Short version:
Due to my lacking programming or database management skills, I am running into problems extracting data from Musicbrainz for my academic research. Now I’m wondering if someone here could help me out by either extracting the data I need for my research or guiding me through the process (description of problem below).
Based on the database schema and the information on the main website, I think it would be easiest to extract three different sets that I can easily match myself, and combine with the data I already acquired from different sources. Ideally the sets would look something like this, but I can adapt and limit based on what is easy to extract: artist level data (id, name, type, gender, begin/end date(s), nationality/area), album level data (year, label, artist(id), rating), song level data (ISRC, year, label, artist(id), album/single/first release).
More explanation:
I am a PhD researcher at the economics department of KU Leuven university in Belgium. I’m conducting an econometric analysis of the impact of music piracy on music sales and live performances. I have collected datasets of digital song sales and concerts in European countries between 2008 and 2015. I am looking to complete these data with characteristics about the artists and their releases in order to help me determine to what extent illegal downloading affects different segments within the music industry, which will be the main contribution of my work.
While lots of trial and error resulted in finally being able to (seemingly) access the database through the pre-configured server with Virtualbox, I just don’t seem to be able to figure it out from there. Most forum posts and the Github entries about the database server go over my head in terms of prerequisite programming or database management knowledge. I got to the point where I am now thanks to this forum entry: Trying to access MB database through pgAdmin and VirtualBox. If someone could dumb it down for me how to go from there to accomplish my goals, that would be extremely helpful as well.
My research is purely academic and non-commercial. I aim to publish all my analyses. I would be immensely thankful if someone could help me out, as I’ve been struggling with this for a while already.
if you could form a query with a clear set of valid parameters from any of the valid resources, which you would like searched for, i could give you a url that would return the data that may be available in either xml or json format…
if you need to do much more than that, im afraid you might need a phd in comp sci as well… ive now mapped the entire db, but wiht the current documentation found it quite a challenge.
