GSoC 2025 application: Importing listening history files
Proposed Mentor: Lucifer/Mayhem
About me
Name: Mohammad Shahnawaz
Nickname: veldora (IRC, Discord)
Github : Mshahnawaz1,
Email: shahnawaz919956@gmail.com
Time zone: UTC+5:30
My PRs : Check out
Project Proposal
Problem Statement:
ListenBrainz has a feature to import listening history from platforms like last.fm and Spotify, but it doesn’t allow users to import listening history from sets of files like JSON (Spotify), CSV (Apple Music, Last.fm, Spintron), JSONL (LB), and ZIP, which is inconvenient for many users.
Solution Overview
I will develop an API endpoint, which will validate the files and process the data from the files and import the lists of listens to the ListenBrainz account. The processing of data will be done in the background, so users don’t have to keep their browser open for the duration of the import.
Implementation
The basic working of API is as follows:
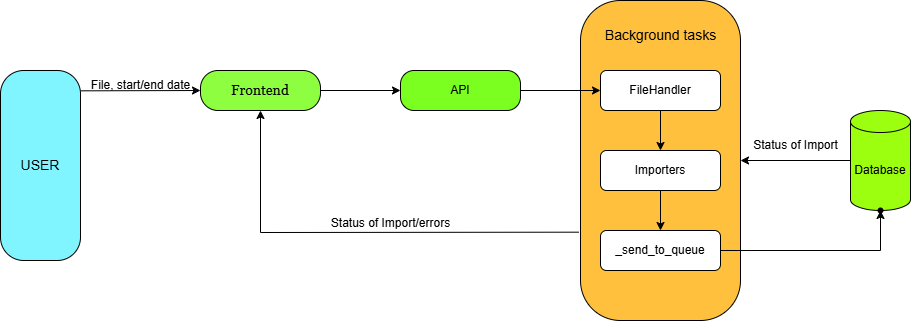
Overview of workflow
I will create an API endpoint to get input from the user.
After that, I will create a new background task for imports, which will process these files in the background.
After that, I will implement the functions to process data from formats like JSON, CSV, JSONL, and ZIP into LB format.
Then I will add these lists to the queue to store in the database.
In the end, to integrate this with the user, we will create a UI to get user inputs.
Part 1: Create an API Endpoint
In this part, we will create an API endpoint at setting/import-listens-files
#path: listenbrainz/webserver/views/settings.py
@settings_bp.post("/import-listens-files/")
@api_login_required
def import_listens_file():
if 'file' not in request.files:
return jsonify({"error": "invalid file"}), 400
file = request.files['file']
start_date = request.form.get("start_date")
end_date = request.form.get("end_date")
validate(file) # add validation for the size and format of file
temp_file = save_file_temp(file) #save file temporarily
result = create_import_task() # create a background task and add data into user_data_import
return result
-
The validate function will validate for file size (<100MB) and file formats (JSONL, JSON, CSV, ZIP).
-
The save_file_temp function will save the file temporarily.
filename = secure_filename(file.filename)
temp_path = os.path.join(TEMP_DIR, f"upload_{uuid.uuid4().hex}.tmp")
file.save(temp_path)
- Then I create_import_task will be defined to manage the process of importing data. This function will retrieve the saved temporary file, validate the contents, and initiate the import process while ensuring that any errors encountered are logged for later review. on similar to create_export_task.
-
In this, we will insert data into user_import_data the table.
-
The schema for it user_import_data will be
CREATE TABLE user_data_import (
id
user_id
service
status
progress
filename
created_at
)
-
The create_import_task function will also insert importing status into.background_task
- Her task will be “import_listens_data_files”.
- And metadata will have import_id.
INSERT INTO background_tasks (user_id, task, metadata)
VALUES (:user_id, :task, :metadata)
ON CONFLICT DO NOTHING
RETURNING id
Phase 3: Processing the data files in the background.
In this, we will implement file validations and conversions that will run in the background, similar to export_data.
