Introduction
Contact Information
Name: Ankit Matth
IRC nick/Matrix handle: Ankit_Matth
Email: ankitmatth101@gmail.com
Time zone: Indian Standard Time (GMT +5:30)
GitHub: Ankit-Matth
LinkedIn: ankit-matth
About Me
I am a sophomore at BRCM College of Engineering & Technology, Bahal (BRCM-CET), pursuing a B.Tech in Computer Science and Engineering. I am a Full Stack Developer with a passion for creating scalable and efficient web applications and have extensive experience with the MERN stack using TypeScript, Testing (Cypress, Jest), MySQL, and code formatting tools like ESLint, Prettier, and Husky. Additionally, I have worked on deployment using Vercel and AWS (EC2). My primary programming language is C++, but I also have a strong understanding of Python, as it is part of my college curriculum. I have participated in a hackathon, HackUniv where my team I secured 1st position, and I successfully completed Hacktoberfest 2023, making contributions to DocsGPT, for which I received a cool T-shirt as recognition.
More importantly, I am genuinely passionate about the New Calibre plugin project because it directly enhances e-book management and metadata organization, making it easier for Calibre’s users to efficiently manage their digital libraries. BookBrainz is one of the best tools for providing accurate and enriched data about editions, e-books, and more. Contributing to this project and improving how users interact with their digital collections is an exciting opportunity for me.
Additionally, this summer, I am fully committed to working on this project, as I have no other obligations—no job or university coursework. With ample free time, I am completely focused on contributing to GSoC and making a meaningful impact.
You can check out more about me here: https://ankit-matth-portfolio.vercel.app/.
Project Overview : New Calibre Plugin
Problem statement –
As stated on the ideas page, Calibre, an established open-source e-book library manager, lacks a functional BookBrainz plugin. Although a plugin previously existed, known as CaliBBre, it was abandoned several years ago. As a result, its codebase, now 8–9 years old, is outdated and incompatible with the latest versions of Calibre and modern BookBrainz.
To address this, a new installable Calibre plugin needs to be developed with essential features, such as searching for editions by name and author and improving e-book metadata. Additionally, implementing synchronization of collections between Calibre and BookBrainz is a desirable feature, though optional.
Project goals (Deliverables)
-
Revival of CaliBBre Plugin: This project aims to revive the old plugin by rewriting it from scratch, considering the outdated 8–9-year-old code. While implementing it alongside the CaliBBre, it must support modern versions of Calibre.
-
Interactive User Interface: Develop a user-friendly interface that enables users to search for editions by name and author, select and browse through search results, improve the metadata of e-book files, and sync collections between Calibre and BookBrainz.
-
Search Functionality: Implement search functionality, enabling users to search for editions by name and author directly within Calibre. This will be achieved by integrating the BookBrainz web service (API), which acts as an intermediary between the plugin and the BookBrainz database, serving as the plugin’s data provider.
-
Metadata Enhancement: Integrate features to improve metadata for e-book files, leveraging Calibre’s functionality to enhance metadata accuracy and completeness.
-
Synchronizing Collections: Develop a feature that synchronizes collections between Calibre and BookBrainz, specifically syncing BB collections (i.e., personal user collections) with their Calibre library.
-
Documentation and Support: Provide comprehensive documentation and support resources, including a user guide (compulsory) and a blog (optional, if needed), to help users install, configure, and effectively utilize the plugin.
-
Publishing the Plugin: Prepare the plugin for distribution by packaging it appropriately in a ZIP file and uploading it to a GitHub repository for public access and installation. Then, submit it in a new thread on the Calibre Plugins forum via MobileRead or publish it on other relevant platforms based on the mentor’s feedback.
A brief walkthrough of the solution
After a deep dive into the Calibre plugin’s API documentation and plugin development guide, and analyzing the style and structure of the old plugin, CaliBBre, and considering strong feedback from my mentor, I decided to refine my approach. Following mentor’s suggestion, I chose to utilize the current web service at https://api.test.bookbrainz.org/1/docs/ to implement the new plugin. I configured the plugin in such a way that the API endpoint can be easily managed using an environment variable or a setting—specifically by declaring API_URL in the plugin’s config.py file. This API_URL points to api.test.bookbrainz.org by default but can be easily switched to api.bookbrainz.org or any internal search endpoint as needed. In essence, the entire plugin is designed so that updating a single line—the API_URL—redirects all plugin requests to the desired endpoint.
Here’s a step-by-step breakdown of my implementation plan:
1. Finalizing the UI/UX
UI/UX is just as important as other aspects of the project. Before starting the coding work, a sufficient amount of time should be dedicated to designing the user interface. Several tools can be used for UI design and prototyping, such as:
- Figma (Recommended)
- QtDesigner
- Mockflow, etc.