Thanks for your response, I’m not familiar with the mb api, but I’ll try to explain myself a little better. I think what I actually want to achieve should be relatively simple, but maybe that’s ignorance from my side.
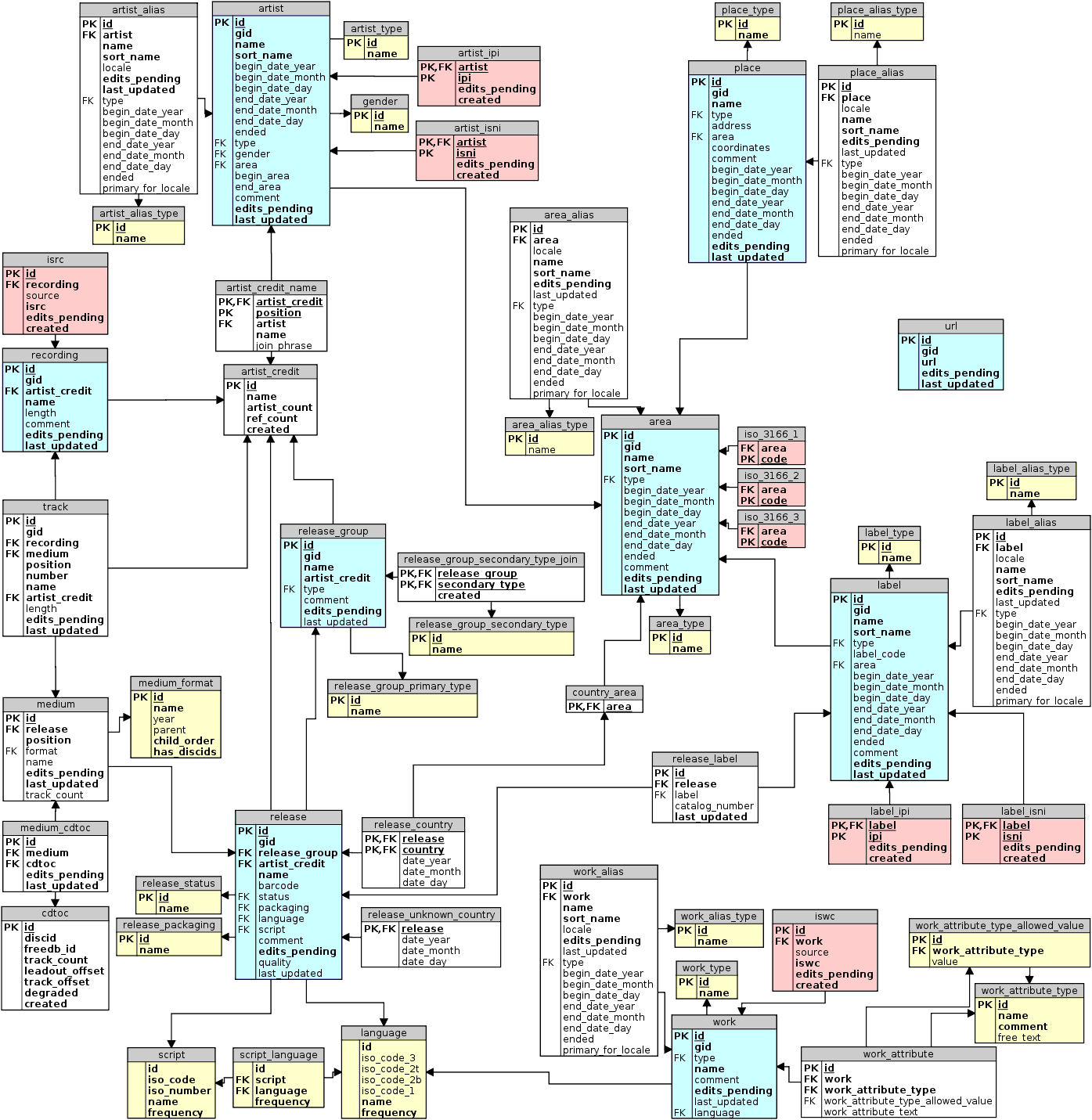
I think at least part of the data I need already exist as tables in the database. For instance the artist level data I am after, are just a couple of columns of the artist table described in the schema (https://wiki.musicbrainz.org/-/images/5/52/ngs.png). I actually need all rows (so all artists in the database) to be able to match it with other datasets I already acquired, so I don’t think I have to query it but just have to find a way to extract the correct data, preferably in some format that I can easily import in software programs for statistical analysis (csv would be ideal, but I think xml or json should work in principle). If all else fails, even just having these artist level data would be better than nothing for my research.
Ideally though, some information on album and song level would be needed in a way that I can easily link it back with the artist information. Again, I’d like datasets of all albums and all songs if possible to be able to match with existing data. When looking at the schema, there don’t seem to be any pre-existing tables like with the artists so there’d have to be a way to piece the variables I’m after together in tables to accomplish this.
The reason I don’t really want or need to query a set of artists/releases/songs: I will have to match these data with other datasets based on artist/song name. Since this will very often not match exactly, I’d rather get the complete dataset such that I can figure out some string based matching algorithm in the statistical software I’m using. I do have ISRC codes for individual songs, so if I could match songs that way, that would be great.
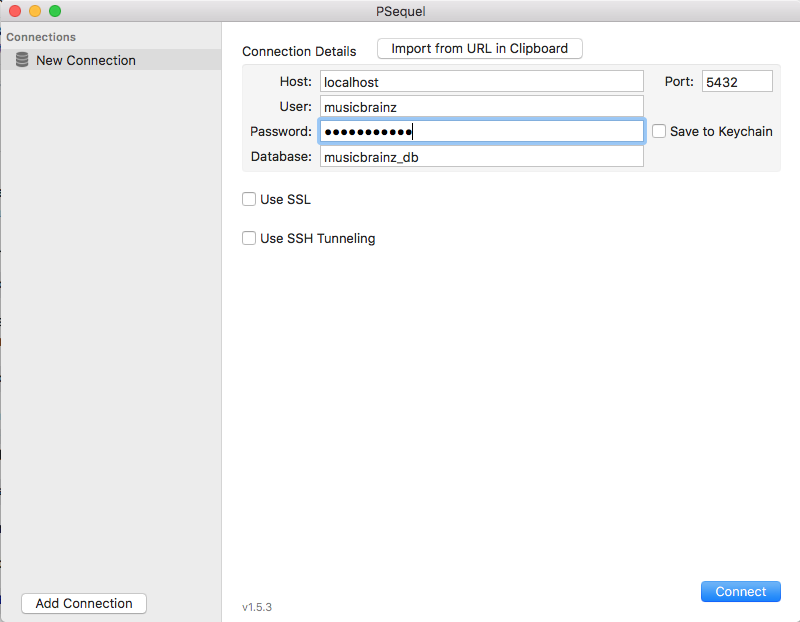
Hey guys, I think I might be able to figure out how to get the data I need if I am able to connect to the database with PSequel. When trying to connect though, I get the following error: "FATAL: password authentication failed for user “musicbrainz”'. The strange thing is that when I log in on the VM itself (using the command psql -h 172.17.0.4), it works fine with the same user and password combination. Anyone have any idea what the problem might be and how I can solve this?
I don’t know about the VM setup, but one thing that surprises me in your screenshot is the host value. Shouldn’t you use “172.17.0.4” instead of “localhost”?
