What I am trying to do:
I am trying to add a Japanese album to my music collection. The album has track names officially in Japanese, but since I don’t read Japanese well I would like to have the track titles in, what we call “romanji”, that is the title translated to latin letters so foreigners can read it.
What I have done:
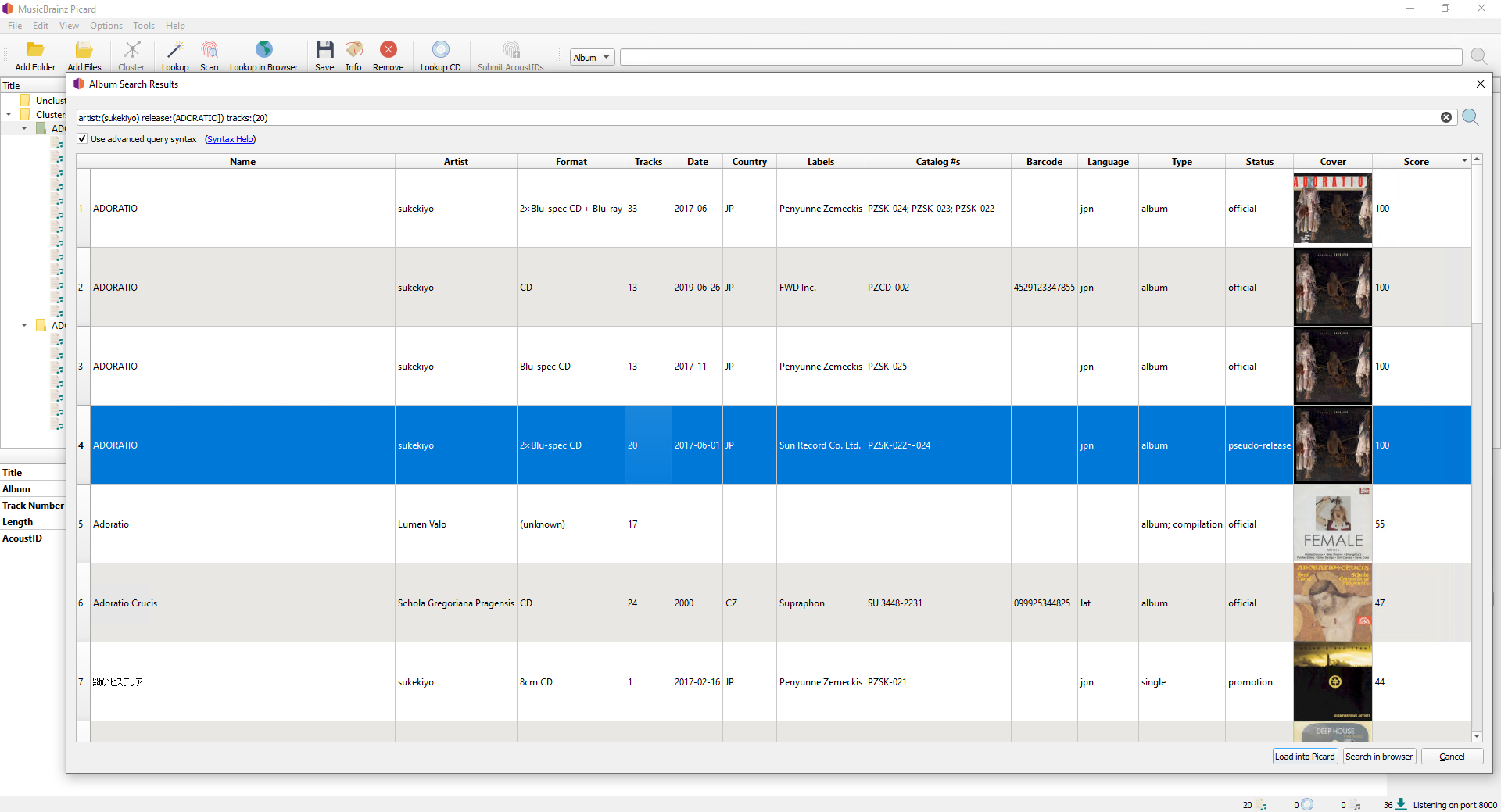
There was no release on Music Brainz that had the album tracks with romanji/latin letters. So I decided to add a new release, but link each track to existing releases.
