Project Summary
-
Title: GraphQL server as a MusicBrainz API alternative
-
Proposed mentors: @bitmap , @jadedblueeyes
-
Languages/skills: Rust, GraphQL,
SQL
-
Estimated Project Length: 350 hours
Expected Outcomes
- Working GraphQL server in Rust covering a specific subset of entity types
- Schema design with depth limiting and query cost analysis
- Performance baseline established through load testing, with caching applied only when justified.
Extension Objectives
- Cover additional relatable entity types beyond the initial subset
- Add new database indexes or materialised views to support expensive links
- Integrate with other MetaBrainz projects
Contact Information
- matrix: @op3kay
- email: sreeharirathish128@email.com
- github: owlpharoah
- my page where i dump stuff periodically: site
- Timezone: IST
Personal Introduction
Hi everyone! I’m Hari, also known online as owlpharoah(op3kay), and I’m a second year student at IIIT Jabalpur. I’ve been an avid music fan ever since I was a child. I was bought up in a household of artists and music played a huge role in my early years. I also really enjoy Rust and backend programming, so this project of building a GraphQL server as a MusicBrainz API alternative felt like a sweet dream come true ![]()
Why This Project
The current MusicBrainz XML/JSON API works, but its not really optimal. You need a bunch of inc parameters to get related data, browsing support is not even across entity types, and you cant really look up five artists at once.
GraphQL is a really good fit here. It handles asked feilds with asked relationships without custom server logic per link type and multi entity lookup is possible. Query depth and cost can be analysed/limited before execution rather than after the database has already been hit. And this is something I’d want to spend the summer on.
Prior Work
Before writing this proposal, I built a rough prototype to validate the approach and get a better feel for the real problems. It covers Artist, Release Group, Release, and Recording focusing on basic field resolution, relationship between them, and an enforcable depth limit set at the schema level. The stack is async-graphql, sqlx, and Axum, which is what I’d use for the real thing.
Building it showed me a few issues I’ll need to focus on:
N+1 queries
In the prototype, resolving artist_type, gender, and area on an Artist each fire a separate query. That’s fine for a single artist lookup, but would be really hard on the server if it were for a list. DataLoaders fix this by batching, sometimes working somewhat like a schema level cache.
Depth limiting
async-graphql makes direct depth limiting pretty easy, but it doesn’t catch everything. A shallow query could still be expensive. Queries for different types will have to be analysed individually, assigned certain weights and an overall query cost limit must also be implemented