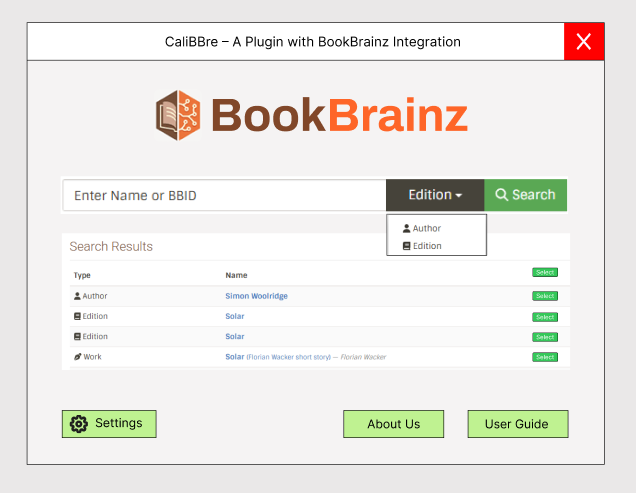
Below, I have attached some demo screenshots illustrating how I plan to implement the plugin UI :
Home Page
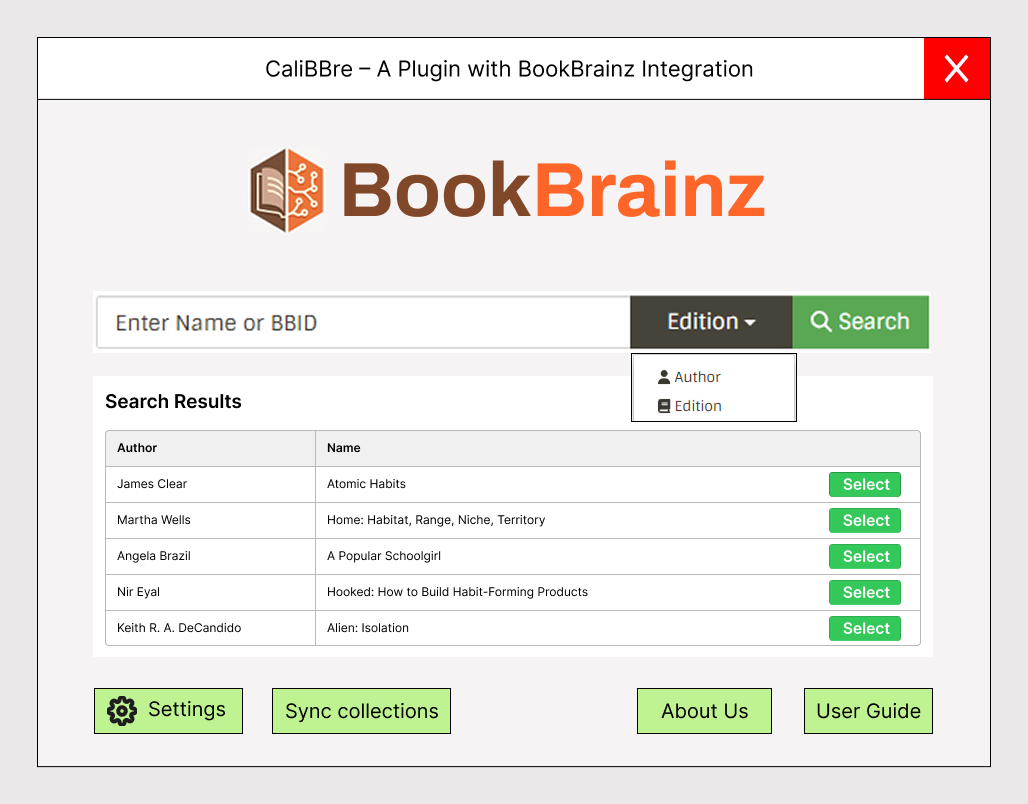
Update Metadata Page
2. Code Implementation:
After finalizing the UI, I will complete the basic setup of the plugin. I plan to work on UI development first, followed by the BookBrainz integration. This is my implementation strategy described as:
a. Searching for Editions using the BookBrainz web service:
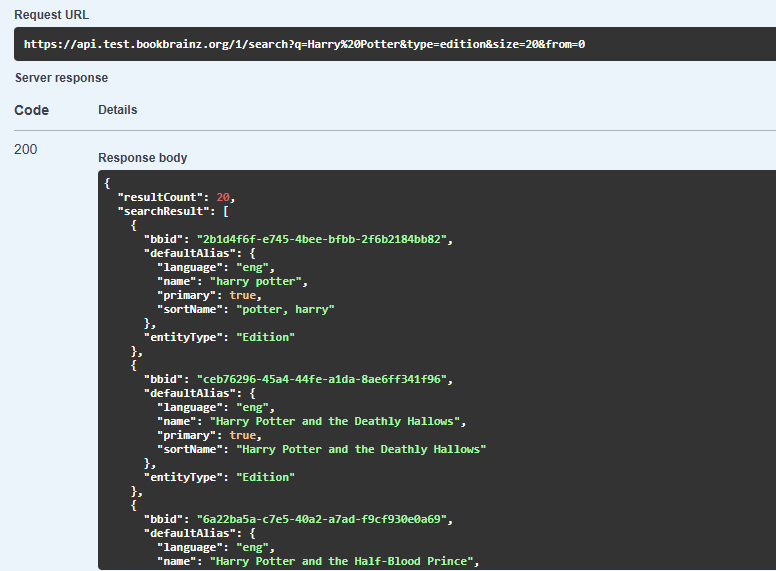
- By selecting a book from the Calibre library, users can click the plugin button in the UI interface of Calibre. If no book is selected or multiple books are selected, an error is shown. Otherwise, the plugin initiates a search for that e-book by default using the book’s title.