What I expect to happen:
After adding the release to Music Brainz I proceeded to add the music to Picard. I did a manual search for reid:(8e313864-c3b5-4cef-8081-893ceee7846d) to match the release I just added to Music Brainz. So now I expected all the track titles to format into romanji (latin translation).
What is happening:
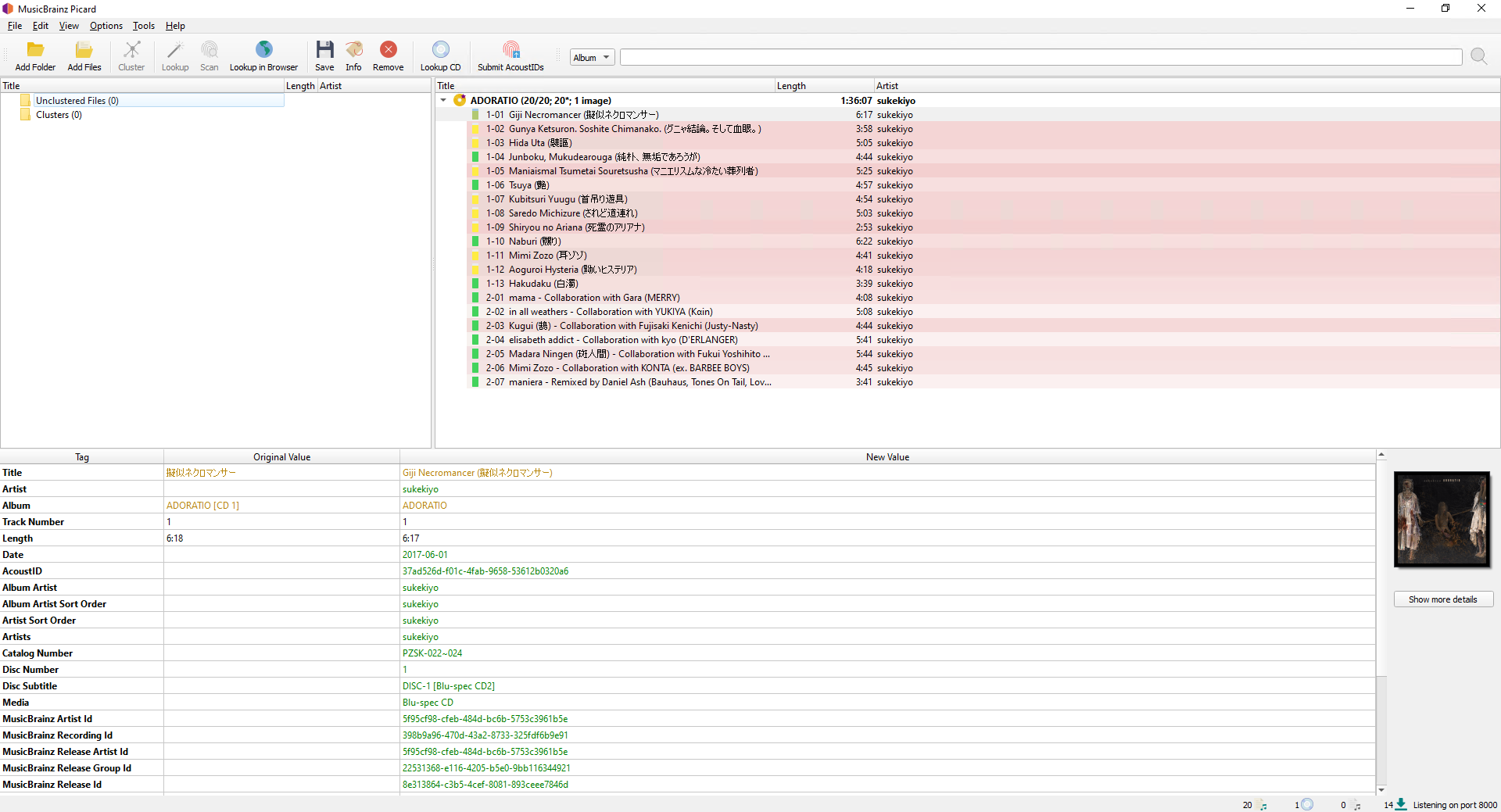
In Picard however, the tracks does not get romanji track names. They are still formatted in Japanese.