After the lists are converted to LB schema and augmented. It will be sent to the queue to the RabbitMQ connection.
-
Implement a function to check the file type and schema in the file to select which importer we will use.
-
This function will also check for ZIP files and extract the files containing the lists. These files will then be processed by their importers.
Importers ---- [spofifyImporter, appleMusicImporter, lastFmImporter, LBImporter].
-
These importers will validate the file schema and convert it into the ListenBrainz schema.
-
The converted listens will then be added to the queue in batches of 1000 listens to import into the database using the _send_listens_to_queue function.
-
Then we will update the progress status in our tableuser_data_imports.
Part 4: Implement the importers to convert listens to LB schema.
In this part, we will make importers for each music service file.
class ListenImporter():
def init(self, filename):
self.filename = filename
self.listens = []
@abstractmethod
def validate(self, filename) -> list(dict):
"""validate the file and schema and output listens"""
pass
@abstractmethod
def tranform(self, listens) -> list(dict):
"""transform the listens"""
pass
def filter_date(self, start_data, end_date) -> list(dict):
#Implement filters for start and end date of imports
pass
class Spotify_history_importer(ListenImporter):
def validate(self, filename):
pass
def transform(self, listens):
pass
- Create a function for LB exports to be converted into a suitable format for imports.
In this function, we will read the JSONL file, extract the lists, and then clean the lists by removing the inserted_at.
# Sample cleaned listen to import. (LB import format)
{'listened_at': 1741758725,
'track_metadata': {'track_name': 'Pehli Nazar Mein',
'artist_name': 'Atif Aslam',
'mbid_mapping': {'caa_id': 14432024376,
'artists': [{'artist_mbid': '2c26fddb-3926-4004-ae27-22a3896a4f26',
'join_phrase': '',
'artist_credit_name': 'Atif Aslam'}],
'artist_mbids': ['2c26fddb-3926-4004-ae27-22a3896a4f26'],
'release_mbid': '00942d0e-73ec-48a3-8389-0139feb502e8',
'recording_mbid': '44b4ed20-a0e6-464e-96de-c95b134c0c60',
'recording_name': 'Pehli Nazar Mein',
'caa_release_mbid': '00942d0e-73ec-48a3-8389-0139feb502e8'},
'release_name': 'Race',
'recording_msid': '12105304-a169-4538-9200-5a459be823fa',
'additional_info': {'origin_url': 'https://www.youtube.com/watch?v=fs7-8M1VbZU',
'duration_ms': 216021,
'media_player': 'BrainzPlayer',
'music_service': 'youtube.com',
'submission_client': 'BrainzPlayer',
'music_service_name': 'youtube'},
'brainzplayer_metadata': {'track_name': 'Arijit Singh: Agar Tum Sath Ho | Alka Yagnik, A.R. Rehman, Irshad Kamil'}}}
- Create a SpotifyImporter class with functions to validate and transform Spotify listens into LB format.
I will create a validation for valid Spotify listens; these will include listens that are listened to for half of the track or 4 minutes.
Then I will create a function to transform these lists into LB format.
{'ts': '2020-12-23T14:51:53Z',
'platform': 'Android OS 7.1.1 API 25 (samsung, SM-G550FY)',
'ms_played': 163171,
'conn_country': 'IN',
'ip_addr': IP_address,
'master_metadata_track_name': 'Demons',
'master_metadata_album_artist_name': 'Alec Benjamin',
'master_metadata_album_album_name': 'These Two Windows',
'spotify_track_uri': 'spotify:track:57zRWXTQCFRV3zwg0NR8Ck',
'episode_name': None,
'episode_show_name': None,
'spotify_episode_uri': None,
'audiobook_title': None,
'audiobook_uri': None,
'audiobook_chapter_uri': None,
'audiobook_chapter_title': None,
'reason_start': 'trackdone',
'reason_end': 'trackdone',
'shuffle': False,
'skipped': False,
'offline': False,
'offline_timestamp': None,
'incognito_mode': False}
Conversion will be as follows:
ts → listened_at (UNIX)
master_metadata_track_name → track_metadata.track_name
master_metadata_album_artist_name → track_metadata.artist_name
master_metadata_album_album_name → track_metadata.release_name
spotify_track_uri → track_metadata.mbid_mapping.recording_mbid (if available)
track_metadata.additional_info.media_player = 'Spotify'
track_metadata.additional_info.music_service = 'spotify.com'
I have taken reference from kellnerd/elbisaur.