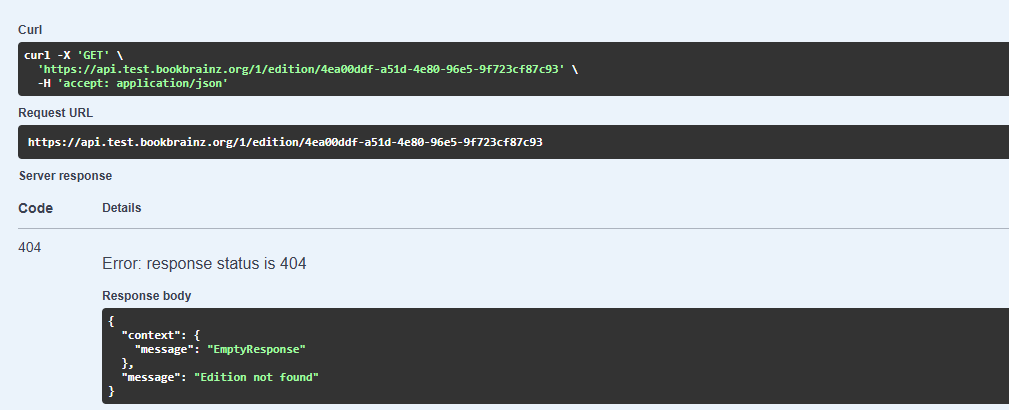
- Furthermore, users can refine their search by entering the book’s name, author, or BBID. After this UI action, the plugin constructs the URL for the search query using the user’s input and predefined search parameters. It then sends a search request to the BookBrainz web service API using an HTTP client in Python (such as httpx or requests) to retrieve the response. For example:
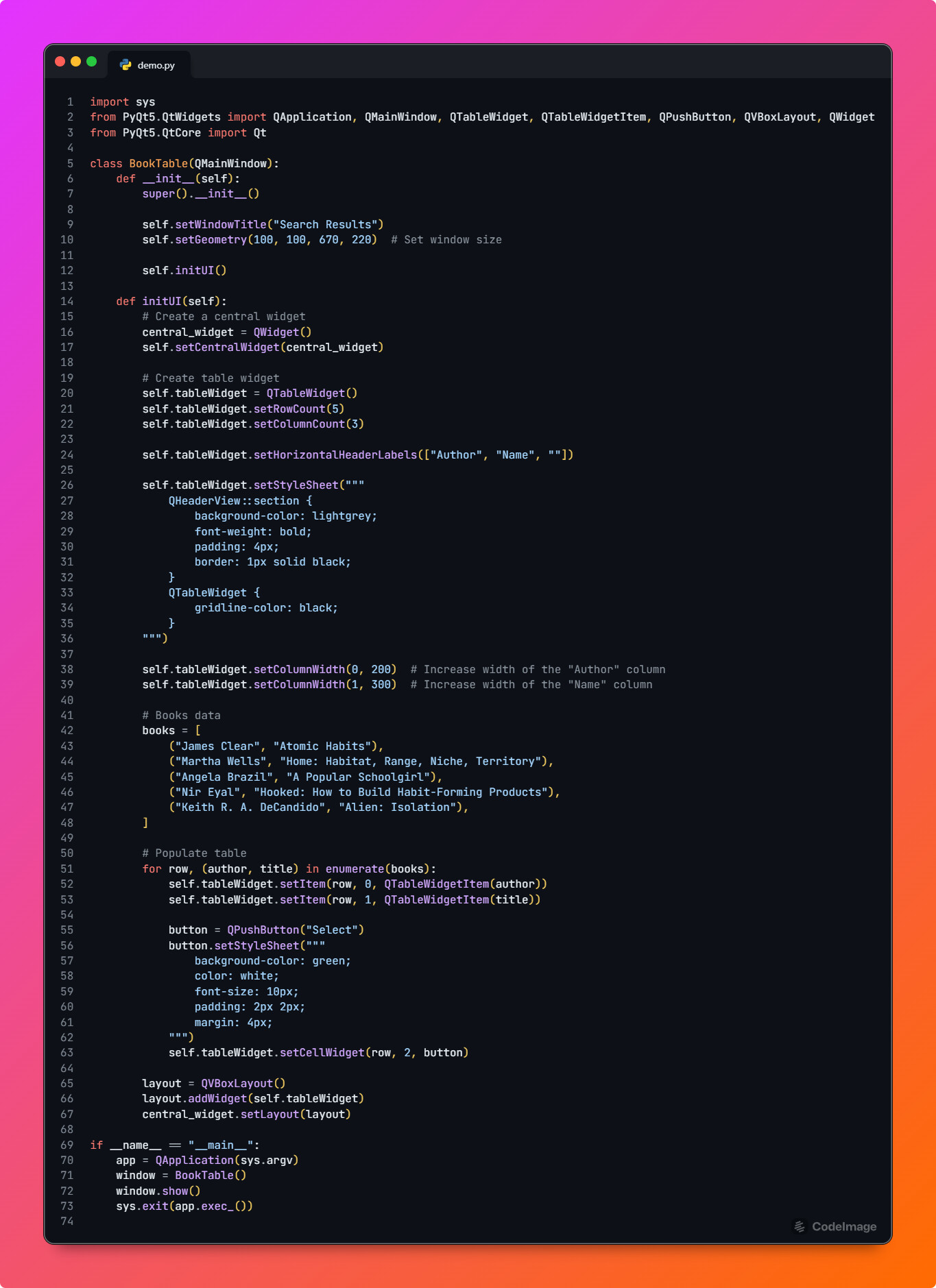
b. Displaying the search Results:
-
The BB API returns a JSON response for the search request. Since multiple editions might match a search query, users can browse the results and select the most relevant edition. These edition details are displayed in Calibre using UI components such as QListView, QTableWidget provided by PyQt5, or any other suitable UI element that best fits the workflow.
