Hello there, I was wondering if it were possible to keep the multi-value tags as-is without combining them into a single field in Picard. Out of curiosity, why are they merged in the first place? If certain artists do choose to use separators like ‘/’, ’ / ’ or ‘;’ for stylistic (or other) purposes, then the whole point of having fields like ‘Artists’ becomes invalid. Surely, using some obscure separator can mitigate possible clashes with artist names that may have special characters, but even that’s not absolute.
I’m not sure I understand what you’re asking for here. Are you suggesting that Picard write each of the artists to the same tag name to create multiple tags with the same name? I’m not sure that works. What might work is a tagging script that creates new tags such as “Artist_01”, “Artist_02”, etc. I think this could be done with something like:
$noop( Create a separate tag for each artist listed for the
track as 'Artist_1', 'Artist_2', etc. )
$foreach(%artists%,$set(Artist_%_loop_count%,%_loop_value%))
That should also retain any ‘;’ or ‘/’ characters in the artist’s name.
Yes, that’s what I meant. ID3 actually supports multi-value tags with the same field name. For example, the have a look at the ARTISTS tag(s) in this picture.
I agree that not all programs might be able to read this properly, but I feel that multiple null-separated values make it far easier and more accurate for programs (that do support it) to discern between the separate values. Maybe not as a standard, but it could be introduced as an option.
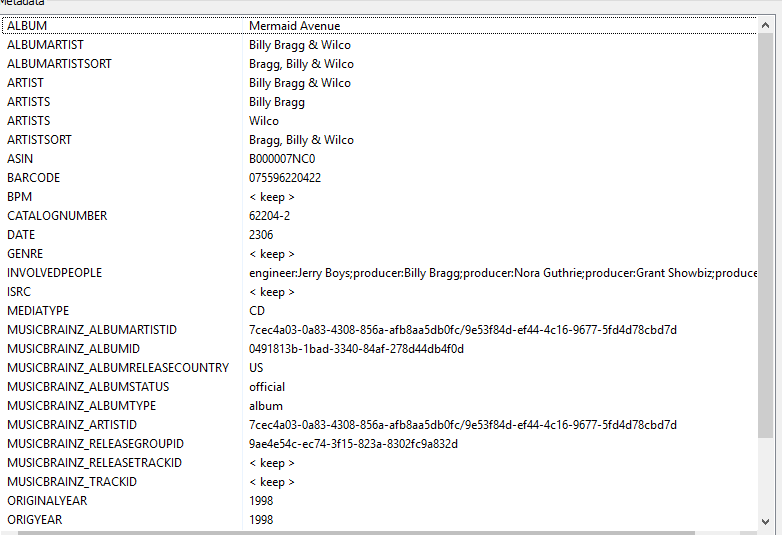{kind=link}
ID3 only supports multiple values per tag with the ID3v2.4 version, which despite being around for a good while now is poorly supported by many applications. And even with ID3v2.4, it does not officially support multiple values for individual instances of TXXX (extended text) frames, which are necessary since ID3 obviously did not reserve tags for all of the data MusicBrainz provides.
The world of file metadata would be a much be better place if ID3 would be phased out in favor of universal Vorbis Comment-style metadata sections (which are just plain key-value pairs and don’t pretend to define an exhaustive set of fields), but that probably won’t happen.
Finally, even if you have the technical ability to store the artists as distinct tag values, the join phrases are semantically meaningful (“Artist A feat. Artist B” is not the same as “Artist A & Artist B”).
3 Likes
I see. While I don’t think the ‘ARTISTS’ tag in particular is meant for preserving the semantic structure (or at least, that’s what Picard implies by mushing every artist into the same field), especially since other tags like ‘ARTIST’ can do that very well, the reason behind my question was basically a way to access individual artists that contributed to a track without having to deal with potential edge cases that a separator-based formatting can introduce. The most obvious example is AC/DC if a slash is used as a separator. There would be no proper disambiguation between AC/DC and something like toe/Chara, where the former is a single artist and the latter are two separate artists.
But I do understand the complications involved with ID3 in general. So I’m assuming that the only solution (hacky, and not foolproof) for me to use is a more obscure separator, then? (For example, " \\ ")
Picard does store both a single value artist tag and multi-value artists as seen in your screen shot. As mentioned above ID3 v2.3 has no support for multiple values. But you can configure Picard to use ID3 v2.4 instead. You also can configure the separator used for ID3 v2.3.
3 Likes
Thanks, this was what I was looking for. Not sure how MP3Tag manages to add multiple values to the same field even in v2.3 (There are FF FE bytes separating the multiple values but perhaps that’s an unofficial implementation). I guess I’ll use v2.4 anyway since my players seem to support it.
1 Like
Using a “weird” separator is probably the only option, yes. But you can’t get too weird either, e.g. the way Picard writes multi-value tags into TXXX frames on ID3v2.4 utilizes null-separators, which causes some ID3 parsers to only read the first value and ignore the rest.
FF FE is a special Unicode “character” called “Byte Order Mark”, which indicates the way bytes are laid out in a given text stream (the reverse, FE FF, is guaranteed not to be valid UTF-16). However, the “recommended” way to deal with byte order marks that do not appear as the first character in a string is to treat them as “zero-width non-breaking spaces”, so you may get applications that jumble individual together with no visible separation.
3 Likes