TL;DR: Picard is doing what it is supposed to do when picking the best match, but the algorithm could maybe be improved a bit.
This is a bit of an odd case, but essentially Picard is exactly doing what I assumed originally: The lookup for your file’s acoustic fingerprint yields two AcoustIDs:
- f91c7840-5842-4577-814b-056e97a194e7 with a similarity score of 0.976266
- 181f9faa-dd91-47e0-b788-b38691c384df with a similarity score of 0.939082
It’s one of the cases where AcoustID finds more than one AcoustID that matches the fingerprint good enough that it considers them as potential matches.
The second recording at time of your response was only linked to the MB recording 626a77c0-6fb4-42f9-9448-5d4d144ee5fe, with a submission count of 4.
The first AcoustID is also linked to the same recording (submission count 50). But it is also linked to additional recordings:
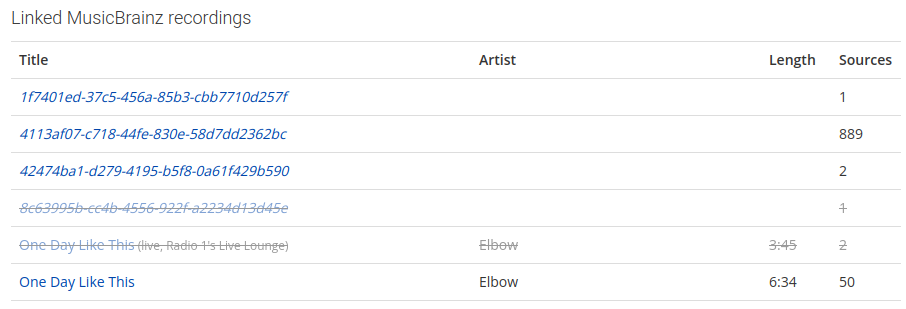
{
"id": "1f7401ed-37c5-456a-85b3-cbb7710d257f",
"sources": 1
},
{
"id": "4113af07-c718-44fe-830e-58d7dd2362bc",
"sources": 889
},
{
"id": "42474ba1-d279-4195-b5f8-0a61f429b590",
"sources": 2
}
All those recording IDs have no metadata associated in the response. That is because they actually don’t exist, they all have been merged into 626a77c0-6fb4-42f9-9448-5d4d144ee5fe.
Now with this result Picard starts to compare your file to the data it got from AcoustID to pick the best matching recording. For this it considers different things, among them:
- The recording metadata compared to existing file metadata
- The matching score of the AcoustIDs
- The submission counts for the recordings
For (1) only the recording 626a77c0-6fb4-42f9-9448-5d4d144ee5fe provides any data, and it is exactly the same for both AcoustIDs, so they both score identical.
(2) has a bit higher score for the first AcoustID (0.976266 vs. 0.939082), so this would give the first AcoustID an advantage.
But the actual reason why the second AcoustID is chosen are the submission counts (3). The idea here is that a high submission count gives high confidence that the recording is correctly link. This is supposed to filter out wrongly matched recordings. For this a submission count is considered relative to the most submissions for any recording of the AcoustID. Now let’s look again at the submission counts for the first AcoustID:
The recording 626a77c0-6fb4-42f9-9448-5d4d144ee5fe has a submission count of 50, that’s actually a lot. But the most submissions are 889 for the no longer existing 4113af07-c718-44fe-830e-58d7dd2362bc. That gives this recording match a submission count score of 50 / 889 ~ 0.0562.
Compare to the second AcoustID where 626a77c0-6fb4-42f9-9448-5d4d144ee5fe has only 4 submissions, but that’s the most common, that gives a score of 4 /4 = 1.0. Tada, better match!
Now not sure what to do about that really. Ideally AcoustID would handle this somehow, maybe actually merge the submissions for merged recordings. Giving a recording ID of a no longer existing recording is not really useful. If the first AcoustID would instead give only 626a77c0-6fb4-42f9-9448-5d4d144ee5fe as a result with combined submission of 889 + 50 + 2 +1 the this would be a clear result.
But since I rather focus on what I can actually change in Picard, some options:
- Picard could ignore recordings that are just the recording ID without any extra metadata completely. That would have ignored this extremely high submission count of 889 and have led to a score of 1.0 also for the first recording.
- Instead of considering the submission count relative to the highest submission of the current AcoustID, it could consider the highest submission count in the result overall. So in this case all submission counts would have been compared to 889, which would result in a score of 4 / 889 ~ 0.0045 for the second.
- A combination of both of the above: Ignore the recording ID only results, but then compare to the highest submission overall.
- Picard could lookup the recordings to find out if there have been merges. But that’s not really a realistic option because of the overhead of multiple additional requests being required. So scratch that idea.
Option 1. has the disadvantage that it discards in this case a high number of submissions. Option 2 has the disadvantage that it could emphasize wrongly matched AcoustIDs disproportionately. E.g. consider you have a less popular song, that matches one AcoustID near perfectly, and another one of a more popular song fair enough but not really good. But the perfect match has only very few submissions, whereas the popular song as hundreds. Option 3 has both issues.
I would actually tend to implement option 1. In all cases you can probably construct some specific case where the result will not be exactly what would be ideally expected, though.