-
For example, a bare-minimum demo is shown below:
Output of above code :

c. Fetching the metadata of specific edition:
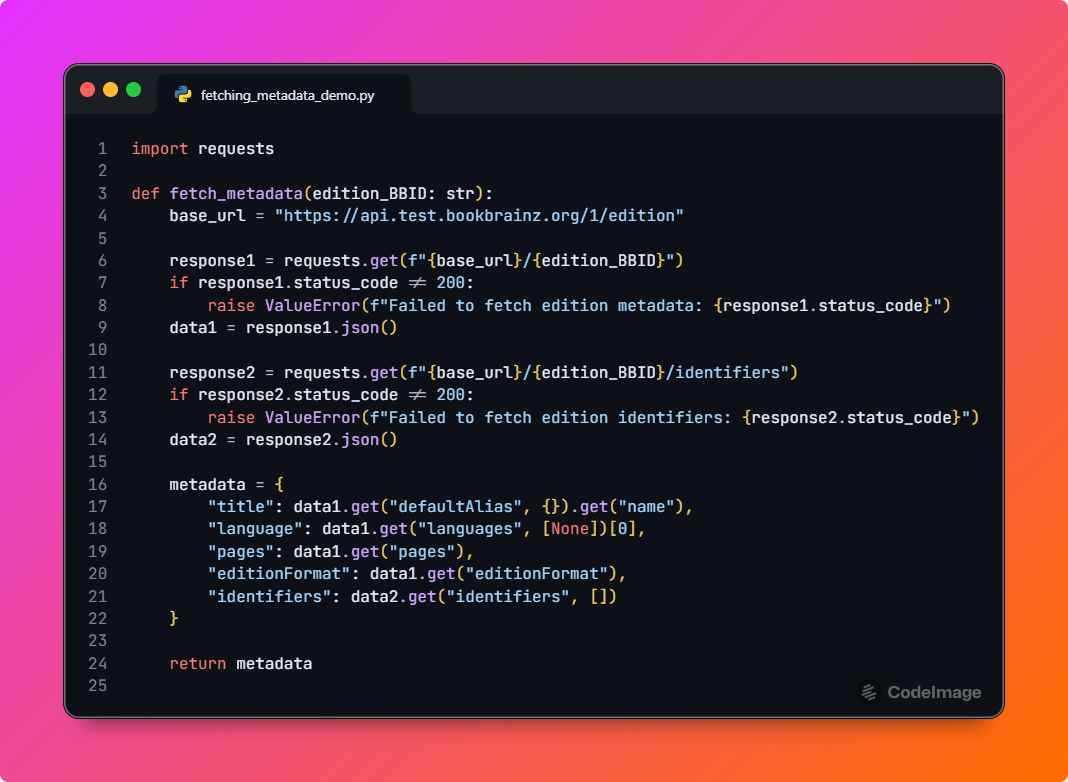
- Once the user selects an appropriately matched edition by clicking the button in the UI, the plugin sends multiple lookup requests to the BB API using the BBID (extracted from the previous response), such as:
- GET /edition/{bbid} (Lookup edition by BBID)
- GET /edition/{bbid}/identifiers (Get a list of identifiers for an edition by BBID)
- GET /author?edition={BBID} (Get a list of authors related to the edition)
-
Note: It would be more helpful for metadata retrieval if the
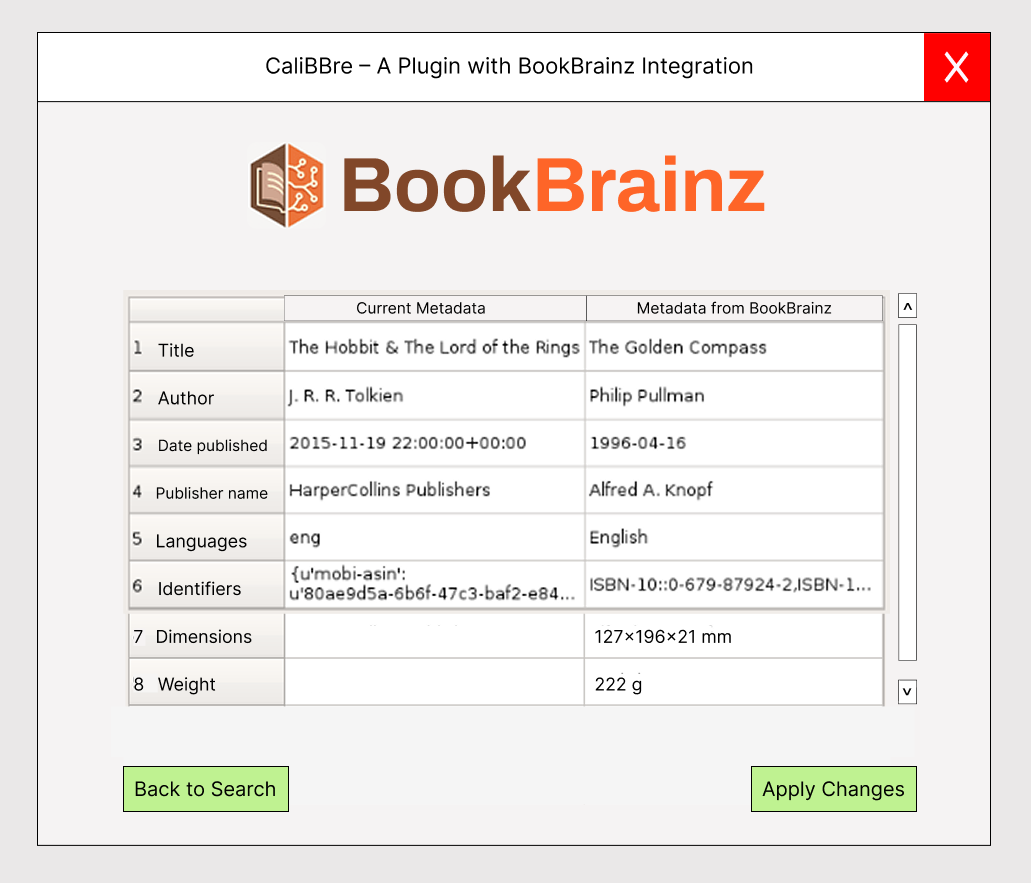
GET /edition/{bbid} requestwill updated to include additional details in the response, such as author name, release date, publishers etc.. - These API requests retrieve metadata related to the selected edition, which is then properly extracted and stored locally(let say inside a variable
fetched_metadata_from_BB). After fetching the metadata, the plugin triggers the Update Metadata dialog box, where the retrieved metadata is displayed alongside the current metadata of that edition using QTableWidget, similar to the example given above. For example,fetch_metadatacan be implemented as :
d. Updating Metadata:
- Users can update the metadata by clicking the “Apply Changes” button in the UI, which triggers the
apply_changes()function. This function utilizes Calibre’s metadata plugins (calibre.customize), which offer two main classes: MetadataReaderPlugin and MetadataWriterPlugin for updating book details. For example,set_metadata(mi, type), provided by the MetadataWriterPlugin, is used to modify metadata in both the metadata database (metadata.db) and the EPUB format metadata. Demo code -

e. Synchronizing Collections Between Calibre and BookBrainz:
