If I try it with this command: https://musicbrainz.org/ws/2/release/1d9867ad-721a-4abb-9a22-41e118531068?inc=recordings+recording-level-rels+area-rels+place-rels
I don’t get any information at all about place or area. It doesn’t seem to make any difference if I ask for JSON or XML format or limit it to any number.
The same command for a partially available release like the first 28 CDs from the same release: https://musicbrainz.org/release/5418ad56-bce0-4d69-abfa-7425d7e756cc
seems to work perfectly fine, returning the informations about place and area. https://musicbrainz.org/ws/2/release/5418ad56-bce0-4d69-abfa-7425d7e756cc?inc=recordings+recording-level-rels+area-rels+place-rels
Question:
If there is any limit to return such data, how could I get it in parts for huge releases?
That’s weird, because in my test environment (browser) I don’t get the same result, I don’t see any “recorded at” in the ouptut…
I used your curl command in my windows 10 command line window and get a 5’740 KB size test.xml file. But there is NO “recorded at” in this file… I opened it with Notepad++ and even WinMerge.
You will need to make two additional calls, one for /ws/2/area?release=1d9867ad-721a-4abb-9a22-41e118531068 and the second for /ws/2/place?release=1d9867ad-721a-4abb-9a22-41e118531068 with pagination offset.
Not sure about these examples, you should rather have a look at a real example.
But @nadl40 explained above, that his/her test.xml contains the “recorded at”.
Do you say, the /ws/2 from a browser call does not return the same as a curl command?
If yes, why does my curl command under windows does NOT get it?
As @jesus2099 said the web service omits recording relationships on releases exceeding a certain no. of recordings for performance reasons. Picard is plagued by the same issue.
One solution is to do a separate query for just the recordings in this case:
This will give you the missing relationships. But note that this request is paginated and returns a max. of 100 recordings per call. You need to perform additional queries with increaed offset parameter to get all recordings.
I just implemented exactly this for Picard a few days ago, where it detects if recording relationships are missing and if they do it performs separate queries.
No, you get the same result. The screenshot shown seems to be for a different release, at least I cannot see “St. Jude-on-the-hill” as a recording location for 1d9867ad-721a-4abb-9a22-41e118531068
Update after I read above post: Well, @outsidecontext’s Picard example is even better for you, as you want two entity types at once!
Oh @InvisibleMan78, in fact, when I wanted to get works from a 501+ track release, I made another request with recording batches (not the requests as I showed you in my earlier post, but maybe they work):
But I had to limit the amount of recordings to avoid pagination:
sorry for the mixed up, my curl command had an -O instead of -o and test.xml was from another release when the command was correct.
As per others, you need to paginate.
But I just realize it isn’t maybe that easy to see what it is doing without a deeper understanding of Picard’s internals, since the actual request URLs are not directly visible in the code changes, as this just uses all the existing query functionality already present in Picard.
To put it simply, when the first recording you browser has no .relations attribute, it means that you didn’t get any recording-level-rels for this release (today’s criteria being more than 500 tracks).
If .relations is an empty array [], you are not in this case. It’s just that recording has no relationships.
In Picard’s case we read the release, detect the missing recording relationships, then load all the recordings separately and inject just the relations key from that into the already loaded release data. That way the rest of the code of reading data from the release stays the same.
Writing this reminds me that I need to check whether plugins can access the loaded release relationships. Probably not, which means I need to refactor this again a bit
I don’t think this is a bug, it’s a feature to limit runaway API calls.
Doing separate calls is ok but I try to limit those because of the limits per second against the live server, slave servers do not have this limitation, that’s why I try to get as much data as possible in one API call. Need to adjust how to process paginated release.
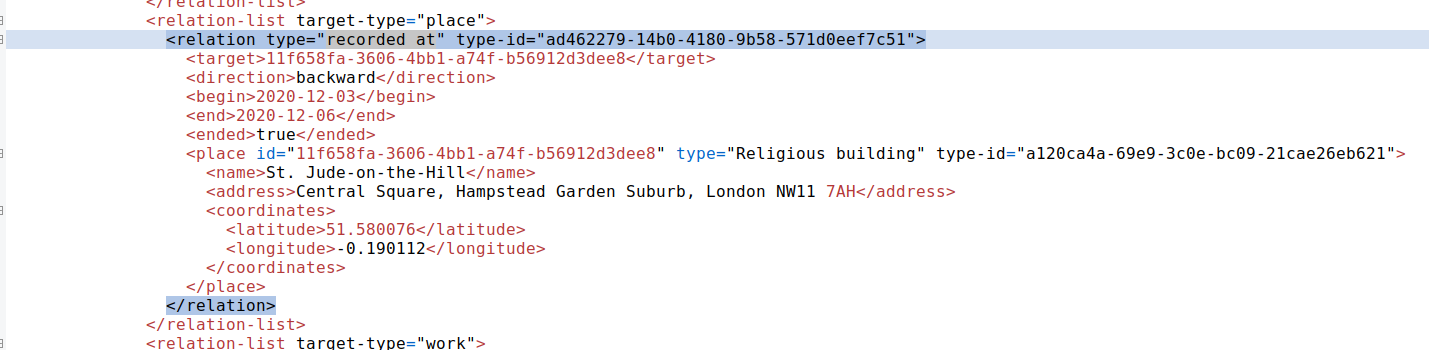

 I opened it with Notepad++ and even WinMerge.
I opened it with Notepad++ and even WinMerge.