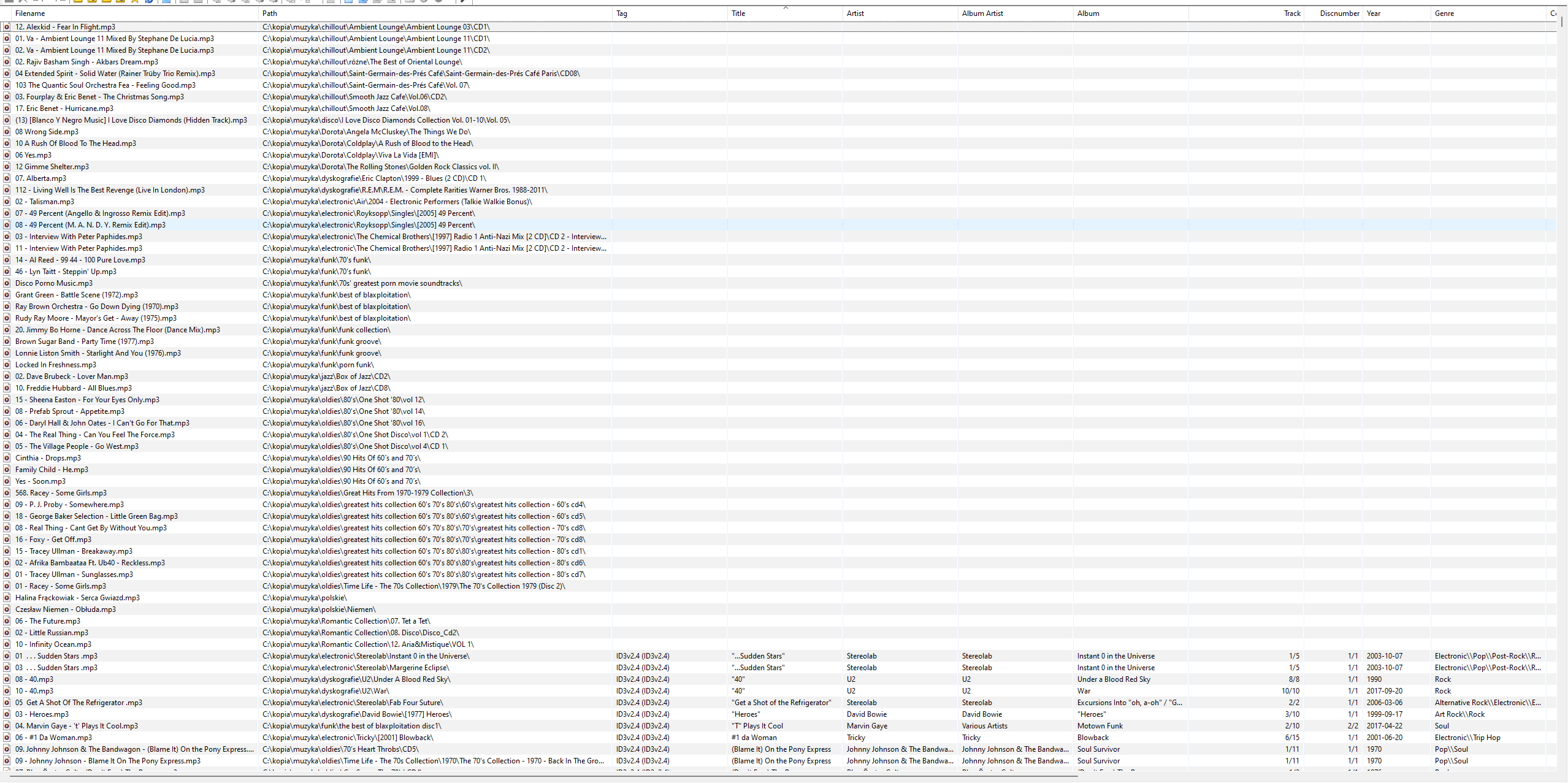
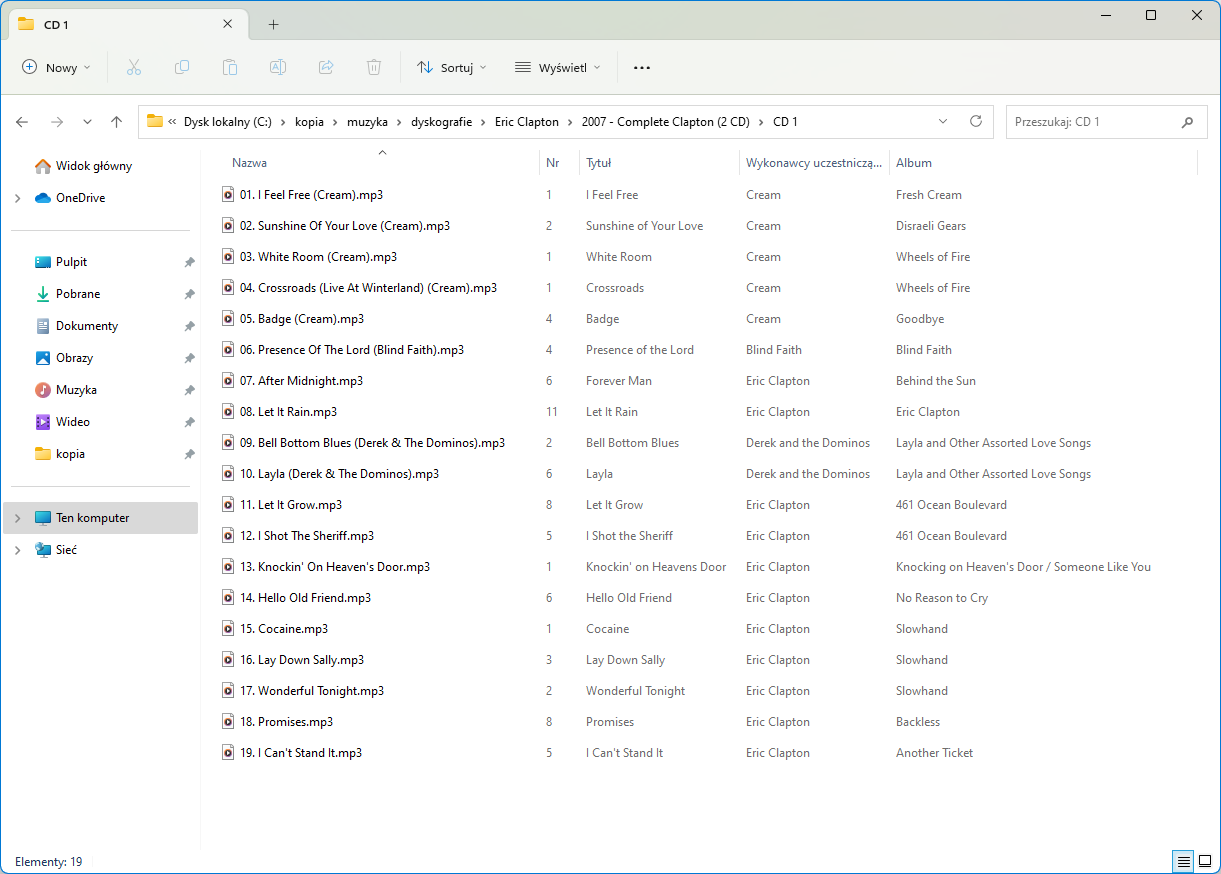
I always do the following with every new Picard release:
I completely remove tags with Mp3Tag
I add this music directory to Picard.
I click Scan.
Only about 50 Unclustered files remain in the left panel
I write down and that’s it.