-
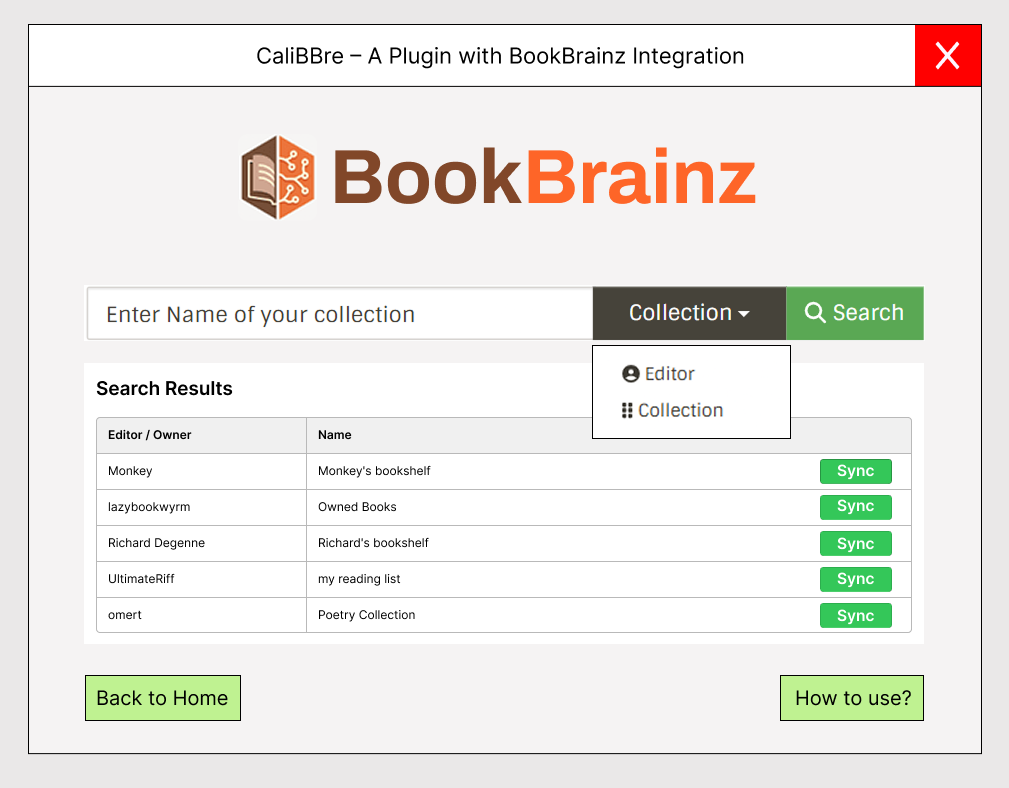
I also plan to implement an optional feature - syncing collections between Calibre and BookBrainz. Based on Monkey’s feedback, I will implement it by syncing BB collections (i.e., personal user collections) with their Calibre library. For public collections users can search for their collection using the collection name or editor/owner name. To extract information about them, the plugin makes requests using URLs like:
https://api.test.bookbrainz.org/1/search?q=Monkey&type=editor&size=20&from=0orhttps://api.test.bookbrainz.org/1/search?q=Monkey&type=collection&size=20&from=0 -
These requests return a JSON response containing matched collections. Users can browse multiple matches and select a specific collection to sync. A demo UI is shown below:
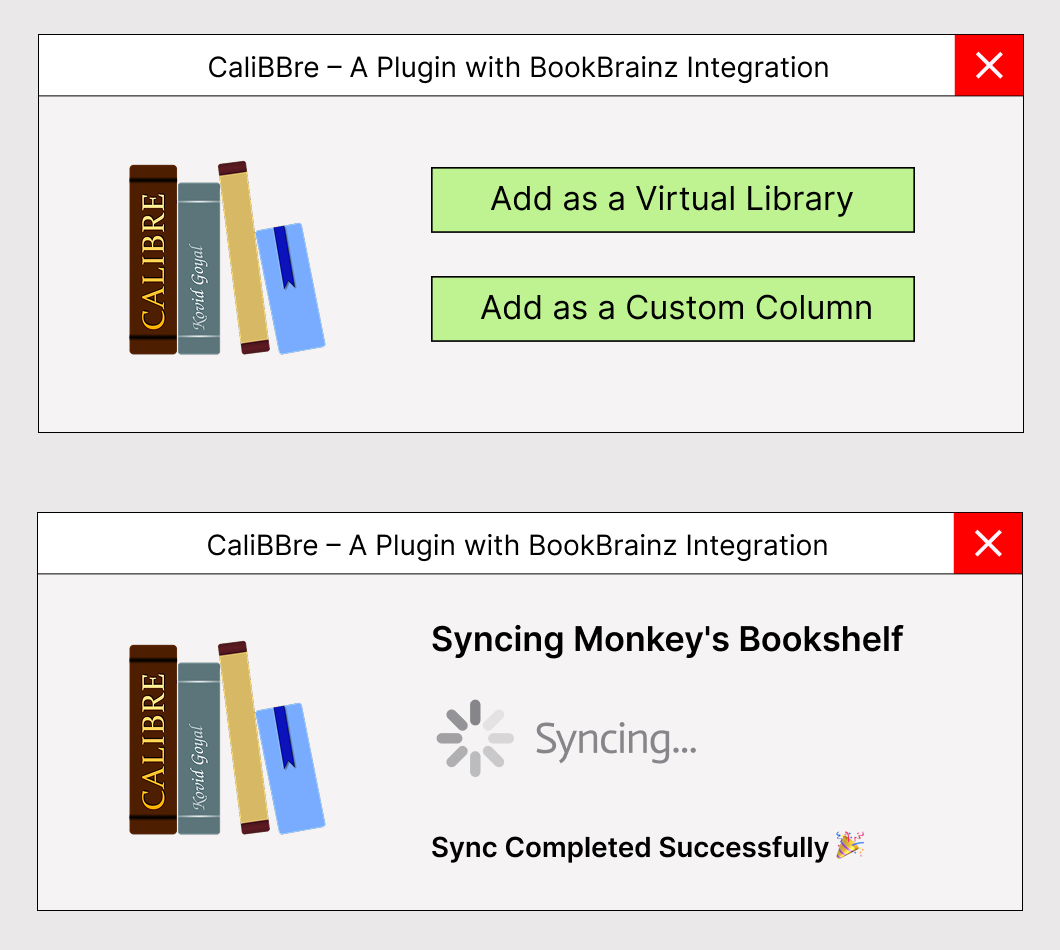
Once a user clicks the sync button for a specific collection, the plugin fetches all details about that collection. I plan to support adding a collection to Calibre in two ways, as shown in the UI demo:
When “Sync” is clicked on a collection:
First, check if the collection already exists in Calibre by querying Calibre’s database (metadata.db). If it doesn’t exist, create a new collection (Virtual Library or Custom Column) inside Calibre. If it does exist, compare and sync books, compare the books in it with the BookBrainz collection and add any missing books.calibredb add or Calibre’s APIwill be used to add books to the newly created collection. The plugin ensure that books are tagged/grouped under the synced collection name or virtual library properly. A small demo code snippet for thecalibredb addorCalibre’s APIis given as -collection_id = calibre_api.create_collection("New Collection") calibre_api.add_book_to_collection(collection_id, book) Further, which can be implemented as - calibredb add --with-library "/path/to/Calibre Library" --tags "New Collection" /path/to/book.epub -
