I import 7k mp3’s from pre 2010 and it will randomly crash after a while during initial lookup scan. Then, I try to run it on different machines, where it still crashes. Running it in debug mode doesn’t leave any traces.
Also, the acousticID database is after all these years, still too small to correctly identify my collection ( 5-10% ? )
And if this software doesn’t crash, the lookup process simply misnames many tracks.
I show you an example on why you can’t trust lookup:
(pardon there is a lot of trash music in this very old colllection, but lets take some good artist)
µ-Ziq
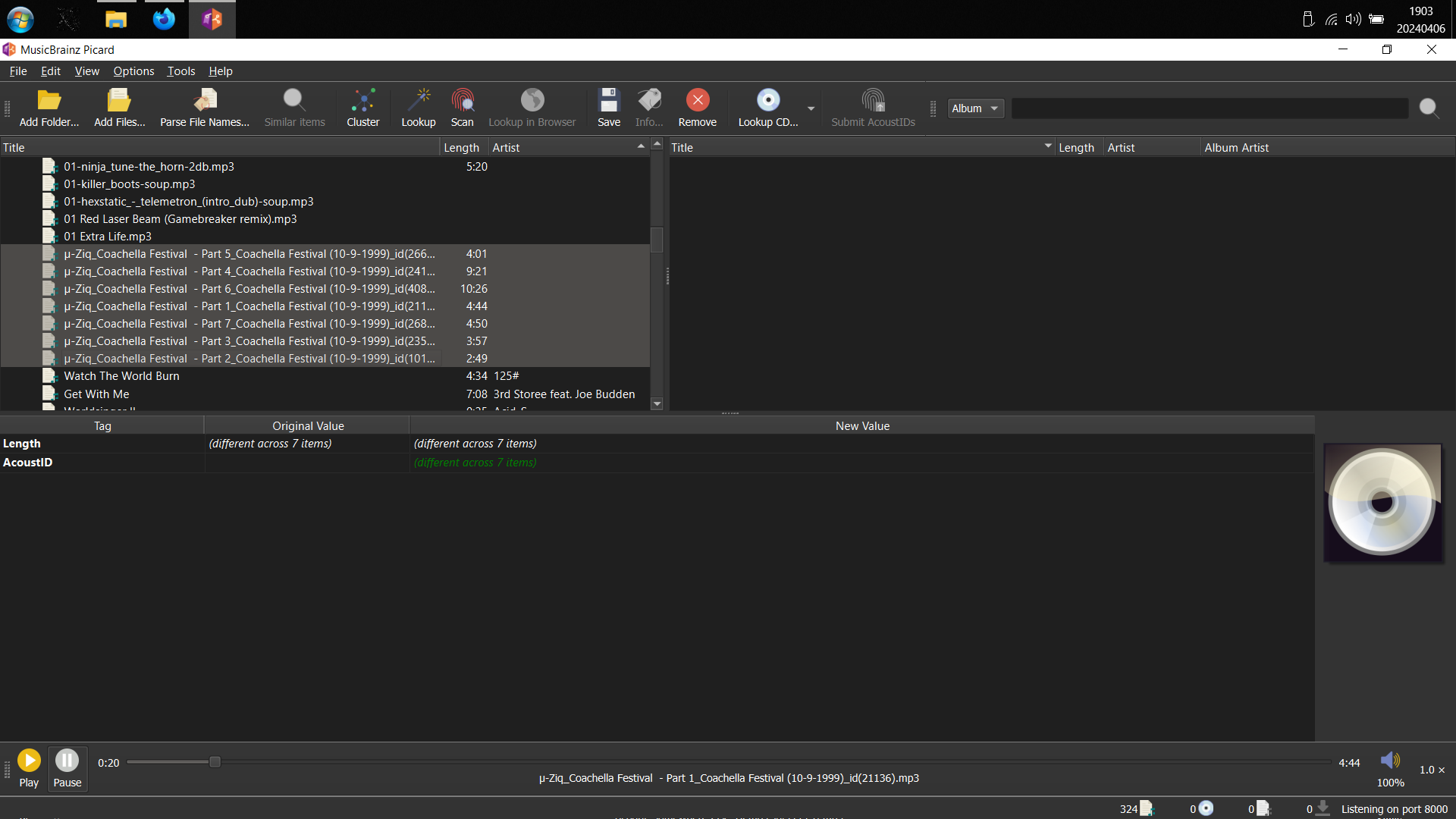
Now, scanning it does not identify those tracks, but I try to use the lookup tool, what do we get?