- Create an importer for the last.fm export file.
The last.fm exports taken from benjaminbenben have listen data in order.
[artist, album, title , datetime]. in CSV format.
So it can be directly mapped to LB listens.
- Apple Music Importer
Title, Artist, Album, Duration (ms), Play Date, Play Count, Is Complete, Source, Device, Genre, Explicit, Track ID, Album ID, Artist ID
"Shape of You","Ed Sheeran","÷ (Divide)",233713,"2024-03-19T10:15:45Z",3,TRUE,"Apple Music Streaming","iPhone 13","Pop",FALSE,"1234567890","1234567800","111222333"
"Uptown Funk","Mark Ronson","Uptown Special",269000,"2024-03-19T11:45:30Z",1,TRUE,"Apple Music Streaming","iPad Air","Funk",FALSE,"0987654321","0987654300","444555666"
In this importer, I will directly map the following into LB format.
Title, Artists, Album, Duration(ms), Playdate(UNIX format)
Then add the additional information of listens.
track_metadata.additional_info.music_service = 'Apple Music Player'
track_metadata.additional_info.device = Device
Part 5: Add frontend component to allow user to submit listens file and start/end date.
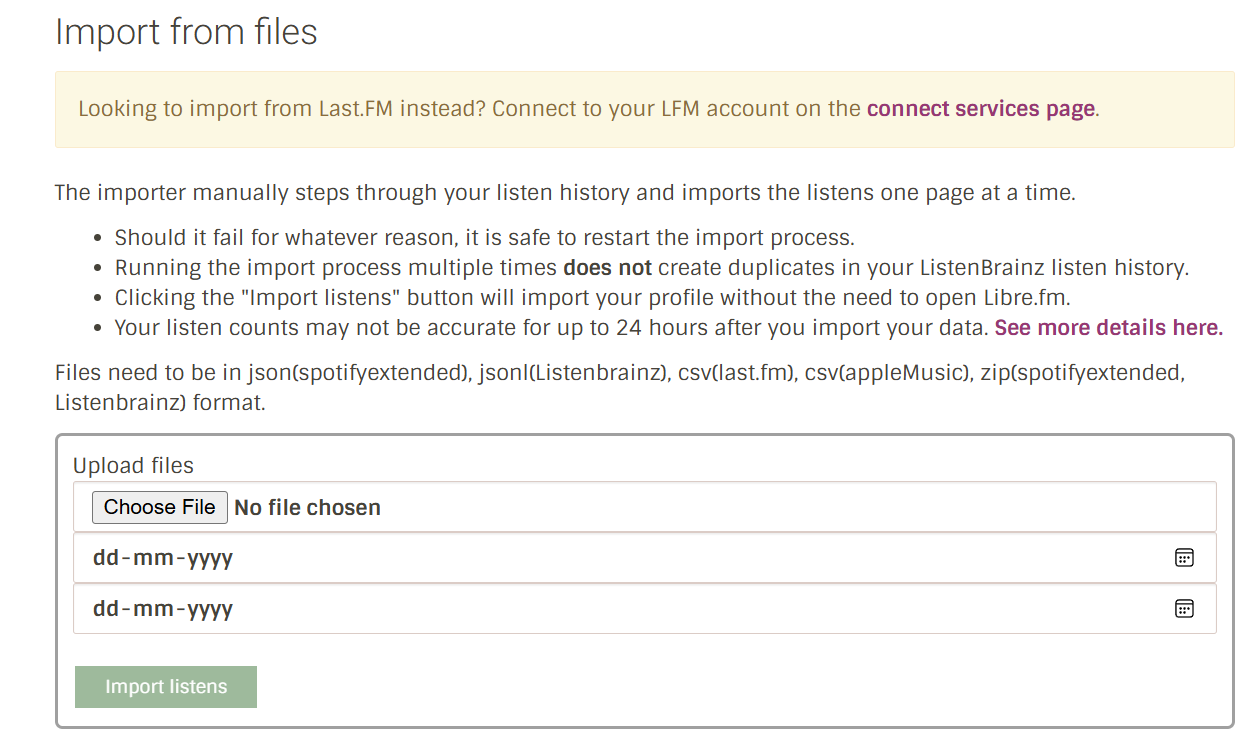
Part 6: Handle errors, code cleanup, and add documentation.