Since you seem to be able to launch psql commands, the following should work: psql -h 172.17.0.4 -p 5432 -U musicbrainz -d musicbrainz -c "Copy \ ( SELECT 'http://musicbrainz.org/artist/' || a.gid AS url, a.name, a.sort_name, g.name, r.name, to_date(to_char(a.begin_date_year, '9999') || to_char(a.begin_date_month, '99') || to_char(a.begin_date_day, '99'), 'YYYY MM DD') AS date_of_birth, to_date(to_char(a.end_date_year, '9999') || to_char(a.end_date_month, '99') || to_char(a.end_date_day, '99'), 'YYYY MM DD') AS date_of_death FROM artist AS a JOIN gender AS g ON g.id = a.gender JOIN area AS r ON r.id = a.area LIMIT 10 ) To stdout With CSV;" -o output.csv
If this works, remove the LIMIT 10 to fetch data for all artists.
Just a pointer for the next ones:
The relevant table in musicbrainz is “release” (for year and artist at least, you will need to join it with the label table for the label)
In musicbrainz lingo a song is a Work (recorded on Recordings included in Mediums that belong to Releases); so ISRC, composer and composition year are easy to find, album/single/first release are trickier.
I did try this as well, but then I get the error “PostgreSQL Error - timeout expired”.
Thanks for this command and the pointers for my other requests! I still get an error for this as well though: “ERROR: relation “artist” does not exist.” Is there anything I need to do before this? I did everything on the server setup page except for the replication stuff since I don’t need that.
I will for sure post when I get anything published for which I use Musicbrainz!
That means the table “artist” is not existing. I suspect your database is empty (or at least not filled completely)
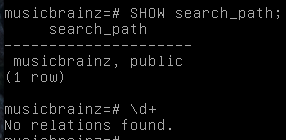
What did you test after connecting? You should probably look at some basic postgresql tutorial to check the database state. For example the command \d+ inside psql should give you the name of tables defined in your database and SELECT COUNT(*) FROM XXX; where XXX is a table name should tell if you really have data inside.
I don’t know if the replication step is required to have data in your database or just for synchronisation, you’ll have to find someone who knows the VM setup
For stuff like that you can also ask the MetaBrainz channel on IRC where musicbrainz developers hang,
Postgres has multiple schemas, which are logical separations of tables inside a database. Musicbrainz is in a schema called musicbrainz - perhaps this isn’t automatically set when you log in to postgres.
Try and run this in your psql shell before running a command:
Just to confirm, I think you have the following setup:
[mac] -> [virtualbox] -> [musicbrainz vm]
The fact that you get an error message from postgres (“FATAL: password authentication failed”) is good, but I have a funny feeling that you are also running postgres on your mac. Is this the case? If so, you’re trying to connect to it from PSequel (port 5432) and it’s not working, because this is not the musicbrainz database!
In order to connect to the musicbrainz vm database you need to do the following:
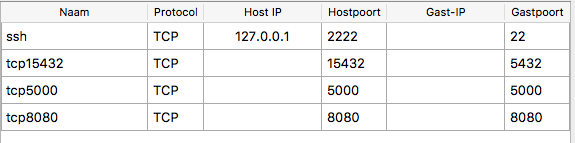
Make sure that virtualbox has port forwarding: Go to machine settings in virtualbox → Network → Adapter 1 → Advanced → Port forwarding. Make sure there is a line tcp15432 / TCP / / 15432 / / 5432"
On your mac, connect to Host: localhost, Port 15432. This will go from the mac to virtualbox, then into docker, then to the postgres database.
With the patch from 2. applied you should also be able to connect inside an ssh connection (inside the virtualbox vm) to host localhost, port 5432, instead of having to use 172.17.0.4.
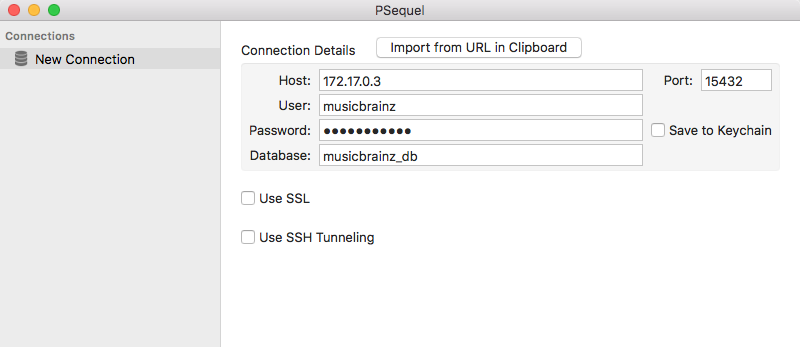
I’m going to need to study a bit tomorrow to find out how to accomplish step 2. For now I did try steps 1. and 3. because I thought that might work. Port forwarding seems correct and for now I just kept the IP instead of localhost, but it didn’t work (error is still “timeout expired”, I guess step 2. is necessary either way?).