let schema = Schema::build(...).limit_complexity(200).limit_depth(5).data(pool).finish();
#[ComplexObject]
impl Artist{
#[graphql(complexity = "10 * child_complexity")] #create weights
async fn release(&self,..) -> async_graphql::Result<Vec<Release>>{...}
Proposed Project
Scope
Rather than trying to cover everything, I’ll pick a focused subset of entity types and do them properly. My current plan is:
-
First Priority Entity Fields: Artist, Release, Release Group, Recording, Label
-
Core fields:
-
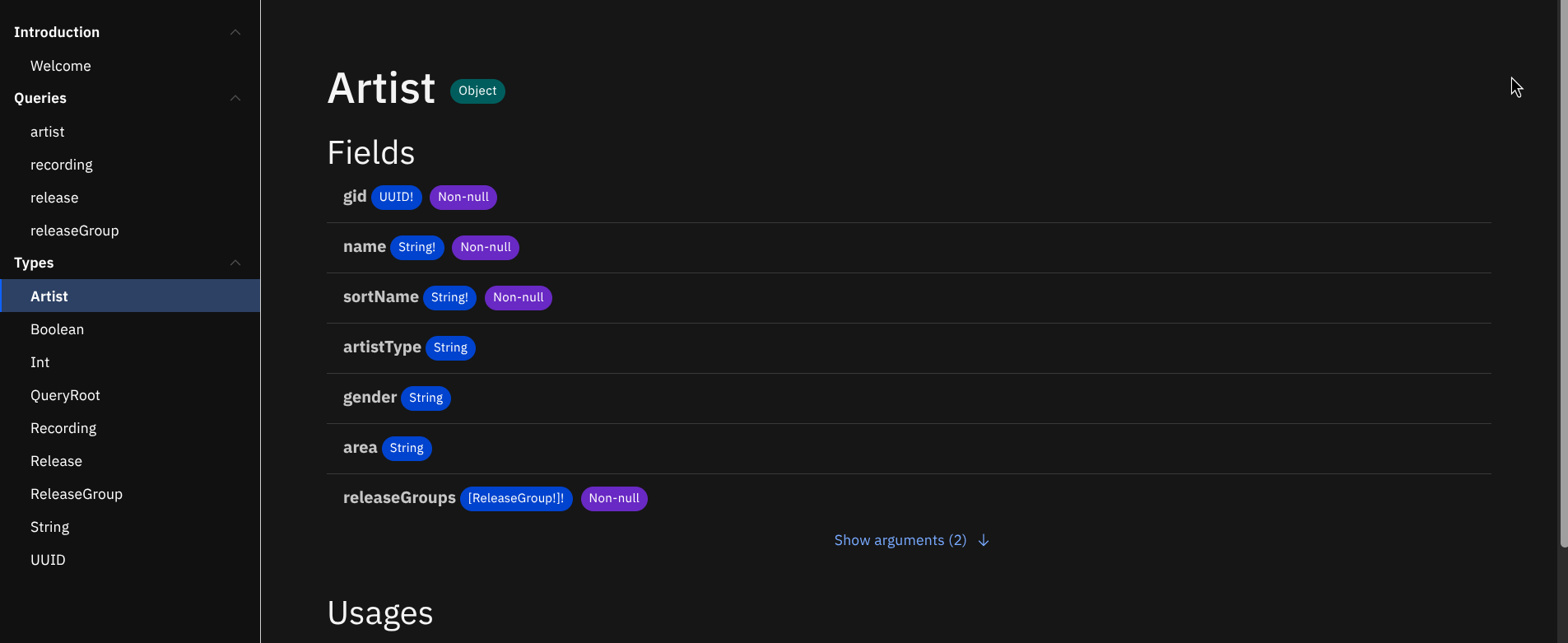
Artist
type Artist { mbid: ID! name: String! sortName: String! disambiguation: String type: String gender: String area: Area beginArea: Area endArea: Area beginDate: PartialDate endDate: PartialDate ended: Boolean! country: String ipis: [String!]! isnis: [String!]! aliases: [Alias!]! tags: [Tag!]! genres: [Genre!]! rating: Rating annotation: String releaseGroups: [ReleaseGroup!]! releases: [Release!]! } -
Release Group
type ReleaseGroup { mbid: ID! name: String! disambiguation: String primaryType: String secondaryTypes: [String!]! artistCredit: [ArtistCredit!]! firstReleaseDate: PartialDate releases: [Release!]! aliases: [Alias!]! tags: [Tag!]! genres: [Genre!]! rating: Rating annotation: String } -
Release
type Release { mbid: ID! name: String! disambiguation: String status: String quality: String packaging: String date: PartialDate country: String barcode: String asin: String language: String script: String artistCredit: [ArtistCredit!]! releaseGroup: ReleaseGroup labelInfo: [LabelInfo!]! releaseEvents: [ReleaseEvent!]! media: [Medium!]! coverArtArchive: CoverArtArchive aliases: [Alias!]! tags: [Tag!]! genres: [Genre!]! annotation: String } -
Recording
type Recording { mbid: ID! name: String! disambiguation: String length: Int video: Boolean artistCredit: [ArtistCredit!]! isrcs: [String!]! firstReleaseDate: PartialDate releases: [Release!]! aliases: [Alias!]! tags: [Tag!]! genres: [Genre!]! rating: Rating annotation: String } -
Label
type Label { mbid: ID! name: String! sortName: String disambiguation: String type: String country: String area: Area labelCode: Int beginDate: PartialDate endDate: PartialDate ended: Boolean! ipis: [String!]! isnis: [String!]! releases: [Release!]! aliases: [Alias!]! tags: [Tag!]! genres: [Genre!]! rating: Rating annotation: String }
-
-
Standard relationships between them
-
URL relationships
-
There are a few other types which will be reused often:
-
ArtistCredit-artist: Artist!,name: String!,join_phrase: String! -
PartialDate-year: Int,month: Int,day: Int. -
Area-mbid: ID!,name: String!,disambiguation: String,sort_name: String,type: String. This could be included in the scope to make it queryable. -
Alias-name: String!,sortName: String,type: String,primary: Boolean,beginDate: PartialDate,endDate: PartialDate,ended: Boolean! -
