So, I’ve been playing around with Picard, and I’m starting to get the hang of it, but there are certain operations that are very tedious to do manually.
I noticed that using the picard CLI, there is a -e flag that seems to let you interact with the current GUI session in a limited capacity. I’m wondering if there is something similar that can be done with the Python API? In other words, can I import picard and then run a set of commands to query or modify the current state of the data loaded in a GUI session?
If not, would this feature be feasible to implement? For instance, if there was a way to add a “-e” command that listed the contents of the unidentified and identified panes in JSON or some other machine readable format, then I could write a program to ingest that, and then perhaps there could be another -e command that staged a modification to an item.
I have a few use cases:
-
Once I have all of the songs sorted into the albums I want to associate them with, I want to automatically change all of the album tags to be consistent. I can currently do this with the GUI by changing the property on each album individually, but I want to do this quickly in a batch operation.
-
Check if songs match more than one album in the identified tree view. Sometimes, I will have a complete album, but two versions will be identified in a scan and half of the songs go in one, and the other half go in the other. I could write a quick program to check for this case and resolve it. There are several other variants of this issue, but this example should illustrate the point.
If such a feature exists, please point me to it. Otherwise, if such a feature is feasible, pointers to entrypoints in the code where I might have a stab at implementing something like this would be helpful.
I see there is a concept of a DataObject, which is probably what I would want to serialize. And I also see that picard.tagger.main seems to be the CLI entry point with commands loaded into picard_args.processable and sent via pipe to Tagger.load_to_picard and eventually Tagger.run_commands, which invokes a method in picard.util.remotecommands.REMOTE_COMMANDS, and that seems to wrap a method in the tagger itself.
So perhaps I would add a method in tagger to “list” contents in the tree views? Then if I get that right, I could write another method to set properties of a DataObject via its serialized id?
That brings me to another question, when I tried pip install -e . to play with picard in development mode that didn’t work. It seems like the setup.py is fairly involved and usage requires a full pip install. I was wondering if there was a way to use development mode so I could reduce iteration time between changes / testing.
There is a lot to unpack here - but overall my personal opinion as an experienced individual Picard user (and not a Picard developer) is:
If you find it tediously repetitive, then you are following the wrong workflow. I see you mention scan, and that is another indication that you are using the wrong workflow as Cluster/Lookup should be the first workflow to try, and this would also likely keep all the files from an album together because Lookup treats a cluster as a release and looks for a matching release, whereas Scan treats each file as an individual file and will pick a separate release for each file, some of which may be the same releases.
- Why are you manually changing tags? Again this is indicative of an issue with your workflow, though not one as blunt as Cluster/Lookup vs. Scan.
All that said, if once you try the recommended workflows you still find you have to do a lot of tedious repetitive things, do come back and explain and we will see whether we can help you further with your workflow or whether there are improvements that can be made to Picard to help you.
The music library I’m organizing is largely unsorted, and tags have been changed by other programs. So I typically do need to use “scan” as the existing metadata is not reliable in many cases. I do use lookup when the data is available.
Another issue is that I have releases that are tagged as belonging to compilations, but I would rather assign them to the album they were originally released in. This requires changing the Album tag. (E.g. I have Rolling Stone’s Top 500 songs, but I want to organize those songs into their original albums). I can typically get the assignment to work by adjusting my preferences in the options (giving more weight to albums over compilations), but I have to manually go through and change every album tag.
Manually changing the Album tag is almost certainly not the best way to do this because the Release-MBID will not be changed alongside. Have you tried right clicking on the release/album and selecting an alternative similar release?
