Hi there, as I am new to Picard, I tried reading through the forums but can’t seem to find a relevant question.
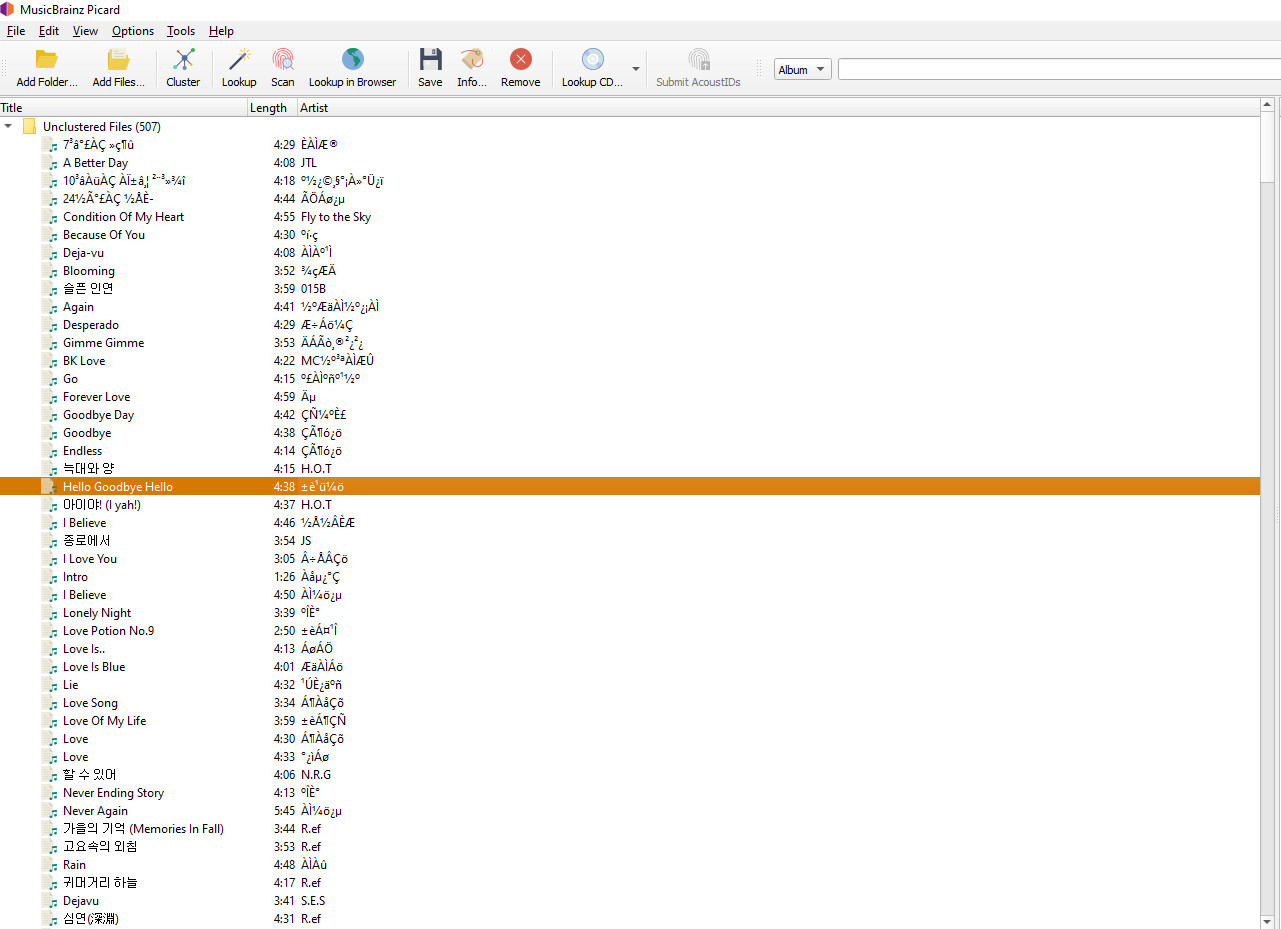
When opening two sets of music collections, I see that one comes out in Korean correctly (i.e. 안녕하세요). However, some come out in this: Â÷ÅÂÇö.
I am not understanding why some would come out correctly while others won’t. I checked my computer language settings and I think everything is correct.
My goal is to just to rename my collection with %artist% - %title% but it is renaming it into this format: Â÷ÅÂÇö which is making my collection illegible.
Because there are multiple steps between someone entering an album’s details on MusicBrainz and Picard applying that data to your files, understanding where it has gone wrong can be difficult.
It is also possible (but unlikely) that your file naming script can be causing it.
Secondly it will depend on the specific data held in MusicBrainz for a specific Release/Album or Recording/Track. To take a real look, the team will need some specific examples of albums or tracks that are exhibiting this behaviour.
How does the data look in Picard before saving? What file format is this? If it is MP3, what are your settings in Options > Tags > ID3? If those are WAVE files, what are your settings in Tags > WAVE?
Please note that in case of WAVE Windows does only support reading tags from RIFF INFO tags (and not the ID3 tags Picard also writes), and Windows does not support Unicode in RIFF INFO.