Medium-format: String,position: Int!,title: String,trackCount: Int!,tracks: [Track!]! -
Track-mbid: ID!,title: String!,number: String!,position: Int!,length: Int,recording: Recording!Release to Recording is mapped through medium and track.
-
LabelInfo-label: Label,catalogNumber: String. -
ReleaseEvent-date: PartialDate,country: String. -
Tag-name: String!,count: Int!. -
Genre-mbid: ID!,name: String!,disambiguation: String. -
Rating-value: Int!,votesCount: Int!.
-
-
Lookup directions supported:
- Artist → release groups, releases (
artist_releaseandartist_release_groupmaterialized views) - Release Group → releases
- Release → media → tracks → recordings
- Release → label (via
LabelInfo) - Release → release events
- Recording → releases (reverse)
- Label → releases (reverse)
- All entities → aliases, tags, genres, ratings
- Artist → release groups, releases (
-
Materialized Views Used:
artist_release- artist → releasesartist_release_group- artist → release groupsrecording_first_release_date- first release date per recordingrelease_first_release_date- first release date per release
Schema Design
A sketch of the Artist type:
#[derive(SimpleObject)]
#[graphql(complex)]
pub struct Artist {
pub mbid: Uuid,
pub name: String,
#[graphql(name = "sortName")]
pub sort_name: String,
pub disambiguation: Option<String>,
#[graphql(skip)]
pub id: i32,// internal DB id ie not exposed
}
#[ComplexObject]
impl Artist {
async fn area(&self, ctx: &Context<'_>) -> async_graphql::Result<Option<String>> { ... }
async fn release_groups(&self,...) -> async_graphql::Result<Vec<ReleaseGroup>> { ... }
#[graphql(name = "beginDate")]
async fn begin_date(&self,...) -> async_graphql::Result<Option<PartialDate>> { ... }
}
A similar sketch for Artist credit would be:
type ArtistCredit {
artist: Artist!
name: String!
joinPhrase: String # e.g. "&","feat.",etc..
}
Partial Date would be:
type PartialDate {
year: Int
month: Int
day: Int
}
Pagination would be done using keyset pagination. It uses the conept of WHERE id > $cursor .
releaseGroups(first: Int, after: String): [ReleaseGroup!]!
here after is the cursor and first is essentially the limit.
Lookup
Every entity is looked up by its MBID
type Query {
artist(mbid: ID!): Artist
artists(mbids: [ID!]!): [Artist]!
release(mbid: ID!): Release
releases(mbids: [ID!]!): [Release]!
}
# and so on
Input validation - An invalid MBID returns an error immediately without touching the database. All MBIDs are UUIDs and hence are parsed as such to see if its valid.
Not found - a valid MBID that doesn’t exist returns null . (After checking redirects).
MBID redirects - Before a not found(null) is sent, it will be cross checked in the *_gid_redirect table and if its a hit the new data will be sent. If still a miss, null will be sent.