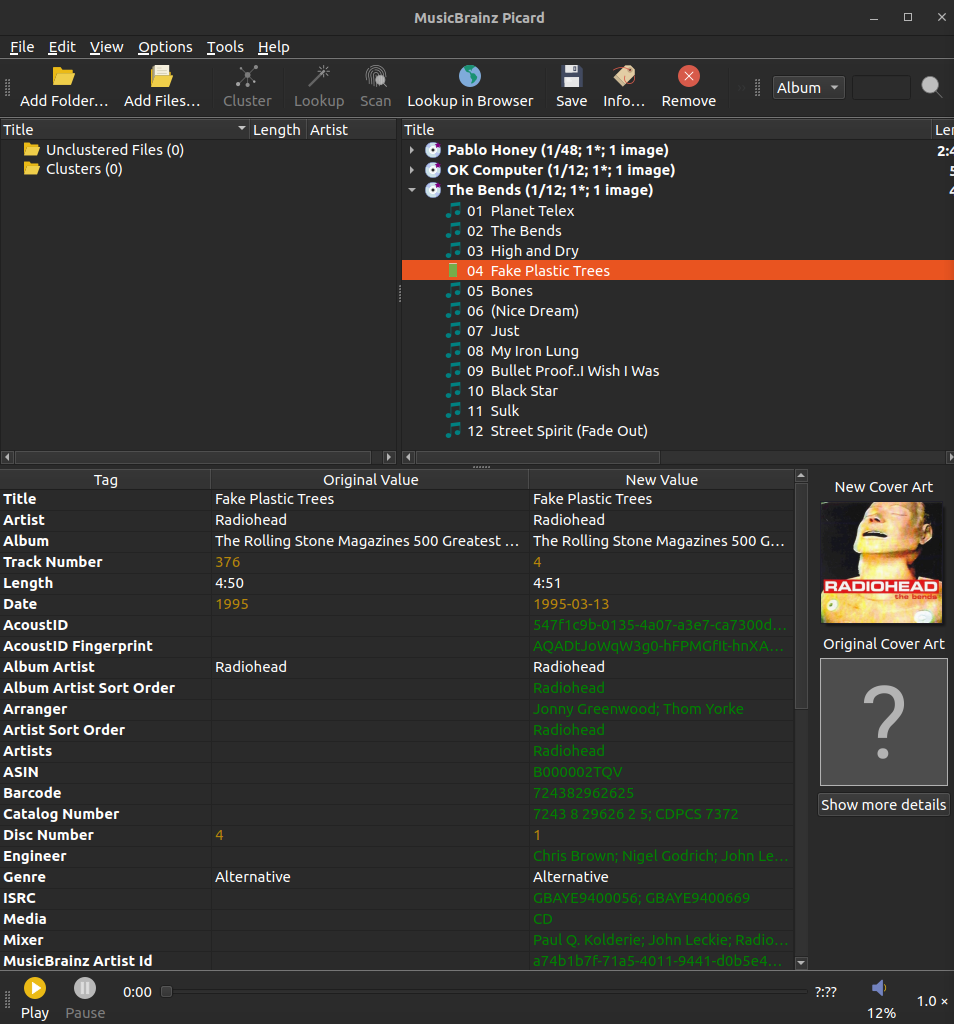
As far as I know that doesn’t work. Here is a concrete example with “Fake Plastic Trees”, which has metadata saying it belongs to “The Rolling Stone Magazines 500 Greatest Songs Of All Time”.
I want to organize it into its original album: “The Bends”, which is done easily enough in this case (although interactive programmatic access would make it easier in other cases).
If I click save here, then it would keep the original album name. As far as I can tell the only way to overwrite the original album tag is to manually set it. This makes a lot of sense as a default behavior, but if I had a programmatic way to check what the current tag is, and then only overwrite it in situations I deem safe, then that would make it a lot easier for me to get these 500 songs tagged with their original album. This is important because jellyfin cares about these tags to organize songs into albums.
Another case this matters is when two songs have different spellings of the same album name. E.g. you might have a song tagged as “OK computer” and one tagged as “OK Computer”, which will be organized into different folders on a filesystem that respects cases. Or sometimes you have a non-case specific differences like “Stevie Nicks: Greatest Hits” and “Stevie Nicks: The Greatest Hits”, which will still be misorganized even on a case insensitive filesystem.
As far as I can tell there is no way in the GUI to do automatic overwrites of metadata like album names… until I right clicked it and saw “Remove from Preserve Tags List”… Well, that works.