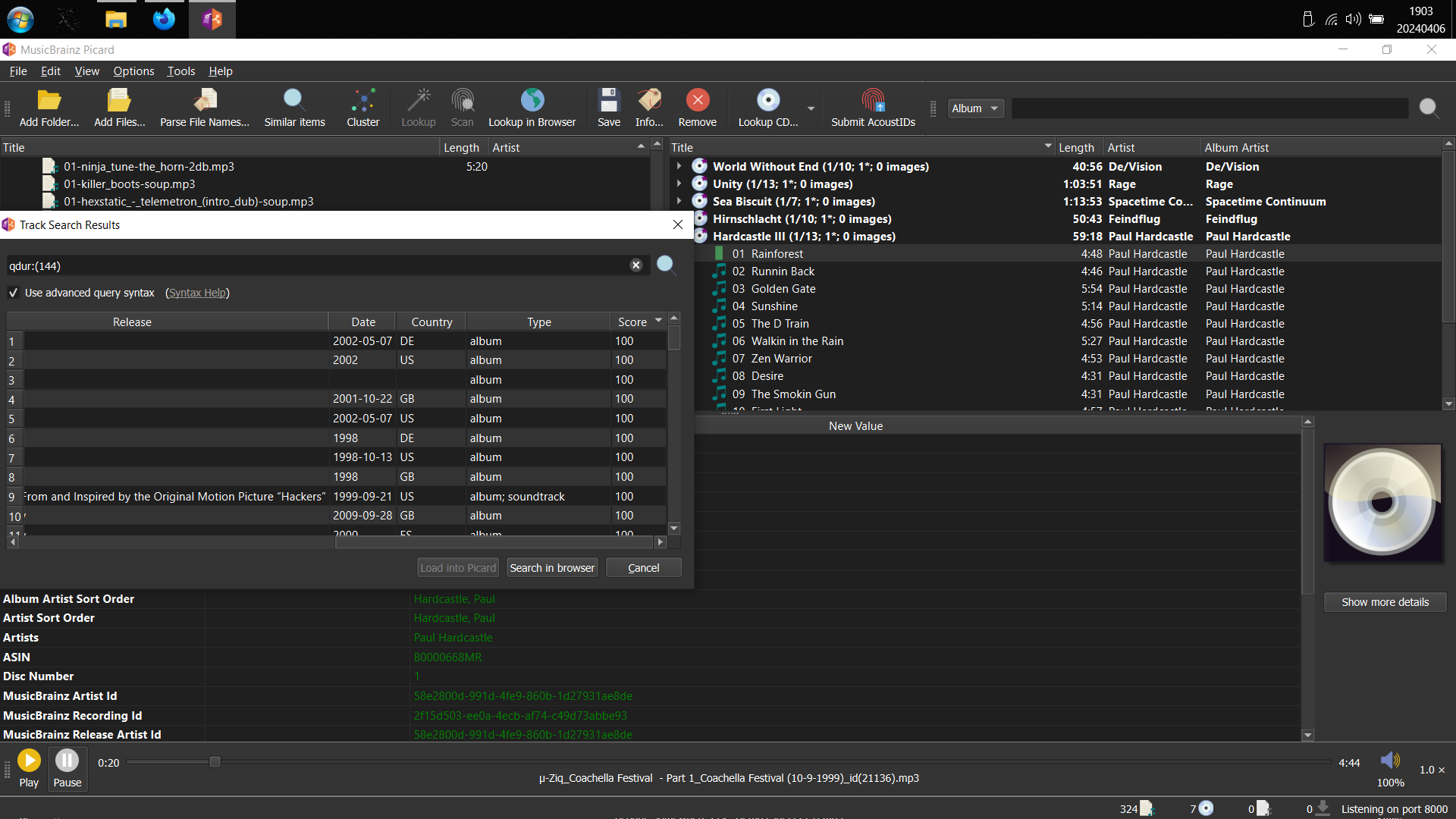
we end up with these weird Albums no one asked for. And even worse, looking it up in search gives us a score of 100%. How is that possible?
The worst part of this is that renaming the files, would completely destroy the collection. I believe a software like this should mainly rely on fingerprinting and use some more advanced statistical measures to pick the correct name.
Am I using this tool in a wrong way? Am I supposed to import tracks one by one so it won’t crash?
For most of these tracks in this old collection, I can assure you that its mostly mainstream tracks and no obscure genres. I simply can’t trust the automatic process here.
You have a specific situation, and I can’t help you with the details. However, I can give you two general pieces of advice:
7000 music files is a lot. Try starting with 1. Then 5. Then 20. Work out your process with smaller quantities first. Then increase the quantities as you see what the tools can handle.
Could you please articulate your desires for Picard? What do you have? What do you want to end up with? What do you hope for Picard to do for you?
If we know more about what you want, then perhaps we can help you figure out how to achieve it.
