Personal information
Nickname: kosmasK
IRC nick: kosmasK
Email: kosmas.kritsis@gmail.com
GitHub: kosmasK · GitHub
Skype: kosmaskritsis
Facebook: https://www.facebook.com/kosmas.kritsis
Proposal
##Overview
ListenBrainz currently stores information retrieved from the Last.fm web service, which by its side receive data from different sources (i.e. iTunes, Spotify, VLC and browser plug-ins etc.) by utilizing its srobbler app. Therefore unreliable and messy info are imported to the LB server, thus emerging the need for an additional integral system able to address this issue, the MessyBrainz project, that aims on filtering out and organizing all the incoming listens. By taking the advantage of the MusicBrainz database (MBIDs), we can have a first approach on filtering and coupling entries of the MessyBrainz to MusicBrainz entities. Furthermore, for the listens with no MBIDs, we can estimate the corresponding MusicBrainz recordings by processing the rest of their metadata. Finally, the entries that are not matched to a specific MBID recording, would be considered as “messy” and remain on that state. Sounds promising but still remains a challenging task.
##Keypoints
-
Filter the existing entries by their metadata and data. (ticket LB-53)
-
Filter according to MBIDs existence
-
Scrape the MusicBrainz server for matching the MBIDs (recording, release, artist)
similar to:
metadb/metadb/scrapers/musicbrainz.py at master · kosmasK/metadb · GitHub -
For entries with 100% matching, they are annotated and considered “clean”
-
Apply text processing and information retrieval according to the rest of the meta data
(correction on mistyped titles and names, look for song duration and year, look through the tags)
However some of the issues and problems that exist are presented by Alastairp in:
Design
Up to the current day, LB stores each song that exist on a users payload directly to the MessyBrainz database by assigning a specific MessyBrainzID. Therefore multiple instances may be duplicated, and specially those that do not include any MBID in their metadata. By introducing a validation method able to scrape through the MusicBrainz web server would make possible to much all those entries that have a recording MBID. These entries would be updated and stored to a “clean” cluster in the DB. The rest of the messy entries will be updated with possible extra metadata resulted from the scraping and will be stored again to the “messy” recording cluster. Figure 1 illustrates those processes in a macro scale.

**Figure 1.**MessyBrainz entries validation
The validations process should be able to address different scenarios according to the variety of the stored data. If we are provided with a release MBID it would be the most easy way to update and validate the listen data. On the other hand LB server accepts as minimal listen payload only the artist name and track title, thus being impossible to match such entries to specific releases. However, by filtering and updating all those entries that have MBIDs we can use it as further ground truth for estimating and detecting the most possible match.
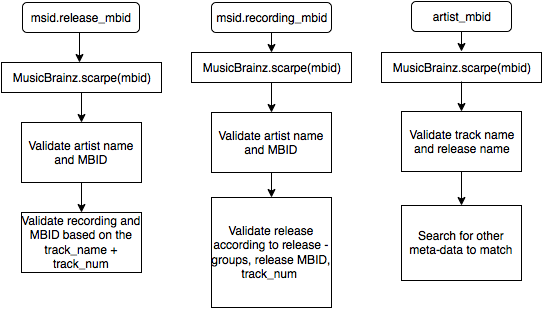
Figure 2. Example of validation scenarios according to the existence of different MBIDs in a “messy” listen
##Week Scheduling##
Community Bond: Speak with the mentors, get to know the rest of the participants, readjust the project plan, get more familiar with the LB and MessyBrainz servers, data analysis.
Week 1 (23 May): Organize the data based on the existence of MBIDs (based on google BigQuery)
Week 2 (30 May): Implement the scraping according to Release MBIDs and update the rest of the entries with artist and track MBIDs
Week 3 (6 June): Implement the scraping according to Recording MBIDs and update the rest of the entries with artist and track tags
Week 4 (13 June): Implement the scraping according to Artist MBIDs and update the data entries
Mid term evaluation week (20 - 27 June): Testing the robustness of our updates and reanalyze our dataset for the next phase.
Week 5 (27 June): Organize the data based on the Spotify-Id existance (based on google BigQuery)
Week 6 (4 July): build a scraper for Spotify in order to retrieve info for the corresponding id
Week 7 (11 July): Use the Spotify scraper to update our entries with new metadata
Week 8 (18 July): Analyze the entries for missing information
Week 9 (25 July): Text information retrieval on the metadata of the entries in order to match similar entries
Week 10 (1 August): Select the correct features and build a classifier if possible for organizing the rest of the data.
Week 11 (8 Augutst): Test the classification model with data groups with different quality.
Final week (15 - 22 August): Finalize the project and work on the documentation.
After GSoC: Stay connected with the MetaBrainz network and continue contributing on other tickets and ideas of the project.
Detailed information about yourself
Computer: I have a MacBookPro i7 2.9GHz with 4Gb Ram and 500 GB HDD
Programming Experience: My first experience with programming was with Delphi in 1999. Ever since I have experience with most of the famous languages (C, C++, Python, Java, Perl, JS, bash scripting etc.)
Type of music: Carbon Based Lifeforms - MusicBrainz (Carbon Based Lifeforms), Allah-Las - MusicBrainz (Allah-Las), Release group “Jazzmatazz, Volume 1” by Guru - MusicBrainz (Guru’s Jazzmatazz), Shawn Lee - MusicBrainz (Shawn Lee)
Aspects of interest for the ListenBrainz: That its goal is to provide a recommendations system for music. Personally most of the music that I have search for it was suggested in the related songs list of the different online services.
**MusicBrainz tagging:**I have used Picard to tag some unknown music which where correctly annotated based on the AcoustID fingerprinting.
Contribution to other Open Source projects: Not any experience on such large scale projects. Some coding examples can be found in my GitHub profile.
Programming projects in free time: Most of the programming that i was interested in had to deal with sound including Pure Data patches and JS Web Audio api as well as arduino projects.
Time availability: Since I am currently studying my M.Sc. degree I would be able to spent 5 hours per day. After mid June I would be totally devoted to the GSoC project

