The ListenBrainz Session Viewer (Dataset hoster: sessions-viewer) allows users to view the listens of the given time period for a user distributed into sessions.
Rationale
To build recommendations and other music discovery features, we need multiple sources of data. One possible approach we are currently investigating is assigning similarity scores to recordings based on user listening histories.
To do this, we intend to group users’ listens into “sessions”. All the recordings for which we have listens in a particular session are considered to similar. Then, we aggregate the number of times various recording pairs occur across users and sessions. The aggregated count represents the similarity score of the recording pair.
There are many variations possible on this algorithm to refine the similarity scores. For instance, we could make the scores weighted giving higher preference to recordings which were listened close to each other than those far from each other in a session. We could also try to figure out if a recording was skipped and exclude it from the session so on.
However, calculating the actual similarities is a bit far. For now, we have built the sessions-viewer tool to explore user listening sessions, discover insights and assist us in working on the similarity calculation algorithm.
We would like you to use the tool and share your thoughts on it. We are also looking for feedback on use cases for this data. Also, feel free to share any other suggestions you have about calculating recording similarities. However, please do keep in mind that all of this is in an exploratory phase currently.
Description and Usage
Listens are considered to belong to same session if the time difference between any two consecutive listens in that set is less than a given threshold. The difference takes into consideration the duration of the recording listened. If the duration of the recording is unavailable in MB and the listen metadata, it is assumed to be 180s.
The viewer takes 4 inputs.
- user_name: the ListenBrainz user name of the user you want to view sessions for
- from_ts and to_ts: timestamps to specify the range of time in which listens are shown. These fields accept a UNIX timestamp. You can calculate these for the time period of your choice using https://www.epochconverter.com/ or any other website/tool of your choice.
The maximum allowed range for from_ts and to_ts is 30 days currently. If the user entered range spans more than 30 days, it will automatically be clipped to 30 days. - threshold: the minimum time difference between listens to demarcate a session in seconds.
Example Usage:
1.
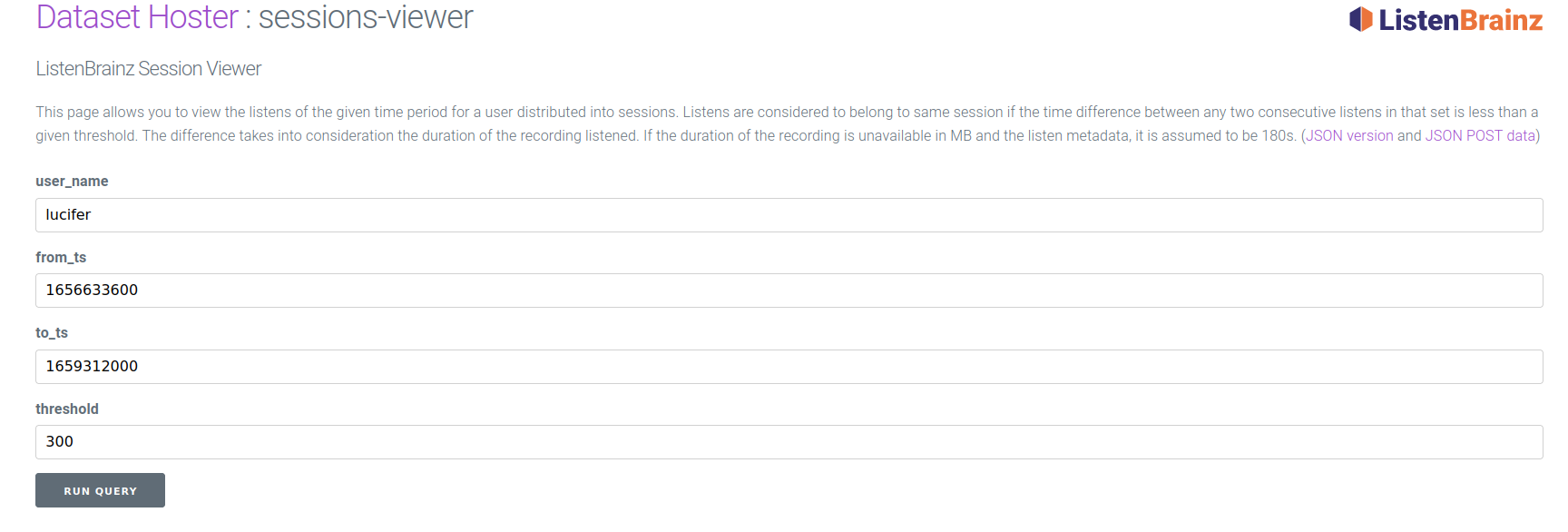
2. lucifer’s listen session example
You can also load a session for playing on the ListenBrainz website (with some caveats) by clicking on the Open as Playlist button next to it.