Here’s some screenshots of port forwarding rules and PSequel connection:
Do I need to find a way to run these scripts first? I thought the vm was all ready to do queries, so I assumed I didn’t need to do it anymore, but I’m starting to feel I was wrong about that?
I’m sorry if I’m missing obvious steps, this is all very new to me. I really appreciate the help!
Hi!
It’s great to see more academics using the MusicBrainz data, there is definitely a lot of interesting data to do things with.
It looks like you’ve run into one of the first issues people tend to encounter when they first look at MusicBrainz - the structure of the database is quite complex. This is because (as I’m sure you’re aware) recorded music is itself complex. Some of your queries are easy to calculate (e.g. all artists). Others are a bit more complex.
It’s not clear here if you want just a list of all album names in musicbrainz (easy), or that same list linked with the album’s artist, which is a bit more difficult
albums can have more than 1 artist, so “just putting it in csv” requires a bit of forethought
if an artist appears on just one track on an album do you want it to appear as an album artist?
many albums have their artist listed as “Various artists” or “Soundtrack”. How do you want to deal with these ones?
Do you want only officially released albums/singles/eps, or also promo material, compilations, live bootlegs, etc?
There is another series of similar questions for songs. This is why we recommended first trying to understand the data model or webservice of musicbrainz a little more. This will help you more specifically formulate your questions, which will help us to better answer them.
I’m not sure what tools and programming languages you are familiar with. If you use python, there is a great library called mbdata which abstracts away much of the SQL from the musicbrainz database and let’s you deal with more abstract concepts. Here is an example of using mbdata to get artists from the database and write them to a csv file:
import csv
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from mbdata.models import Artist
engine = create_engine('postgresql://musicbrainz:musicbrainz@127.0.0.1/musicbrainz')
Session = sessionmaker(bind=engine)
session = Session()
artists = session.query(Artist).limit(100).all()
with open("some-artists.csv", "w") as fp:
writer = csv.writer(fp)
for a in artists:
writer.writerow([a.gid, a.name])
The value of the port forwarding in virtualbox is correct.
You should have the host as localhost in PSequel. If you don’t do step 2, then you’ll always get the “timeout expired” error when trying to connect to the database from your mac.
Step 2 does not require advanced sysadmin skills, this should work:
Log into the virtual machine (it looks like you can already do this, great!)
cd musicbrainz/musicbrainz-docker
nano docker-compose.yml
move to line 15 below the lines
expose:
- "5432"
add the new text:
ports:
- "5432:5432"
Make sure that the indentation (spaces) is the same as the above expose block.
save the file - ctrl-x, say 'y' when it asks if you want to save, press return to save with the given name.
Reset the containers:
cd ../..
./bin/reset-containers
Once this is done you should be able to access the database from the mac.
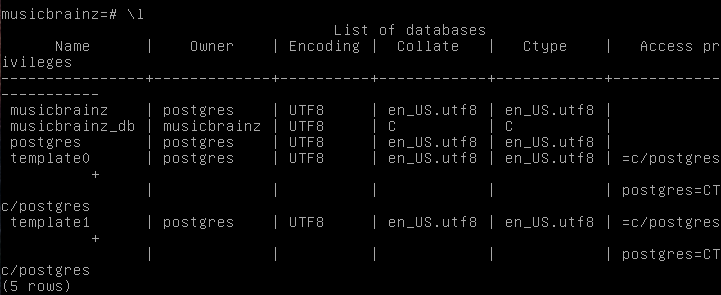
Cool, the search path looks correct, although I see in your \l output that there is both a musicbrainz and musicbrainz_db database. I suspect you want to be looking in the second one.
Hey! Sorry for not getting back sooner, but I have been working hard on this the past couple of weeks. It turned out that the .json dumps contained everything I needed for now (just had to merge information from different dumps, but with the mb id’s that’s no problem), so I just jumped into it right away. So thanks for referring me to those (and jq), that has been extremely helpful!
I still tried to get the server to work with PSequel, since it might be an easier way to access the data if I need them in the future, but I couldn’t get there. I tried applying the patch (step 2), following your instructions, but then I got an error resetting the containers (forgot to screenshot it and it’s some time ago so I don’t remember which one, sorry). Also tried deleting everything related to SQL and the MB server and installing it from scratch, to make sure I didn’t make any weird mistakes before that were still affecting me, but didn’t work.
I hope I have some more time in the future to play around with it, and get it to work, but for now I mainly came back here to say thanks :)!
{kind=link}