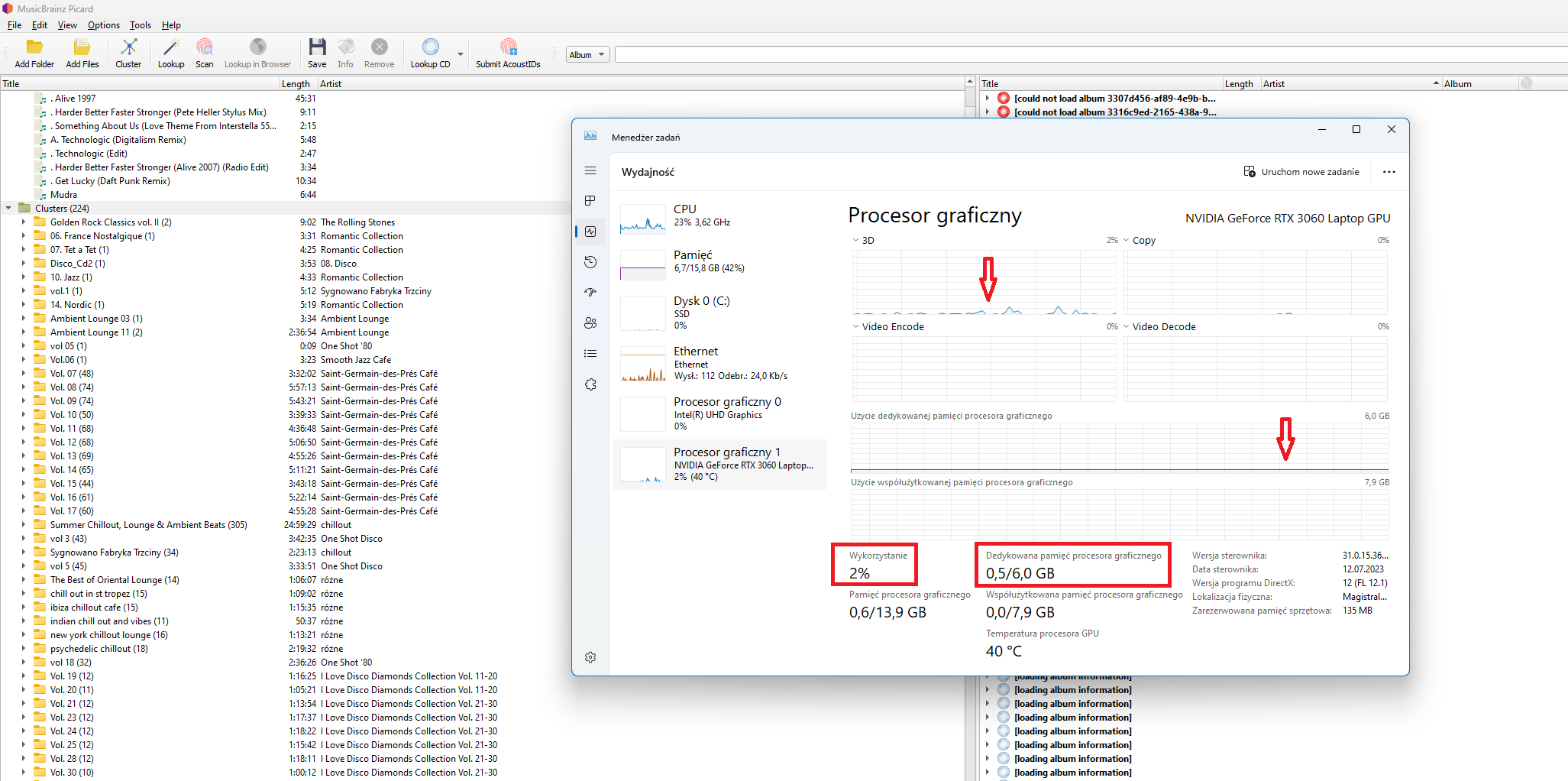
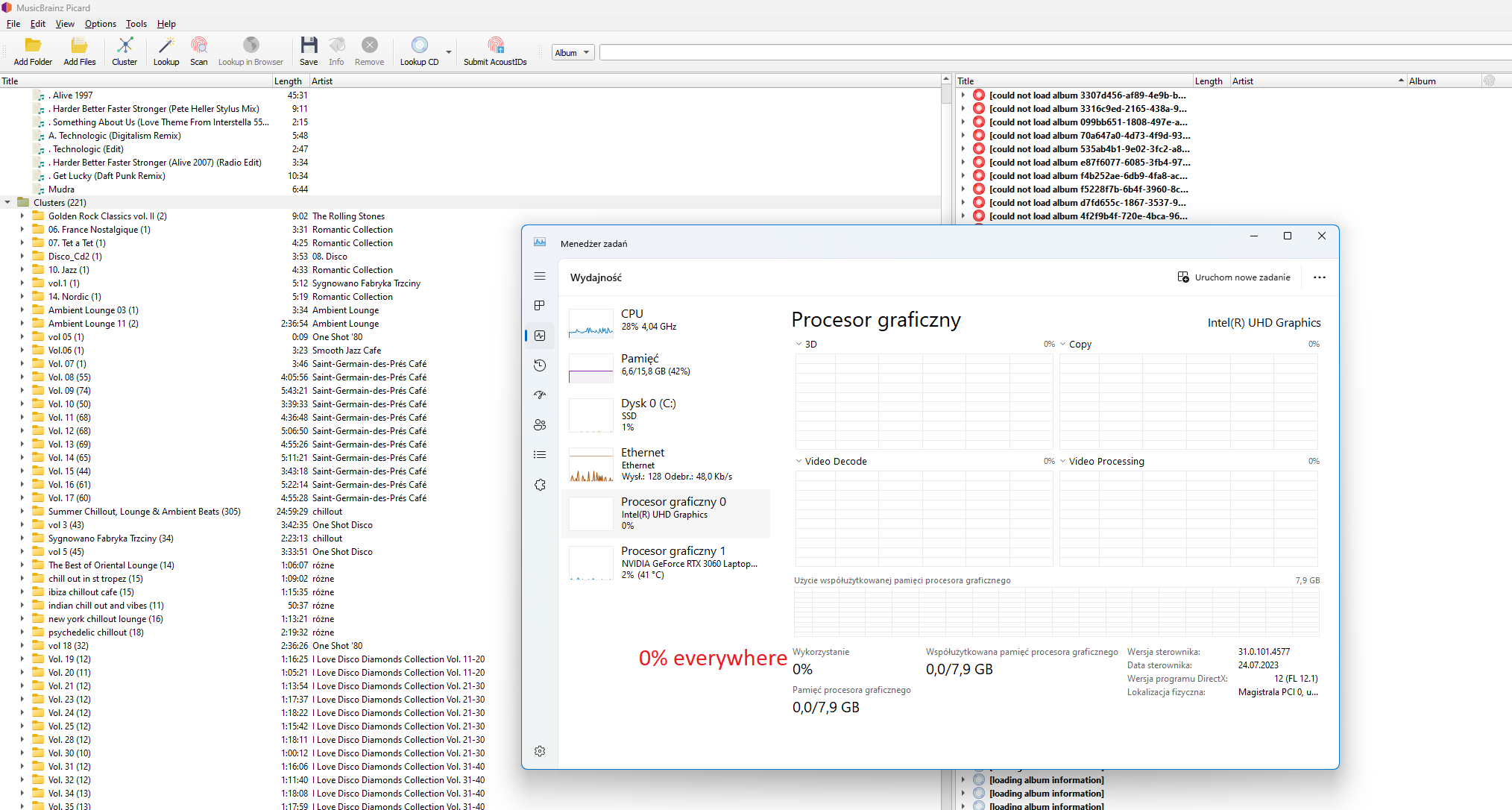
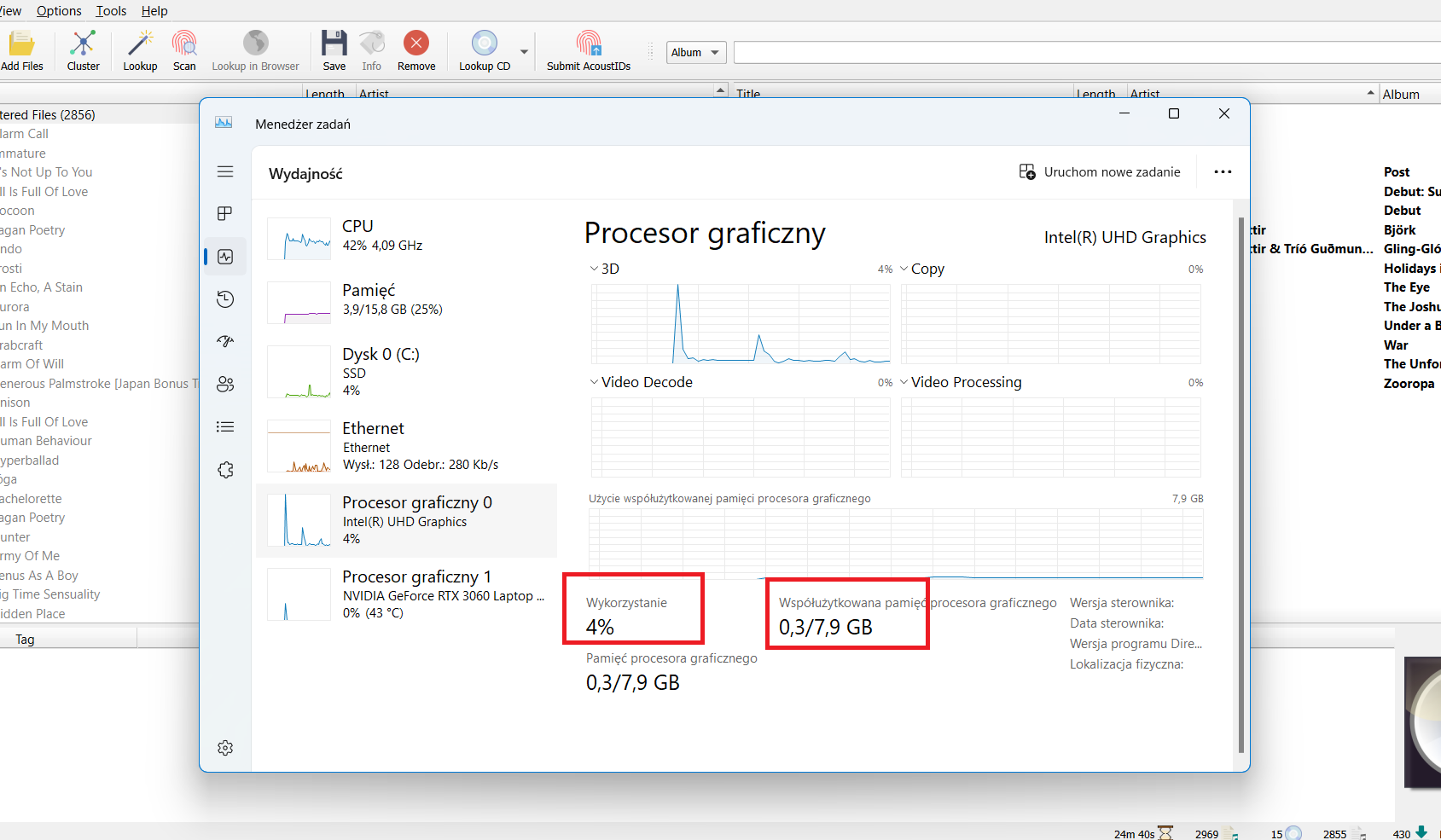
I use a laptop with a powerful RTX 3060 graphics card and an external monitor.
Recently, however, after the release of Picard 2.9, I was working without an external monitor. These 5 activities of mine took 3 times longer than usual.
I connected an external monitor and everything went fast again.
