "E", "Ë": "E", "Ê": "E",
"Í": "I", "Ì": "I", "Ï": "I", "Î": "I",
"Ó": "O", "Ò": "O", "Ö": "O", "Ô": "O",
"Ú": "U", "Ù": "U", "Ü": "U", "Û": "U",
"Ý": "Y", "Ỳ": "Y", "Ÿ": "Y", "Ŷ": "Y",
"á": "a", "à": "a", "ä": "a", "â": "a",
"é": "e", "è": "e", "ë": "e", "ê": "e",
"í": "i", "ì": "i", "ï": "i", "î": "i",
"ó": "o", "ò": "o", "ö": "o", "ô": "o",
"ú": "u", "ù": "u", "ü": "u", "û": "u",
"ý": "y", "ỳ": "y", "ÿ": "y", "ŷ": "y",
# Misc Letters
"Å": "AA",
"å": "aa",
"Æ": "AE",
"æ": "ae",
"Œ": "OE",
"œ": "oe",
"ẞ": "ss",
"ß": "ss",
"Ç": "C",
"ç": "c",
"Ñ": "N",
"ñ": "n",
"Ø": "O",
"ø": "o",
# Punctuation
"¡": "!",
"¿": "?",
"–": "--",
"—": "--",
"―": "--",
"«": "<<",
"»": ">>",
"‘": "'",
"’": "'",
"‚": ",",
"‛": "'",
"“": '"',
"”": '"',
"„": ",,",
"‟": '"',
"‹": "<",
"›": ">",
"⹂": ",,",
"「": "|-",
"」": "-|",
"『": "|-",
"』": "-|",
"〝": '"',
"〞": '"',
"〟": ",,",
"﹁": "-|",
"﹂": "|-",
"﹃": "-|",
"﹄": "|-",
""": '"',
"'": "'",
"「": "|-",
"」": "-|",
# Mathematics
"≠": "!=",
"≤": "<=",
"≥": ">=",
"±": "+-",
"∓": "-+",
"×": "x",
"·": ".",
"÷": "/",
"√": "\\/",
"∑": "E",
"≪": "<<", # these are different
"≫": ">>", # from the quotation marks
# Misc
"ª": "a",
"º": "o",
"°": "o",
"µ": "u",
"ı": "i",
"†": "t",
"©": "(c)",
"®": "(R)",
"℠": "(SM)",
"™": "(TM)",
# Polish
"Ą": "A",
"ą": "a",
"Ć": "C",
"ć": "c",
"Ę": "E",
"ę": "e",
"Ł": "L",
"ł": "l",
"Ń": "N",
"ń": "n",
"Ó": "O",
"ó": "o",
"Ś": "S",
"ś": "s",
"Ź": "Z",
"ź": "z",
"Ż": "Z",
"ż": "z",
# My others
"μ": "u",
"õ": "o",
"ọ": "o",
"ő": "o",
"Ž": "Z",
"þ": "p",
"Þ": "P",
"ð": "d",
"č": "c",
"š": "s",
"ș": "s",
"♥": "-",
"ã": "a",
"ŵ": "w",
"→": "-",
"・": "-",
"☆": "-",
"★": "-",
"/": ",",
"*": ".",
":": "-",
">": "(",
"<": ")",
}
FILTER_TAGS = [
"album",
"artist",
"title",
]
def sanitize(char):
if char in CHAR_TABLE:
return CHAR_TABLE[char]
return char
def ascii(word):
return "".join(sanitize(char) for char in word)
def main(tagger, metadata, *args):
for name, value in metadata.rawitems():
if name in FILTER_TAGS:
metadata[name] = [ascii(x) for x in value]
metadata.register_track_metadata_processor(main)
metadata.register_album_metadata_processor(main)