In short yes. Picard needs a bit of fiddling in the settings.
The first thing you need to do is cluster things, otherwise the lookup system’s just going to be trying to match files to recordings - resulting in what youv’e got here. Clustering should force collections (albums, compilations, EP’s) to be prioritised.
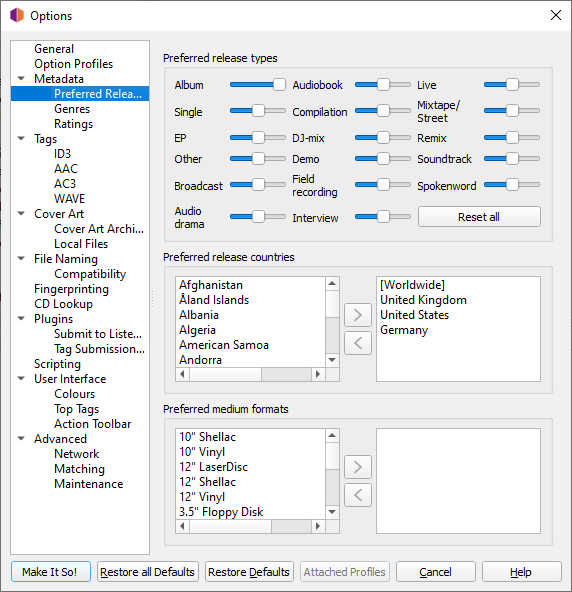
Have a look at this window in your Picard settings:
You’re gonna want to specify what you want it to priotise more than others (move sliders to the right).
Another point, don’t dump 7K of items into it. Don’t even try 1K, as you’re gonna have a baaad time. Try in smaller batches first.
As for AcoustID’s it’s hit and miss. Everyones aware of how useful and unuseful it can be at any point… there’s a lot of bad relationships built (which takes ages to unravel and IMO only those who know what they’re doing should ever submit a fingerprint). Along with that, if your collection is primarily EDM stuff then there’s a lack of fingerprints for that kind of stuff.
Also keep in mind on the source of your original files, you say pre-2010 and the files look muddled with metadata (which is fine). If they’re dodgy rips from internet radio, weird rips from YouTube/SoundCloud etc. then it’ll usually fail to fingerprint by the simple nature of how it works (Chromaprint doesn’t work like Shazam for example).
There is a truly excellent documentation site which is impressively comprehensive and which can help you get started (thanks in a large part to Bob Swift @rdswift - who IMO has done such great work he needs to be mentioned as often as possible).
In a word, no. You definitely don’t want to import them one by one because you really need to cluster groups of related files. But perhaps it would help Picard not to load 7,000 tracks at once and to do them in chunks. (Again, read the documentation.)
P.S. Some users do find that the Help menu in Picard can actually be helpful, and in particular it will take you to the documentation site.
The example you gave looks like it includes recordings from μ‐Ziq’s 1999 Coachella performance. I don’t see any releases corresponding to this at μ‐Ziq - MusicBrainz (nor do I see standalone recordings), so it’s impossible for Picard to find a match for it. (I’d add it myself, but I couldn’t find anything online corresponding to the performance besides some random YouTube videos.)
thats clear, but why does Picard still assume it’s part of some album or other release? it doesn’t make any sense. I’ve had other false identification on actual real releases too. this is a clear issue. it should simply skip those files or name them as unknown.
Your screenshots show that your files have no tags at all. No title, no artist, no album, nothing. So the only information that can be used is the length.
This leads to the strange situation that lookup will try to find matching tracks by length, and since it has no other reference point it considers every found track with a matching length a very good match.
Usually Picard will try to guess at least title and artist from the filename, but this seems to either fail in your case as well or it’s disabled in options.
Without album and artist tag also the clustering fails, so the first cluster then lookup approach is also not possible.
If all your files are like this maybe you can get some results with the Tags from filename function to fill in at least artist, track title and if possible album title. Then lookup might be able to get some results (given the releases are in MB).
I tried many things and my conclusion is that the musicbrainz db is utterly inconsitent and broken. We need to start over guys. Maybe work with the music industry or labels. We can’t rely on user submissions for AcousticID either.
respectfully, Picard is not a magic tool, & no tagger can be. it takes the information it has and does its best with it. if you went to a barber and sat in his chair without saying a word, you can’t be mad when he shaves your head.
MusicBrainz Database exists because music industry and labels actually failed at creating an open and consistent database.
It seems obvious MusicBrainz Database and Picard don’t fit your needs.
But please, once you found a database and a tagger matching your expectations, come back here to tell us about them, so we can analyze what and how they do better and try to improve our messy stuff.
Erase 20+ years of work of millions of contributors and just start over?
I like this plan…