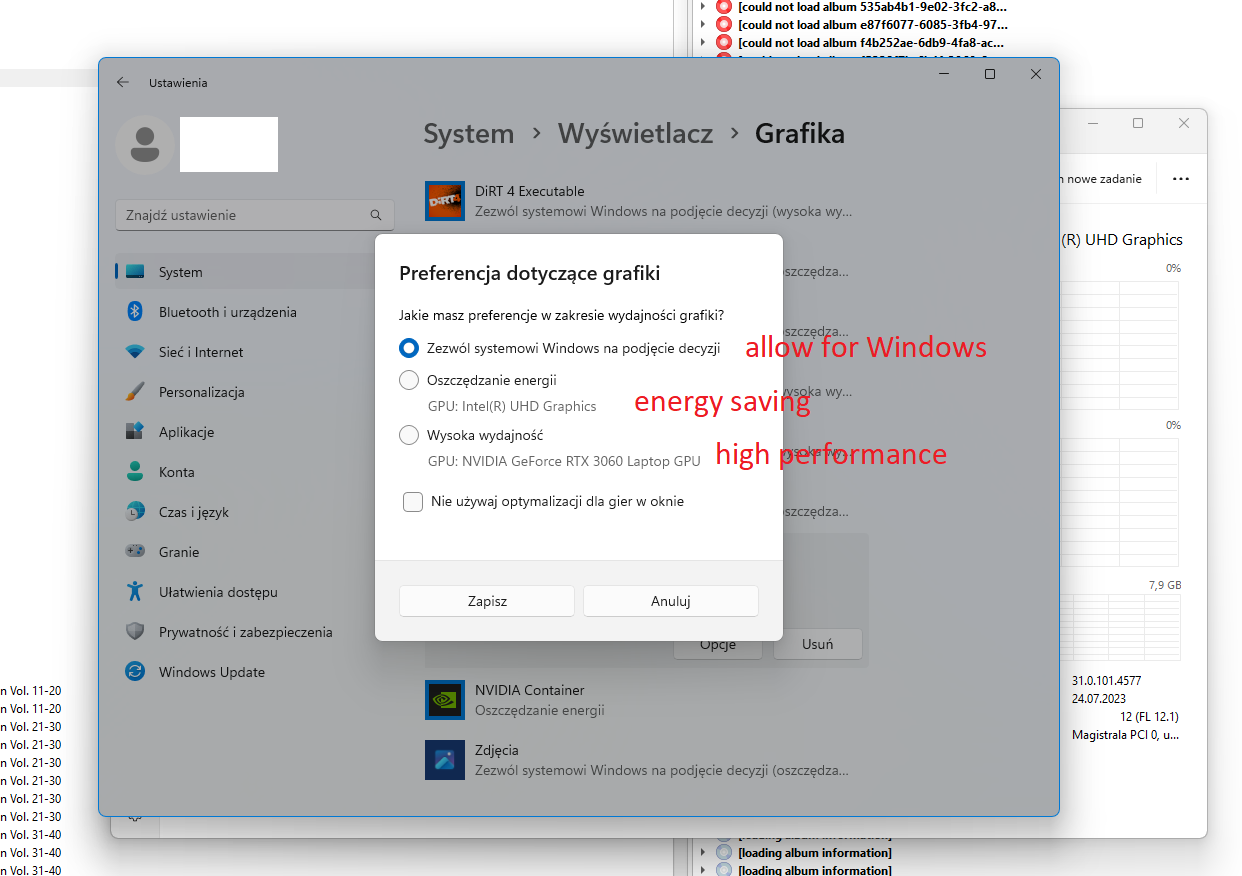
For clarification, I’ll add that when I’m working on the laptop alone, two graphics cards are active: the integrated Intel and the more powerful NVidia. When I work on an external monitor via HDMI the system only uses NVidia.
My question is this: is it possible that the speed of finding a tag depends on the working graphics card?
And why do you follow this approach? Have you read the documentation for recommended workflows?
Why not just load your files into Picard and click cluster and lookup? There is no need to scan files especially if they already have some information that Picard can use to start with like a directory structure / name and track number.
P.S. AFAIK the graphics card should not impact the speed - I don’t think that there is code in Picard to use the GPU for scanning - but though it shouldn’t happen, I suppose it is possible that without the graphics card the status updates queue up and slow things down.
I’m not aware of things being faster depending on graphic card. But the fpcalc tool, which calculates the AcoustID fingerprint, uses ffmpeg to decodee the audio.
If it is really the scan that is faster, maybe it is ffmpeg that can make use of the graphics card for faster decoding? Or maybe the Fast Fourier Transformations (FFT) library can use the graphics card. I really don’t now, but it might be possible.
Unless you want to test Picard for regressions there is no real need for that effort.
Only occasionally there is a change in Picard that will result in changed tags. We try to avoid changes that will affect existing tags. If something changes we usually add an option that must be enabled. New tags might be added sometimes, but that’s noted in the release notes then.
More often data changes in the database of course, so you might want to retag your files occasionally.
By removing all the previously correct tags you put Picard into the worst possible condition, where only scan can give results. Without any hints from existing tags Picard can only guess on which release to load if a recording is on multiple. I’m happy to hear that this process works very well for you with the settings you have chosen.
However, for updating your tags I actually would recommend to leave existing tagsspecially the MusicBrainz IDs. If those are present Picard will automatically load the proper release and assign the files to it. That makes it easy to retag the entire collection and you only need to match the files to the proper release once.
