Personal information
Name: Sweta Vooda
Nickname: sweta
IRC nick: sweta05
email: sweta.vooda@gmail.com
GitHub: swetavooda
Time Zone: UTC+5:30 hours
Proposal for Storage for AcousticBrainz v2 data
Overview and benefits to the community
With the increase in technology and large contributions to the music technology industry, there is always a need to keep our website data up to date and keep our clients and customers happy with fresh and latest data-carrying better analysis and new features.
Acousticbrainz is an organization which uses reference or songs from MBID and processes it to get the characteristics of music which includes low-level spectral information and information for genres, moods, keys, scales and much more characteristics and features of the song.
Acousticbrainz aims to provide music technology researchers and open source hackers with a massive database of information about music. To produce good quality data it is required to constantly update and use better tools to extract data and make it available to the world.
Therefore it is very important to have the features required to store data for new versions along with the current data and provide better training models to generate more accurate features and characteristics for the recordings.
Aim
This project aims to store data for the new version of the extractor tools in addition to data from the current version of the extractor.
Points covered in the project
Server-side
- Update the database schema to include a field for storing the version of the extractor.
- Include a field in config file to store currently supported version of the extractor in use.
- Add API to GET supported extractor version.
- Add API to validate extractor version
- Change all DataBase queries for insert and retrieve in data.py
- Changes in dataset editor to evaluate new version data.
- changes in API for dataset editor.
Client-side
- Create a validation check to verify the version of extractor used at the client-side(through API).
- Allow “already submitted” files to resubmit using the new version of the extractor and process them.
Other features for improving the efficiency of data storage
Implementation plan
Server-side
1. Update the database schema to include a field for storing a version of the extractor.
Current feature
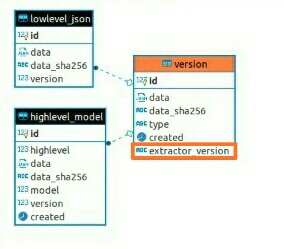
The database schema at present contains a version table, which all version details of the software used.
Following is the version table description.
Column | Type | Collation | Nullable | Default
-------------+--------------------------+-----------+----------+-------------------------------------
id | integer | | not null | nextval('version_id_seq'::regclass)
data | jsonb | | not null |
data_sha256 | character(64) | | not null |
type | version_type | | not null |
created | timestamp with time zone | | | now()
The the data field in the table stores the JSON data of version sent by the extractor tool, includes the information regarding the version of the feature extractor used, exact version the source code (git commit hash) and also an increasing version number.
Contents of data field:
data
---------------------------------------------------------------------------------------------------------------------------------------------------------
{"essentia": "2.1-beta2", "extractor": "music 1.0", "essentia_git_sha": "v2.1_beta2", "essentia_build_sha": "70f2e5ece6736b2c40cc944ad0e695b16b925413"}
problem
Since the extractor version is stores in the JSON format inside the table it makes it difficult to query the version and and use it to make changes.
Proposed changes
To explicitly tag, the low-level data sent by the client with extractor version will add a new column in version table called extractor_version.
This will help distinguish existing data and data came from the new extractor, so we can use this version information in doing further operations like retrieval, evaluation etc… on need basis.
IMPLEMENTATION
Updated schema
Query
ALTER TABLE version ADD COLUMN extractor_version DEFAULT="music 1.0";
Database schema diagram
2. Include a field in config file to store currently supported version of the extractor in use.
Add the extractor version field in the config.py file to make it easy to know the latest extractor version in use/supported by the server.
This can be used to check if the clients are using the latest version or not, and notify them to update to latest extractor version if they are using the old extractor.
IMPLEMENTATION
add EXTRACTOR_VERSION field in the config.py file and enter the latest version in use.
Example: EXTRACTOR_VERSION = “music 2.0”
# extractor
EXTRACTOR_VERSION = "music 2.0"
3. Add API to GET supported extractor version.
External and 3rd party clients should be able to get the latest version of extractor supported being used in the AcousticBrainz to give them feature to check the version we need to add API to GET version details on request.
IMPLEMENTATION
4. Add API to validate extractor version
This API is used to double-check with the client if they are using the latest version of the extractor.
Process
During the initialization of client-software and running the extractor first it should check if the client is using the latest version. To achieve this API is used.
API call
this will receive extractor version being used by the client in the request URL and will compare it with the extractor version supported by the server (which is mentioned in the config file)
- Input: extractor version at client side
- Output:
- if extractor version is same as currently supported version at server: return True/pass
- else: Display message to update extractor version.return <extractor version supported + URL for download>
5. Change all DataBase queries for insert and retrieve in data.py
a. Modify query used for storing the low-level data received from the client.
Add logic to add extractor_version:
Location: data.py file def insert_version :
IMPLEMENTATION
In this insert, the query will be adding new column extractor_version and will set it with the extractor version info retrieved in core.py(point 2 server-side)
(or) we can get extractor info from the JSON file submitted to the server.
But Extracting from JSON can be a waste of computation although it returns a True value and no chance of error.