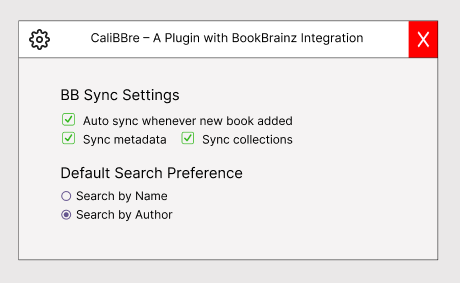
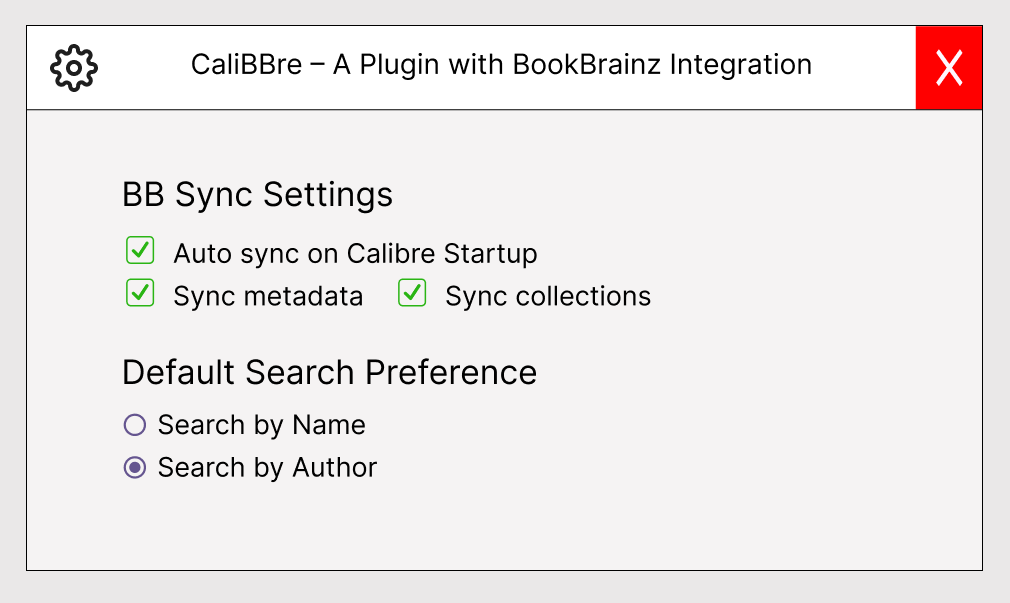
I also plan to implement an Optimized Auto-Sync Strategy, as shown in the settings dialog below:
-
The syncing mentioned here mainly focuses on metadata synchronization and further, importing books using identifiers like ISBN . For example, if users have added a book to their collection on BB, then, when they next open Calibre, the syncing process will not fetch the actual ebook file, but it will create a metadata entry for that book in their Calibre library — including fields like title, author, edition, etc., which are fetched from BB. Even if the book file isn’t present , this effectively builds a virtual library view, or a wishlist-like setup inside Calibre. It helps users to plan what books they want to read or acquire later, and when they eventually get the ebook file, they can simply match it to these existing metadata entries.
-
I call it optimized because it is an Event-Based Auto-Sync—
It triggers Auto-Sync on Calibre Startup. If new books are detected in collections or metadata updates occur, it starts syncing. If nothing has changed, it intelligently skips syncing to improve efficiency. To detect these changes, I will leverage BB’s revision system instead of relying on “last modified” timestamps (as per @mr_monkey’s feedback). This system offers a more reliable and helpful way to track changes in entities (books, editions, collections, etc.). -
Note: For this to work, the BookBrainz API needs to be updated to expose revision IDs for relevant entities. This could potentially be achieved via an endpoint like
/<entity_type>/<entity_bbid>/revisions. Once available, the plugin will use these revision IDs to determine if any entities have been updated since the last sync. -