Architecture
The server will be written using:
- async-graphql: Solid support for DataLoader pattern, query depth and complexity limiting.
- sqlx: the actual database connection & queries will be handled by this
- axum: The framework for the server
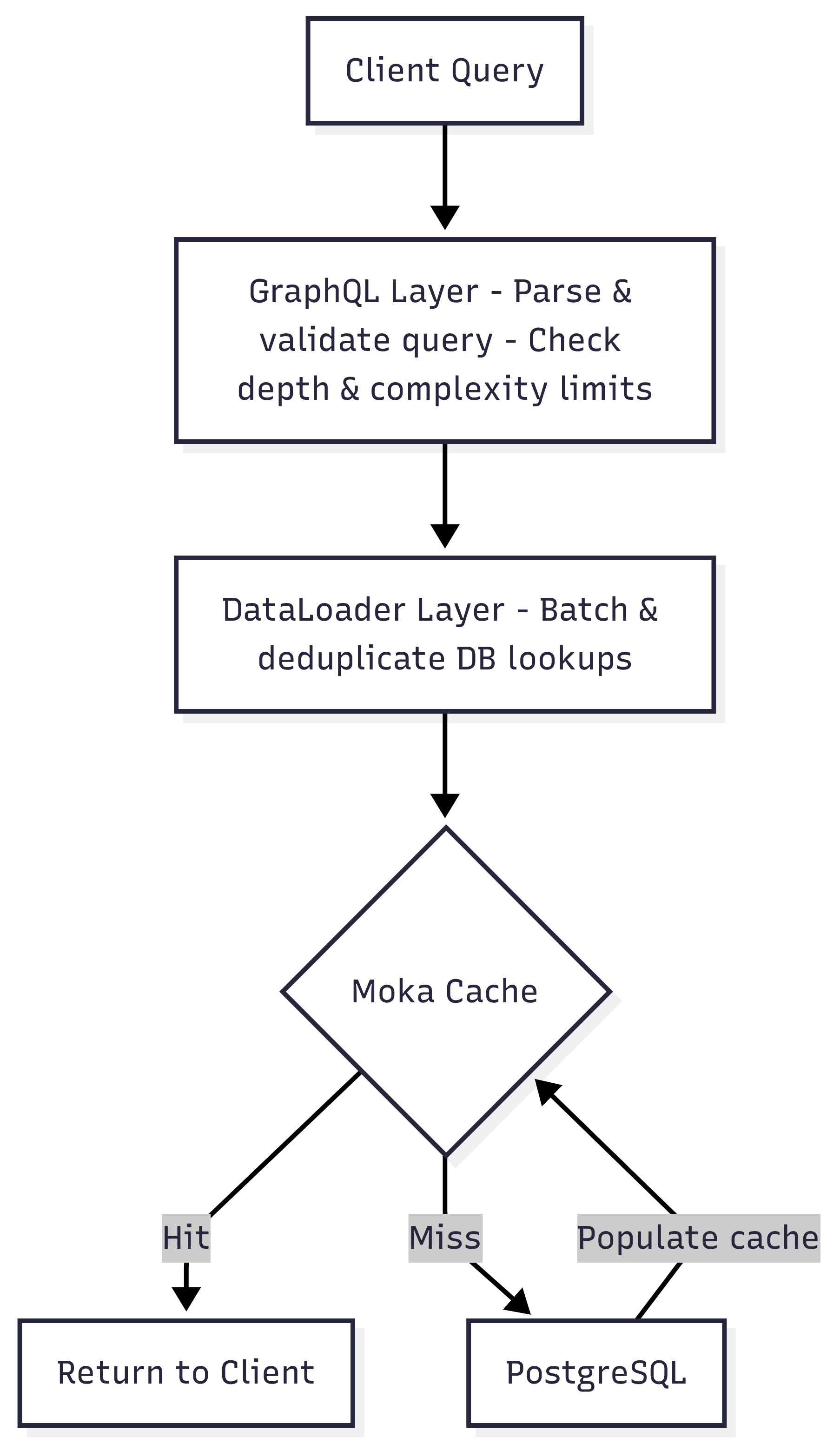
Here’s how a request flows through the system:
Query Safety
Depth limiting is handled by async-graphql’s built-in .limit_depth(n) - set at schema build time.