Still programmatic access to the data for customized, automated, and repeatable metadata munging would be nice.
Ok - so you want to take a Compilation release and split it apart so that the files are tagged (and possibly organised) into their original albums.
Firstly I guess you need to use Scan rather than Cluster/Lookup in this case. And you need to Scan unclustered files so that they are treated as individual files.
Start by setting Options / Preferred Releases and dragging the Albums all the way to the right and the Compilations all the way to the left. You may want to drag the rest all the way to the left too.
Then load the files into the left hand pane under Unclustered Files - you can drag and drop releases or files etc. to get the files in there.
Then select all the files and click Scan and see what happens…
If this doesn’t work or it works partially, come back and show us the results and ask for more help.
1 Like
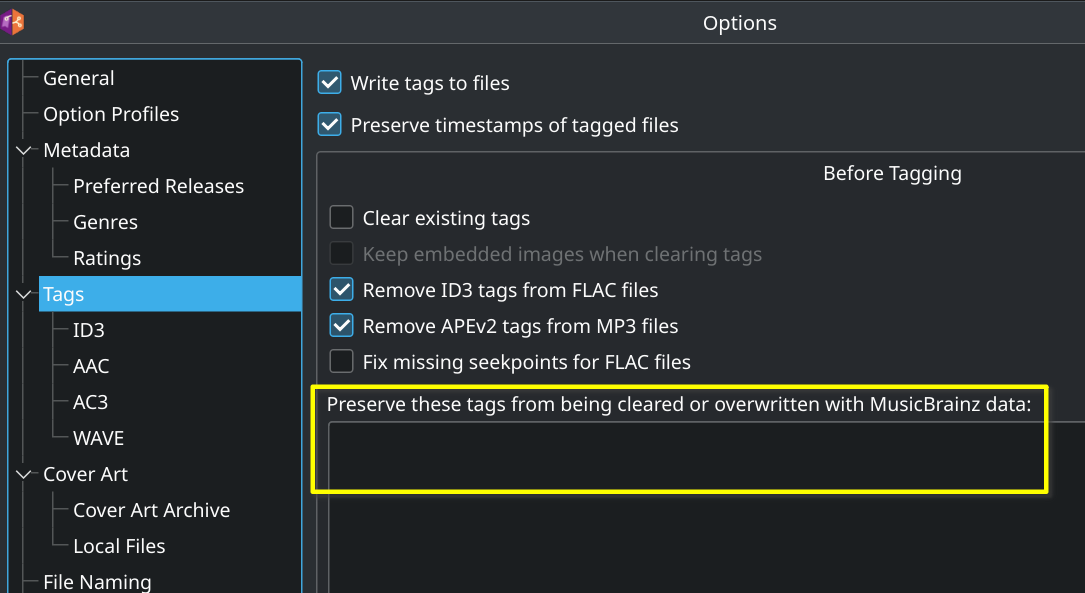
Ahh, I’m guessing you have some tags set as preserve (not sure if there’s a default or not). If you open Options and go to the Tags settings, you should be able to remove them:
That way you won’t have to right-click - it will automatically use the correct tags.
