In a former life (in about 2001 - I was in this role on 9/11 and so the timescales are quite memorable) I was actually a complex fuzzy search engine expert.
IMO (and remember it is more than two decades since I was an expert) the use of the OR for selecting records is the correct one, and the magic is about how you then score each of the search results and sort them in decreasing score before you select the top 50 or 100 to send to Picard.
It is complex enough doing the scoring if you search for exact matches on each of the fields (with “OR”) but it gets even more complicated if each of the search values is fuzzy matched itself.
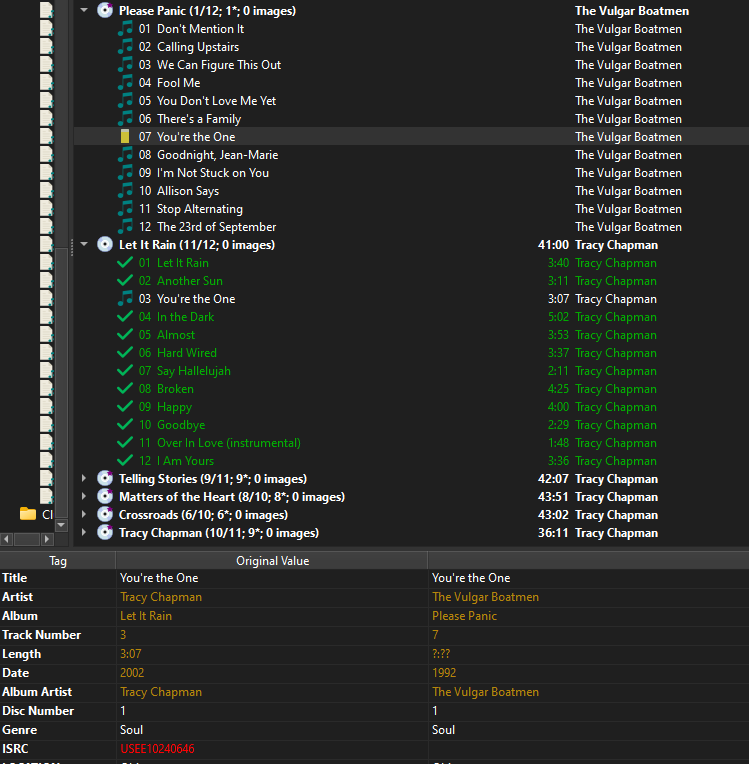
So if the track name you are searching on is “You’re the one” you might have synonyms of “Your” and “You are” for the word “You’re”, so that the search becomes track = 'you're the one' OR track = 'your the one' or track = 'you are the one' or possibly (track = '%you're %' OR track = '%your %' OR track = '%you are %') AND track = '% the %' AND track = '% one%'. And of course you will need to simplify any punctuational synonyms or remove all punctuation from both search and data values.
The way we did it was using SQL Stored Procedures - from memory, we would select each of the search terms separately, inserting the index-id and a weighted score for that term into a temporary table, and then we would then group by index-id and sum the scores, sort descending by score and output the top 50 results.
So in this example the SQL might be something along the lines of:
SELECT track_id, 10000 AS score FROM tracks
WHERE track = "you're the one" AND artist = "Tracy Chapman" AND release = "Let It Rain" AND tnum = 3 AND tracks = 12 AND qdur BETWEEN 90 AND 96
INSERT INTO temp;
SELECT track_id, 1000 AS score FROM tracks
WHERE isrc ="USEE10240646"
INSERT INTO temp;
SELECT track_id, 50 AS score FROM tracks
WHERE track = "you're the one"
INSERT INTO temp;
SELECT track_id, 30 AS score FROM tracks
WHERE track = "your the one" or track = "you are the one"
INSERT INTO temp;
SELECT track_id, 50 AS score FROM tracks
WHERE artist = "Tracy Chapman"
INSERT INTO temp;
SELECT track_id, 30 AS score FROM tracks
WHERE artist = "Tracey Chapman" OR artist = "Tracy Chappman" OR artist = "Tracey Chappman"
INSERT INTO temp;
SELECT track_id, 40 AS score FROM tracks
WHERE release = "Let It Rain" AND tnum = 3 AND tracks = 12 AND qdur BETWEEN 90 AND 96
INSERT INTO temp;
SELECT FIRST 50 ROWS ONLY track_id, SUM(score) FROM temp
GROUP BY track_id
ORDER BY SUM(score) DESC;
IIRC, the temp table was an in-memory table, and each transaction had its own temp table. And because this is all done in one go on the SQL server using Stored Procedures and is not transmitting the full interim results back to the app server but rather only the top 50 scores, the performance was excellent.
(For the specific application domain I designed this for in 2001, there were several additional rules that were applied to the interim table to remove specific combinations of results that we deemed false positives before the scores were summarised and results returned. So you can see that using this style of approach there is a lot of flexibility on weightings and business rules etc. And the users were absolutely amazed by the accuracy of the search results - which were way better than the much simpler search engine they previously had. Unfortunately, when I went back several years later to visit my friends there, the system had been replaced again by something much simpler and the improvements had been lost. Ah well.)