To eliminate the chances of occurrence of errors in noting the extractor version we will follow a double-check method mentioned in point 4 server-side.
b. Change in the retrieval of low-level data (through API and views)
The present logic for retrieval of low-level data does not take the version of the extractor as a parameter and do not differentiate between versions.
Therefore multiple changes are to be made in the definitions and logic written to retrieve data.
- when API or views are used to retrieve the recording information using (/MBID/low-level)
When API is used to retrieve the low-level information of a given MBID then we need to show the latest version data
If the latest version data is not available then we need to display a message saying “The data shown is from the old version and is outdated, new version data not available”
IMPLEMENTATION
make changes in core.py and data.py
Filter the old low-level data by adding a check to find if data are available for the latest version.
if (new version data available for the recording):
call function in data.py(retrieve only new version data corresponding to the MBID)
else:#no new low-level data
if(old version data available for the recording):
call function in data.py(retrieve --only-- old version data corresponding to the MBID)
Display message saying "The data is outdated(old version)"
c. Other Functions logic to be changed
Changes in query in [GET]
def get_low_level(mbid):def count(mbid):-
def get_many_lowlevel():
Changes in the functions used to post and retrive data -
submit_low_level_data(check version and reaise exception if old version used)
Query changes required in def load_many_low_level(recordings):def count_lowlevel(mbid):def count_many_lowlevel(mbids):def get_unprocessed_highlevel_documents_for_model(highlevel_model, within=None):def get_unprocessed_highlevel_documents():def write_low_level(mbid, data, is_mbid):
6. Changes in dataset editor to evaluate new version data.
Currently, the dataset editor checks for a low-level JSON dump for given recordings and evaluates the dataset if low-level data is available.
Since we are changing version we must restrict the user to evaluate dataset using the old version of extractor because we aim to collect data for the latest version.
However, initially, we won’t be having enough data in new version therefore we must give an option to the user to evaluate the dataset using old version data or wait until enough data is collected.
To implement this many checks are to be written and logic must be refined.
Logic
- While trying to evaluate the dataset with recording having data of new extractor version
Check if enough data are available for training the model. (select a trigger)- Case I: If a significant number of the songs in the dataset don’t have data for the new version.
- Display message to the user that “not enough low-level data(new extractor version) available” and give a choice to the user
- Wait until enough data is collected (or) evaluate using old version data.
- Display message to the user that “not enough low-level data(new extractor version) available” and give a choice to the user
- Case II: If a small portion of the dataset doesn’t have the data from the new version
- Ignore the recording which doesn’t have new version data and evaluate the rest of the recodings.
- Display a message that the following didn’t get evaluated due to unavailability of data in the new version.
This work should simultaneously fix a part of the bug AB-148
- Display a message that the following didn’t get evaluated due to unavailability of data in the new version.
- Ignore the recording which doesn’t have new version data and evaluate the rest of the recodings.
- Case I: If a significant number of the songs in the dataset don’t have data for the new version.
Implementation
Add logic to check version in “dataset_eval.py” → validate_dataset_contents() to check if latest version of low-level data available
pseudo code for the above
if the number of valid recordings above limit:
Give user the option to delete invalid recordings
if selected:
call delete recordings function for the MBIDs
Create job
else:
if low-level data of old version available:
give user option to use old version data and evaluate
if selected:
create job
else:
quit
else:
raise exception
Here a problem arises the evaluator doesn’t know which version of MBID in low-level to extract load low_level data to load data of which version?
Therefore we need to store the extractor version in dataset_eval_jobs table based on the selection made by the user
Solution
Add version column to dataset_eval_jobs table and change insert query in _create_job.
Query
DB schema Diagram
After the changes are made in the database we must use the version to select the data for evaluation.
IMPLEMENTATION
changes in evaluate.py
- during evaluation process we must change the
def evaluate_dataset(eval_job, dataset_dir, storage_dir):function logic to select low-level dump for given version. - Change logic of
dump_lowlevel_datafunction to return dump for a given version.
dump_lowlevel_datamust take another parameter of version (eval_job[version]) and process.
changes in data.py - Change logic in
load_low_level(recording) - add parameter for version in
def create_groundtruth_dict(name, datadict):to insert version.(at present it is hardcoded)
7. changes in API for dataset editor.
At present, the datasets can also be created using the API so we must make sure to implement all mentioned points above in the API as well.
IMPLEMENTATION
Add checks to process the dataset before evaluation as mentioned earlier in point 6 server-side
Client-Side
1. Create a validation check to verify the version of extractor used at the client-side(through API).
When the client is submitting the files for extraction we must first check the version of extractor used by the client.
This should be done before the extraction process starts to avoid unnecessary computation and producing outdated data.
IMPLEMENTATION
-
In the client initialization check version of the extractor, send extractor version to the server to check compatibility.
if the response from the server is TRUE then proceed with normal
else stop the further flow and show message received from the server -
Handling old client which does not have server supported version check
2. Allow “already submitted” files to resubmit using the new version of the extractor and process them.
After client downloads the latest extractor version there is a possibility that few of the old files don’t get evaluated because they have already been processed. In that case, we must check if the already extracted/processed files using the latest version of the extractor or not.
