That’s totally got be me, sorry. I’ve been adding a bunch of audiobooks to MusicBrainz recently. Releases from Libro.fm contain chapters split by mp3s, and I’ve been submitting fingerprints for those. A couple of books from the Stormlight Archive I submitted have close to two hundred chapters each.
Sorry to increase your workload. Let me know if there’s anything I can do that would help.
I’m struggling to get any new AcoustIDs added - even some that I submitted ~2 weeks ago aren’t showing up. Is it possible they’re still queued, or should I assume they’re lost and resubmit?
I just submitted a few more and noted one of the IDs so I can check the submission_status API over the next few days/weeks (currently pending, which makes sense).
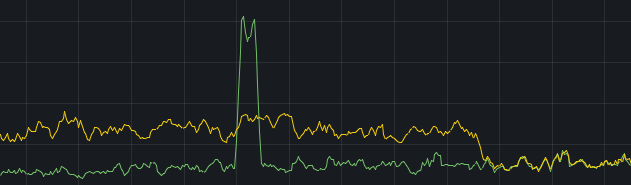
In the first few days, the acoustid server response was much better. The acoustids were visible in MusicBrainz in a flash when I sent new MusicBrainz pairings to AcoustID.
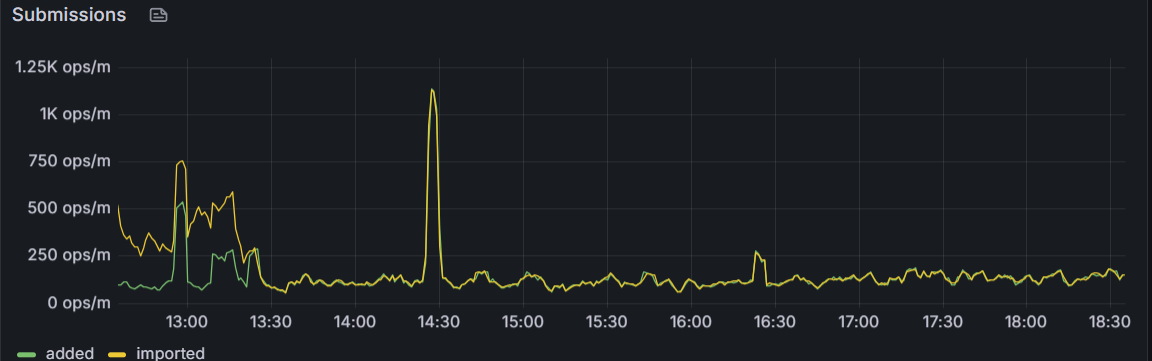
At the moment there is still a strong, strong delay
This is how it looks if the import process is able to handle all new submissions
(since about 13.30 Uhr on this chart) - the yellow and green line are pretty equal.
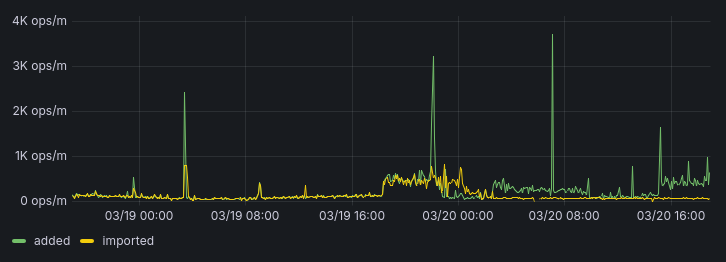
Since a few hours ago I noticed submitted AcoustIDs being delayed again, and the API occasionally returning an internal server error page. Just a heads up in case that’s not just a temporary glitch that resolves itself.
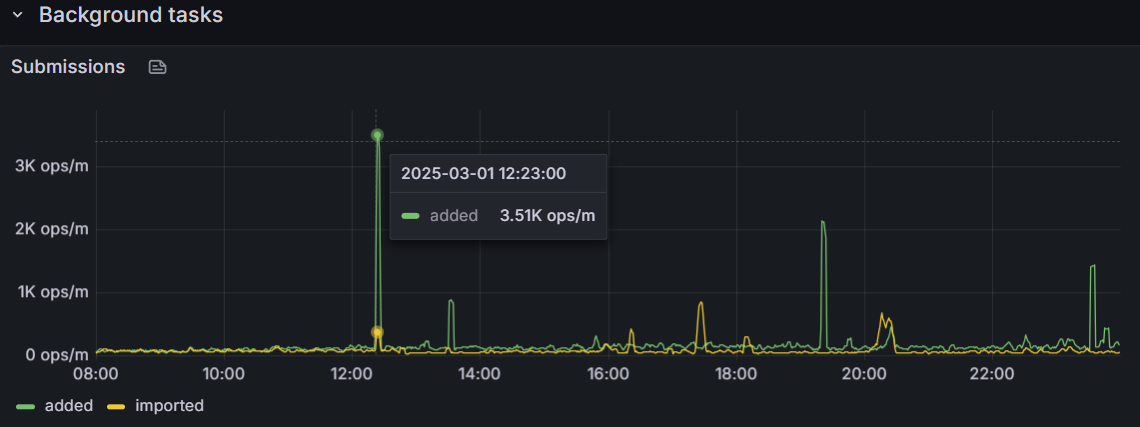
You can see that on the graphics:
After a huge pike at 2025-03-01 12:23:00 there are continuously added more submissions that can not be imported at the same time.
“Added” are AcoustIDs submitted to the server, and “imported” are those imported into the database, is what I think it means. Not sure why importing lags behind, for the first burst it kept up with the increased submissions, but then it went back down to the regular level while submissions spiked again.
The problem with this scenario is that as more and more data is added (to the processing queue = green) than is imported (into the database = yellow), the time it takes for the newly added data to become visible to us becomes longer and longer.
For transparency, the reason this is happening is because there is an avalanche effect. Once there is a big peak in new submissions, processing submissions gets slower, because I initially wanted to keep the system as simple as possible and use PostgreSQL as a message queue for submissions. However, when the number of unprocessed submissions gets too high, it just takes much longer to actually read from the queue (with all the necessary locking enforced).
I’m in the process of doing fairly big changes to the internal architecture, and especially submissions will be moved from PostgreSQL to NATS JetStream queue, which should be much more efficient to consume, and definitely not depending on how long the queue is. I already made a lot of preparations for this to happen, because it needed to ensure the submit API includes almost no logic beyond basic validation. It does not try to touch any database except for authentication and the database where it needs to write the queue. The only remaining thing for now is to change the flow write to NATs only, and have an export from NATs to PostgreSQL simply for historical purposes / easier backup.