Hey guys, I think I might be able to figure out how to get the data I need if I am able to connect to the database with PSequel. When trying to connect though, I get the following error: "FATAL: password authentication failed for user “musicbrainz”'. The strange thing is that when I log in on the VM itself (using the command psql -h 172.17.0.4), it works fine with the same user and password combination. Anyone have any idea what the problem might be and how I can solve this?
Here is the login info I’m using in PSequel:
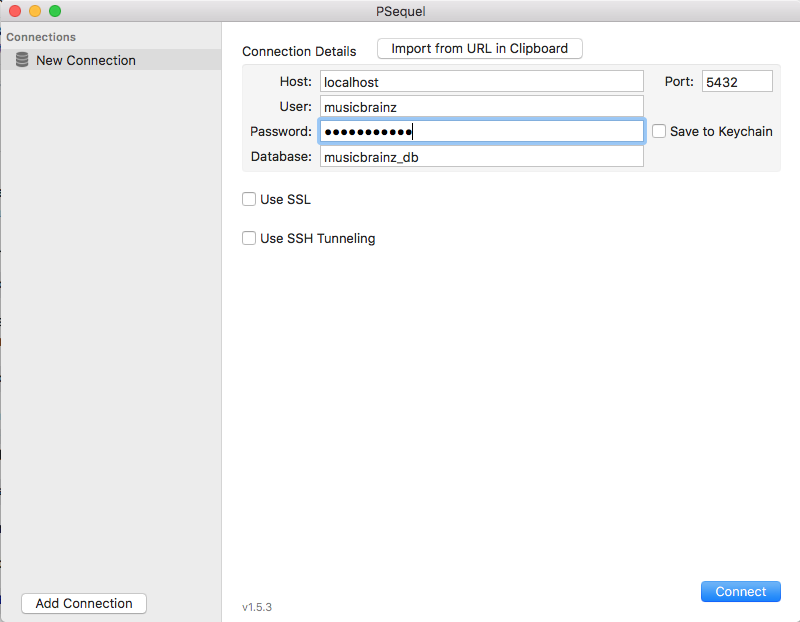
Any help or suggestions would be greatly appreciated!