Picard does not really care about the GPU itself, but the integrated GPU takes up some system RAM as its video memory (how much depends on your specific model, but it can be quite a lot). When the iGPU is deactivated, that RAM is available to the system normally and Picard probably needs that when running on 15k files (with the iGPU active the excess memory required would end up in swap, i.e. temporarily put on your comparatively slow SSD).
This method is not going to do that… you are just going to get a fairly random match on AcoustID. Your “Preferences” bias should at least push it away from compilations. Not going to be certain of the oldest though.
By deleting the tags, the “lookup” stage of the scan is now going to attempt to match the \folder\filenames… Wiping tags is taking away the better quality data and making Picard do more educated guesses instead.
Picard works best on album folders which are then human checked. It can kinda do what you are attempting but that is not exactly its core design. And throwing 4000 files at it is always going to give you small percentage of chaos. A 1% fail to match is pretty good!
Picard works best when linked with MusicBrainz to match exact albums. You do point towards a fascinating project idea… one that will return “oldest named version of the track with a bias to naming the original single or album”. It is certainly something I see other users trying to do with Picard. An option that says “I don’t care which compilation my copy was found on, just tag this as if it was the original”
(Just please - I beg you - NEVER click “Submit AcoustIDs” as this would actually make everything so much worse not just for you but others that follow…)
Picard is way more clever than I expected. If it is getting the results you expect for 90% of your data they that sounds an excellent return to me. Much of that match is likely to come from the “Lookup” getting a match on the folder and file names. And Picard is good at that.
The problem is that badly explained button means you have now uploaded data to potentially the wrong recordings. Meaning next time you run a scan it will just repeat the same errors as last time as you have taught the database that your unchecked data is correct.
I don’t work here, just a user like you. Apart from the difference is I have wasted way too many hours repairing incorrect AcoustID data. I would SO love to hide that button behinds an “advanced mode” option where it is only used when someone really understands its use.
And I ain’t blaming you for hitting the button. It looks so tempting. It looks like it is going to help. Instead what it does it upload data to potentially the wrongly matched releases making your next passes worse and worse as those few errors you had on the first pass are now being set in stone as “correct”…
When you hit that you are saying to Picard “I have checked all 4700 of these files and they are perfect matches, so please upload my perfect checked and confirmed data to the AcoustID database”.
“This method is not going to do that… you are just going to get a fairly random match on AcoustID.”
Why random?
I thought Picard was fingerprinting the file on my drive, checking it against its database, fetching the tag and assigning it to my file in Picard’s right pane.
EDIT:
I thought Picard was reading the fingerprint of the file on my drive,
Yes it will match the fingerprint correctly. But choosing which album or single to return to you is unlikely to always return that original or oldest recording. You have your “preferences” set to prefer the Singles\Albums\EP. So that is a good start. But will it return to you the original album or a reissue? Some recordings may be attached to dozens or even hundreds of releases
Singles on 7" often don’t have an AcoustID. Mainly due to data working best around CDs and Digital audio. It could be the first time the single is released on a CD is when it appears on a greatest hits compilation.
It is also pretty common that the version of the track that appears on the box set or compilation is slightly different to the original album. If it generates a different acoustID then it is not going to link you back to the original album, you’ll just get one of the compilations it appeared on.
There is also bad data in the AcoustIDs. When someone mistakenly presses Submit AcoustIDs when their data is not checked this adds noise and errors to the database that is fed to the next person sa correct matches.
You say yourself that most of the time you are getting good matches. So don’t be surprised if there is the need of some manual tweaks and cleanup. If you are getting 80% good data I would call that a good return. This lets you focus on manually sifting the messier results.
(This is not supposed to sound like me bashing Picard or MusicBrainz - cos Picard and MusicBrainz are a powerful combo. Just it can’t be 100% bulletproof. A human is needed to give a check and tweak of results)
This did surprise me too. That is pretty stunning. And only 50 track barely takes an hour to manually fix.
It shows you are working with a lot of popular music. There is the data of so many people that you are fishing through. And the more common and popular your taste in music, the more fingerprints will cleanly match.