- if they were used then ignore these files.
- otherwise allow these files to be processed.
Solution
The client uses an SQLite database to store the entries of submitted files
The table stores:“status” and “directory of file”
So we can add a version column to the table and process files again if used old extractor.
a. Update SQLite table schema
Implementation
Alter table to add version column
def alter_table_sqlite(dbfile):
conn = sqlite3.connect(dbfile)
c = conn.cursor()
c.execute("""alter table filelog add column version text""")
conn.commit()
b. to check if the files previously evaluated used latest version
Implementation
change def is_processed(filepath): to additionally add logic to check the version in which the file got processed.
c. During extraction update the version of extractor used
Implementation
- add function to insert version for a file
def add_version_to_filelist(filepath,version): - after process the process call
add_version_to_filelistand send version as a paramenter.
Other features for optimisation
The data from the new version of the extractor will be 10x larger than the current extractor so we need to improve the way that this is stored in the server.
SOLUTION
We can use JSON to CSV converter and store the data in the file system using the directory structure as follows:
lowlevel_json
├── llid1
│ ├── offset1
│ ├── offset2
│ └── offset3
└── llid2
├── offset1
├── offset2
├── offset3
└── offset4
Timeline
Here is a detailed Timeline of 13 weeks of GSOC coding period.
Also, the required documentation for API and new changes will be updated simultaneously while working with the code.
coding → testing(scripts) → testing integration → documentation
Before community bonding period(April):
Contribute more to the organization by fixing some more bugs and adding features.
Learn more about data compression techniques to store and retrieve huge data.
Community Bonding period:
I will spend time learning more about python unit testing, docker and understanding more deeper about AcousticBrainz functionalities and data compression techniques.
Getting more acquainted with the members of the organization discuss the project much more and planning for the coding period.
Brainstorm to find more efficient ways to store JSON files.
Week 1:
the database schema changes config changes and changes the logic for submitting functions. (server-side points 1,2,5a)
Week 2:
Make required changes to mentioned functions in point 5 of server-side.
Week 3:
API changes point (server-side points 3,4)
Week 4:
writing test scripts
Phase 1 Evaluation here
Week 5:
Client-side changes for validation (client-side points 1)
Week 6:
allow already submitted files to submit again (client-side points 2)
Week 7:
test scripts and server-client integration testing
Week 8:
start dataset editor changes schema changes and (evaluate.py) (server-side points 6)
Phase 2 Evaluation here
Week 9:
finish changes in dataset editor and make API changes for datasets (server-side points 6)
Week 10:
write test scripts
Week 11:
buffer period and documentation and finish testing
Week 12:
Work on efficient ways to store data in the file system rather than in the database
Week 13:
Buffer period
Additional Ideas
Plans on compressing JSON data to a more compact and easier structure to store and serialize because with the increase in the version that can become larger and costly to process and transfer.
Detailed information about yourself
I am a 2nd-year student pursuing a Btech in Information Technology at Keshav Memorial Institute of Technology, India.
I was very eager to contribute to an open-source organization and started searching for the most suitable organization that interests me.
I came across MetaBrainz and was very inclined towards this organization since the beginning.
I love coding and music and found AcousticBrainz to be the best match for my interests. The goal of AcousticBrainz fascinated me to contribute to the organization.
Tell us about the computer(s) you have available for working on your SoC project!
I have a Lenovo IdeaPad with intel core i5 7th generation,256 SSD and 8GB RAM with Dual BOOT windows and UBUNTU.
When did you first start programming?
I wrote my first hello world program in the mid of high school
What type of music do you listen to?
I mostly listen to melody and classical songs.
Some of the songs I like on MusicBrainz.(MBID)
Have you ever used MusicBrainz to tag your files?
Yes, only to test the client-side process and learn more but now that I have learnt how to use it I will surely try using them in future for my music purposes.
Have you contributed to other Open Source projects? If so, which projects and can we see some of your code? If you have not contributed to open source projects, do you have other code we can look at?
No, AcousticBrainz is the first open-source organization that I have contributed to but I have some of the pieces of code I wrote as a part of my college hackathons and classes, you can check them here.
What sorts of programming projects have you done on your own time?
I participated in some competitive programming competitions and participate regularly in college hackathons.
I am also a senior developer of our college e-magazine Which is revamped regularly and maintained by the students of my college, I am also a mentor this year and mentor 3 juniors and help them learn technologies and implement them to maintain the website.
How much time do you have available, and how would you plan to use it?
I am free all summer except according to my college schedule classes shall resume from mid-July but due to COVID-19 situation in my country we are not sure of the schedule. However, I plan to give 30-35 hours a week to this project and easily about 3-4 hours after college reopens.
Do you plan to have a job or study during the summer in conjunction with Summer of Code?
No