What I have tried:
I tried to remove the relationship type, but to no avail. The tracks still show up in Japanese.
I’m not entirely sure what happened here, but you added separate recordings for the translated track titles in edit #66811795 and I think this is where it went wrong the first time. But actually this is not how this should be handled, the recordings need to be merged again.
But for some other notes:
The pseudo release with the transliteration should be put into the same release group. I added a merge request in edit #66813572
The pseudo release should be linked to the original with a “transliterated/translated track listings” relationship. I added this relationship
I have entered merge edits for the recording again. Once the merged are through it could be you get the same behavior in Picard again, but I actually don’t know why. Picard is supposed to use the track titles, not the recording titles.
But maybe you have some plugin which is causing this? Which plugins do you have enabled?
Translating based on pseudo release is not yet supported, unfortunately. There is a very old ticket https://tickets.metabrainz.org/browse/PICARD-145 about this, but so far nobody has put any work into this.
I personally would rather see translations using recording aliases, btw. I find this a more useful concept than pseudo releases. But I understand i is currently rarely used in the database.
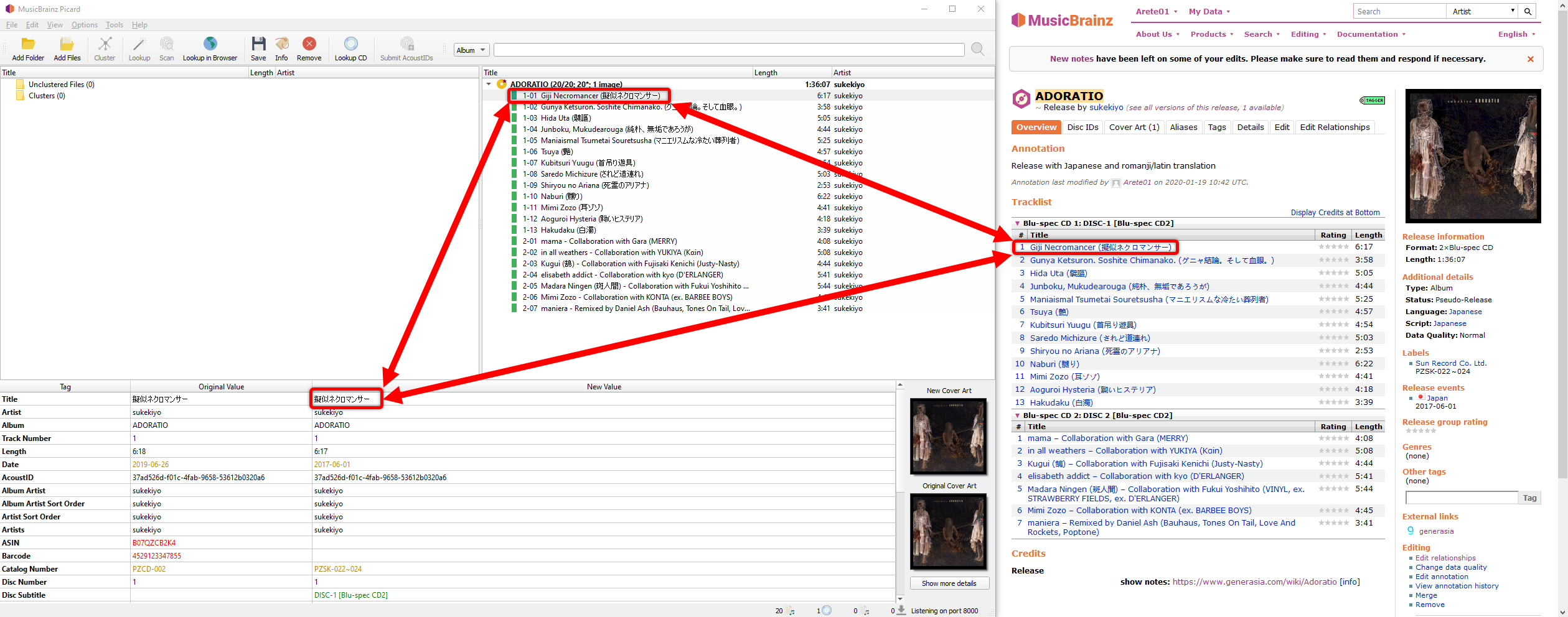
 Perhaps it just needed some time?
Perhaps it just needed some time?