Complexity analysis - Each resolver is assigned a cost weight using async-graphql’s #[graphql(complexity = ...)] attribute. A simple field like name costs 1. A relationship resolver that triggers a DB join costs more. The total cost is checked before execution
#[graphql(complexity = "10 * child_complexity")]
async fn release(...) -> async_graphql::Result<Vec<Release>>{...}
Queries that exceed the cost threshold are rejected before any databases work starts.
Blocked links - some relationships are expensive regardless of depth or complexity. Whether a link gets blocked, gets a new index, or gets a materialised view is determined during Week 6 profiling.
Caching Strategy
The caching will be in two levels, both in process so as to reduce external dependencies or extra server requirements:
-
DataLoader batching: within a single request, identical lookups are deduplicated automatically. For example,
ReleaseGroupsByArtistLoaderwould take in a list of artists and returns ReleaseGroups for each of those artists with deduplicated results.impl Loader<i32> for ReleaseGroupsByArtistLoader { type Value = Vec<ReleaseGroup>; type Error = async_graphql::Error; async fn load(&self, keys: &[i32]) -> Result<HashMap<i32, Self::Value>, Self::Error> {...} -
moka response cache: entity reads are cached in-process with a TTL . It runs in the same process and evicts least used cache hence promising performance.
Testing
Integration tests: These verify that the server returns correct/expected data for known query-responses They also assert that depth and complexity limits reject queries they’re supposed to reject. This is the primary testing layer
#[tokio::test]
async fn artist_lookup_test() {
let query = r#"
{ artist(mbid: "164f0d73-1234-4e2c-8743-d77bf2191051") {
name
sortName
disambiguation
beginDate { year month day }
}
}"#;
let res = execute(&schema, query).await?;
assert_eq!(res["artist"]["name"], "Ye");
assert_eq!(res["artist"]["beginDate"]["year"], "1977");
}
Query count assertions: This will mainly be used to test if the Dataloaders and working as expected and were not facing the N+1 issue. A tiny prototype of this is implemented as dbmetrics.rs in the prototype.
Live tests: Implement GraphiQL using async_graphql’s built in graphiql for live testing
Load tests: Well be using Grafana k6 to do load testing and get a performance baseline. These tests would be used to determine whether caching is necessary and for what entitites/fields.
export let options = { stages: [
{ duration: "30s", target: 10 },
{ duration: "30s", target: 50 },
{ duration: "30s", target: 100 },
]};
export default function () {
let res = http.post("http://localhost:8000/gql", JSON.stringify({
query: `{ artist(mbid: "164f0d73-1234-4e2c-8743-d77bf2191051") { name releaseGroups { name } } }`
}), { headers: { "Content-Type": "application/json" } });
check(res, { "status 200": (r) => r.status === 200 });
}
API Documentation
API documentation will be done using magidocsCLI. It generates clean HTML pages using .graphql SDL files
Heres a snippet of it using the prototype’s SDL file:
{kind=link}
The generation of the docs could you automated in the CI so they rebuild on every schema change.
async graphql also exposes ///rust comments as description and this can be viewed in graphql.
Timeline
- Week 1
- Align with mentors on the final entity subset and schema conventions
- Set up the production project structure with CI, linting, and test scaffolding
- Start a decision log in the repo i.e running notes file updated whenever a non-obvious call is made so I wont have to reconstruct things from memory
- Project structure ready
- Week 2
- Draft the full schema for all five entity types against the actual database schema
- Modelling and writing out field names, nullability, relationship directions, how types like
Area, andMediumand presented for review - Schema draft submitted for mentor review
- Week 3
- Schema reviewed and start implementation.