In this part, I will test the API for any errors and then clean up the codes. Furthermore, I will add the documentation for the feature added.
Timeline
This is the detailed week-by-week timeline for the 350 hours of the GSoc coding period that I intend to follow.
Pre-community Bonding Period (April-May):
During this time I will be working on a deeper understanding of the codebase and workflow and related technical skills.
Community Bonding Period (May 8 - June 1):
In this period I will discuss the project with mentors and plan the roadmap of the project and get a clear sight on the plan of action for the project.
Week 1:
First I will create a file handler for LB exports. This will be used for testing of the API.
Week 2-3:
Then I will create the API endpoint and add simple file validations. And error handling
Week 4-5:
Create a task for the background processing of import data.
Week 6:
Create the tables to store the import progress.
Week 7:
Add functions to process the files in the background.
Week 8:
Create a Spotify importer to convert the export file from Spotify into LB. Listen.
Week 9:
Create a function to convert Apple Music listens to LB listen format.
Create a function to convert last.fm exports to LB listen format.
Week 10:
Make a frontend section to get file input from the user.
Week 11:
Check for any errors and troubleshoot for invalid behaviors.
Week 12:
I will clean up my code and add documentation. Discuss any changes with your mentor before final submission.
Stretch Goals:
-
Add the functionality to import data from YouTube Music.
-
Add functionality to import data from Spinitron exports.
Detailed Information about Myself
I am a 3rd-year college student trying to improve my skills and gain experience from working on projects used by many people. This opportunity will help me in gaining valuable experience in the open-source world. I am really fascinated by the idea of open-source projects, which provide access to good, if not the best, quality software at no cost.
When I am not working, I love watching anime and reading novels.
Tell us about the computer(s) you have available for working on your SoC project!
I will be using my HP 14s (8GB RAM with 512GB SSD) with Windows 11 for this summer.
When did you first start programming?
I have started programming since my high school, but seriously started coding
first year of my college.
What type of music do you listen to?
I am mostly listening to contemporary/pop like these. Let Me Down Slowly, Agar Tum Saath Ho , Aasan Nahin Yahan (Recording “Aasan Nahin Yahan” by Arijit Singh - MusicBrainz)
What aspects of the project you’re applying for (e.g., MusicBrainz, AcousticBrainz, etc.) interest you the most?
ListenBrainz provides a way to store listening history from multiple platforms and show stats and recommendations. It helps me in better understanding my listening habits.
Have you ever used MusicBrainz to tag your files?
Yes, I have.
Have you contributed to other open-source projects?
ListenBrainz is the first open-source project I am contributing to.
If you have not contributed to open source projects, do you have other code we can look at?
I have worked on irrigation systems, that uses machine learning and a Flask-based API to decide if irrgation is required or not.
What sorts of programming projects have you done on your own time?
In my free time I have been working on Python and JavaScript projects like a content-based movie recommendation system and an automated irrigation system for a hackathon. Also I have worked on grocery, to manage user inventory.
How much time do you have available, and how would you plan to use it?
I will be available full-time for the duration of Summer of Code, which will be about 30-40 hours weekly. I will also be able to add more hours if required.