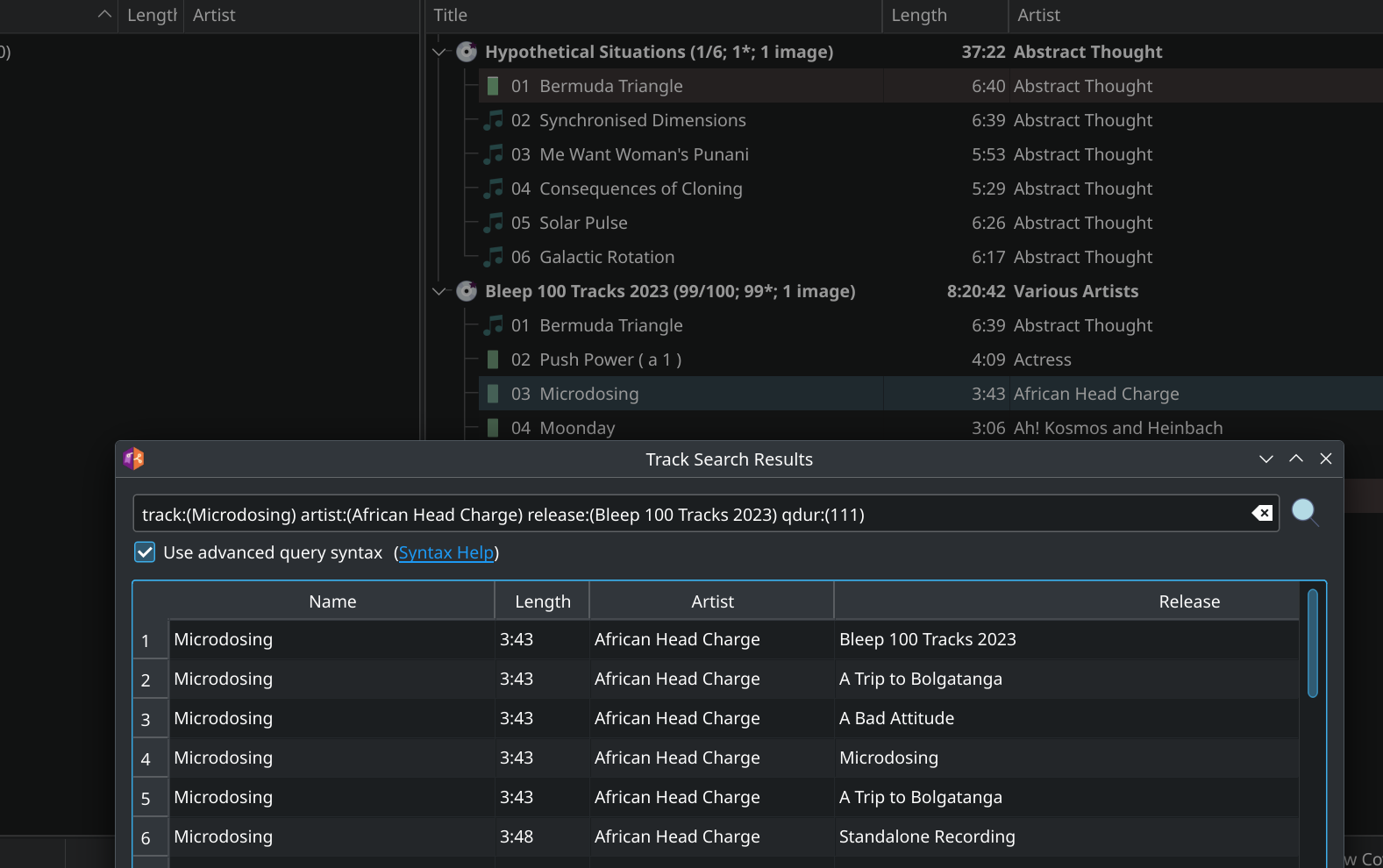
I’ll add that I do this with samplers and the Bleep 100 tracks release. My typical process is to match the compilation and then check for other recordings (ctrl+T).
When you select the release you want, it will load that and move the track to it. Programmatic would be nicer, but for the past few years I was using the process to merge a lot of recordings so manual works better.