Authentication Considerations for Accessing Private Collections
Currently, BookBrainz (BB) does not provide explicit OAuth authentication support like MusicBrainz. To access private collections, any of the following approaches may need to be implemented:
-
OAuth Bearer Token Authorization – If BB supports authorization via an Authorization: Bearer header, this can be used to access private collections after user authentication.
-
Session-Based Authentication – If BB relies on session cookies, the plugin could persist login sessions or retrieve authentication cookies to make authenticated API requests accordingly.
-
Enhanced BB API Support – Currently, BB’s API lacks a dedicated endpoint to fetch private (or even public) collections. A GET /collection/{BBID} endpoint could be added for direct collection retrieval. Alternatively, the GET /search?type=collection endpoint could be enhanced to return full collection details—including private collections—when authenticated.
These authentication mechanisms are crucial for seamless syncing of private collections between Calibre and BookBrainz. A detailed discussion and feedback session with the mentor is required to finalize the implementation approach—specifically for handling
private collections. -
3. Debugging and Testing
Software development inevitably involves bugs, and handling them efficiently is crucial for a smooth development process. I will adopt a structured debugging and testing approach to ensure the plugin’s reliability and functionality. During development irself, I will wrap critical function calls in try-except blocks to ensure that errors are logged and handled properly. Additionally, I will dedicate specific time to thoroughly check and debug the entire plugin code to catch any subtle or overlooked issues.
