Are there things that can be done with MusicBrainz entries to improve the chances of listens being matched? It could be just because I listen to it and my related users do as well(so I’m more likely to notice), but it seems to struggle most with mixed languages.
For example from a similar user of mine
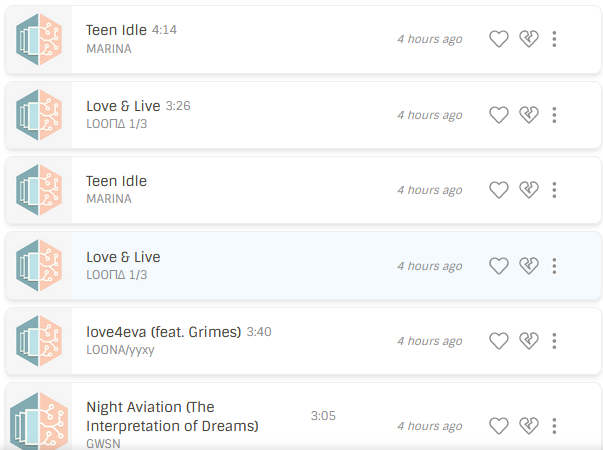
If you take Love & Live as an example here is the MB recording
You can see the title of the track, release, and artist are all written in multiple different ways. Some artists everything will be Hangul/Korean on Korean services and Latin/English on western ones, so they are all valid and could show up in listens in any of those formats. But most notable is the main entries are in Hangul where the listens aren’t.
I’m not sure what data is all used for matching so I’m not sure what I can do on the MusicBrainz side editing to improve the chances of automatic matches. I fix my own always, but if I can add or edit things for artists on MB that would help I would like to do that. Would linking recordings to Youtube Music Videos, Youtube Music, or spotify songs help? Should I add aliases to releases and recordings for other scripts?
And this is about entries that have existed on MB for a long time not missing ones to clarify further.
Also if there is any other data that ListenBrainz uses or might use in the future I would love to know so I can prioritize adding that as well ![]()