Forget that workflow because I don’t think you’re working from an actual compilation but a series (plus it would be a terrible experience with 500 tracks. But you could try doing it through the website. Turn on “Browser Integration” in Picard. Options → Advanced → Network
Install
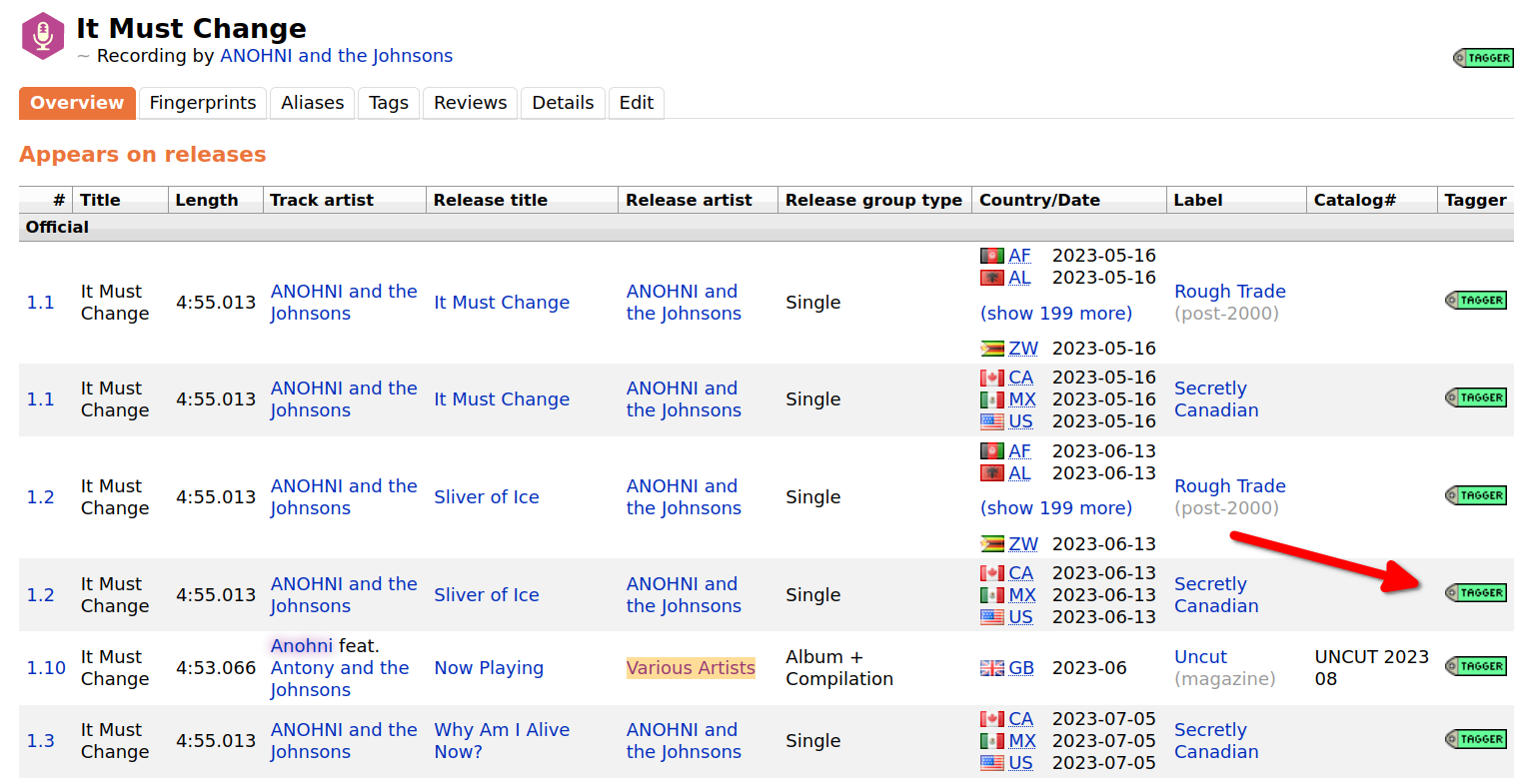
MusicBrainz Magic Tagger Button user script in your browser. A little green
TAGGER button will appear next to releases on MB which will load the release in Picard when you click on it. Now you can go to
Rolling Stone Magazine’s 500 Greatest Songs of All Time and click on the recording. This will take you to a page of that recording on all of the possible release. Look for the one you want and click on the
TAGGER button and then you can drag that track onto the album in Picard.
Maybe still not ideal, but just a suggestion. Either way, make sure you look at the “Preserve these tags…” settings I mention above.