- Set up the integration test
- Artist & Release Group resolvers with dataloaders.
- First two entity resolvers working.
- Set up GraphiQL for live testing
- Week 4
- Finish resolver implementation for the remaining three entity types
- Integration tests for all resolvers while writing them out simultanoeusly
- All five entities fully resolvable, N+1 issue covered by query count tests
- Week 5
- Aliases and entity identifiers across all five entity types
- Every entity has a
_aliastable and where applicable separate identifier tables - IPI Codes and ISIN Codes. - MBID redirect handling (
_gid_redirecttables) - Lookup responses match the completeness of the existing API
- Week 6
- Query depth limiting and complexity analysis
- async-graphql’s
#[graphql(complexity)]attributes applied for each resolver & depth limiting reviewed by mentors. - Pagination implemented wherever possible.
- Decide on new materialized views or blocking expensive links.
- No query should be able to bring down or harm the server
- Week 7
- Load testing and performance baseline using k6
- async-graphql’s
cache_controlapplied to resolvers wherever possble. - Documented performance baseline
- Week 8
- Performance analysis reviewed - if benchmarks justify in process caching, implement moka for the specific paths
- If not, this week goes to extended entity coverage
- Performance story complete and justified
- Week 9
- Deployment: docker setup & documentation for running the server locally
- Write final & clean
///doc comments for all fields & entities - Setup with magidocs to generate API documentation
- Server runnable by someone who just cloned the repo
- Week 10
- Schema reference documentation and final API documentation pass
- Wire magidocs onto CI so it builds on every schema change
- Make the decision log presentable and nice
- Documentation complete and presentable
- Weeks 11–12
- Buffer - something will take longer than expected, it always does
- If time allows: extend entity coverage, add materialised views for expensive links identified in Week 6 that got deferred, or improve error handling for remaining edge cases
Community Affinities
What music do you listen to?
I was bought up in a house of artists and hence developed a love for it early on. Some tracks that I play on repeat constantly:
What aspects of MusicBrainz interest you most?
The scale of it. Collecting structured metadata for all recorded music, maintained by contributors rather than a big company. Im all ups for open sourced communities and data and anyone being able to contribute in helping it grow is what excites me the most.
Programming Background
I ran my first ‘hello world’ in python back when I was a freshman in highschool. I still remember all the possibilities my mind spun up as soon as I saw the text ‘hello world’ pop up on the terminal. That moment was phenomenal and something ill never forget. After which I moved onto writing simple CLI games like a stock trading CLI game with pnl and other metrics. Another instance I still remember was using python to generate fake handwritten notes that I had to submit instead of actually writing them by hand(it actually worked ![]() ). I then went onto exploring programming languages like i was pokemon hunting from Java to Javascript, Go, C, C++ and ive finally ended up at Rust and haven’t looked back ever since.
). I then went onto exploring programming languages like i was pokemon hunting from Java to Javascript, Go, C, C++ and ive finally ended up at Rust and haven’t looked back ever since.
During this time I also started exploring web dev, made a few fun projects like gitmaps – lets you see how spread on the world map your oss contributors are. With web dev I realised backend is something I really enjoy doing and thats what im working on now.
Some other projects ive built includes:
- RFstarstarKC - CLI learning tool to learn about RFCs and their implementations using animations and markdown documents.
- VReWind - an NPM package to scaffold react tailwind projects.
- lobstorrent - CLI to find blazingly fast torrents for anything.
Practical Requirements
- Available equipment: My primary laptop runs Arch with Niri (wayland). My secondary runs windows 11. Both devices have 16gb RAM and 512gb Storage.
- Time available: My university semester ends by may 5th and from then on my summer vacations start. From that point I’m free of other commitments and can work roughly 30-35 hours a week on the project.