-
Debugging with calibre-debug -
Calibre provides a built-in command-line debugging tool called calibre-debug, which allows running and testing plugins interactively. I will use it extensively during development to test individual components of the plugin efficiently. Some useful commands includes calibre-debug -g or calibre-debug -s etc. -
Automated Testing
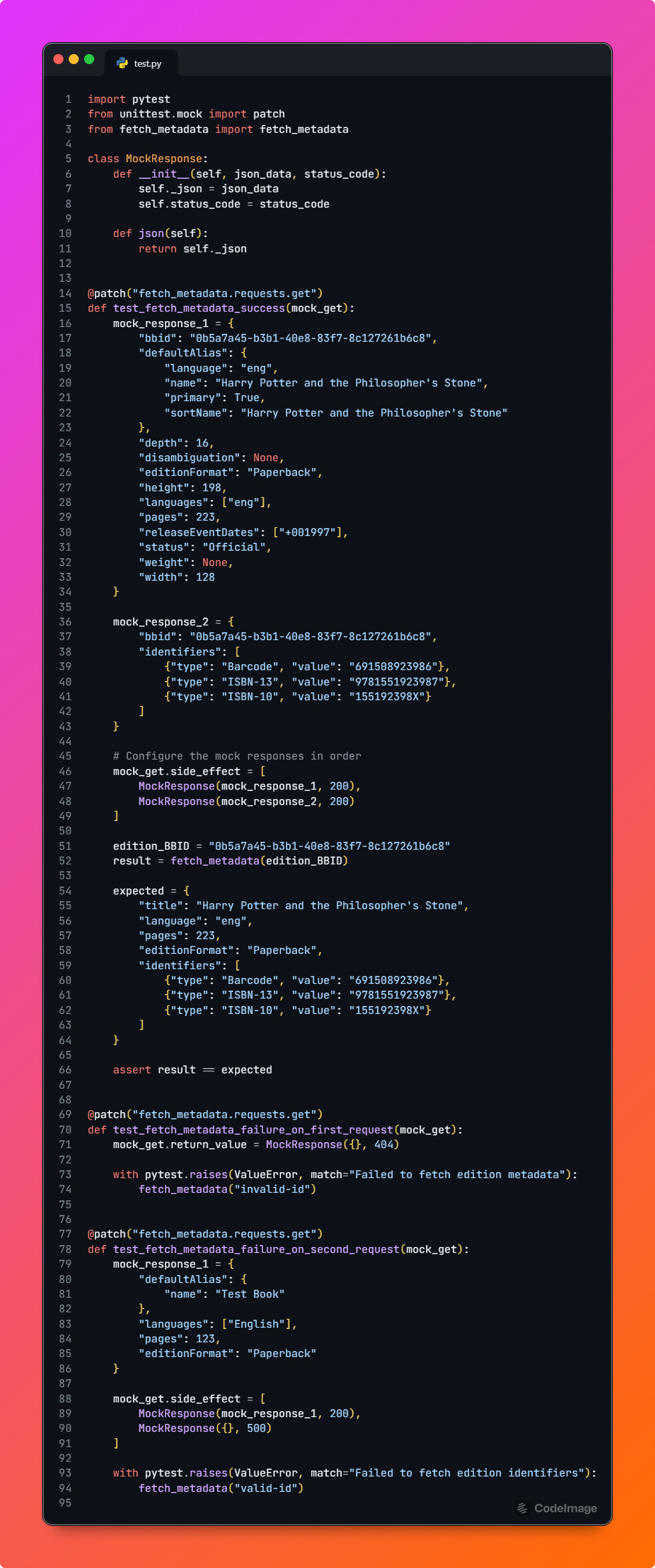
To validate core functionalities, I will write unit tests usingpytest. For mocking external API calls, I will useunittest.mock. Alternatively, libraries like responses or requests-mock can be used for declarative HTTP request mocking, but I prefer manual mocking as it’s straightforward and often more flexible for unit tests. These tests will help ensure that all critical features work as intended. I plan to structure all test cases in a dedicated test.py file to thoroughly test the plugin. For example, a test case for the metadata retrieval function(given above in fetching metadata section) might look like this:
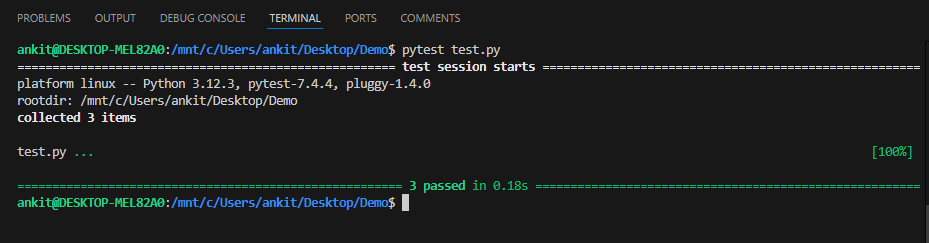
Output of above test case :
4. Documentation and Support
Like testing, documentation is a critical part of any software product, and good documentation is essential for both developers and users. I will provide the following:
-
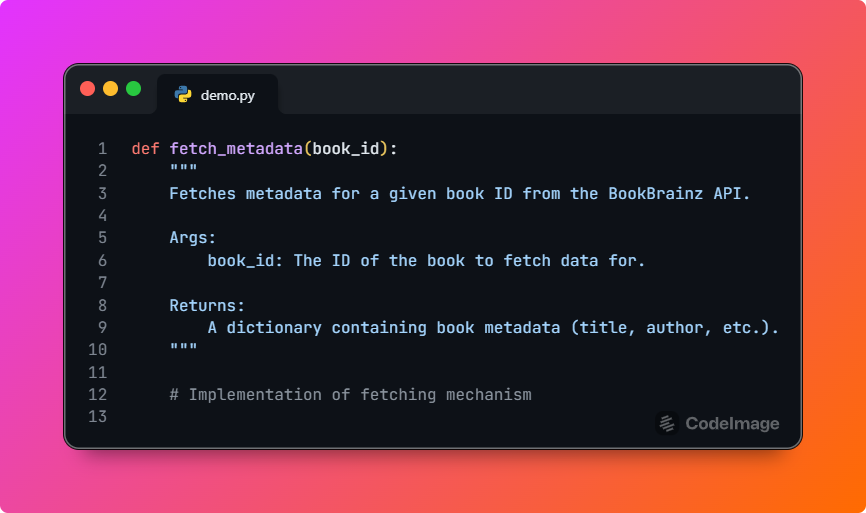
Technical Documentation: I will create developer-focused documentation explaining the internal structure of the plugin, including its modules, functions, and their interdependencies. It will also cover how metadata is retrieved and processed from BookBrainz, and how the plugin interacts with Calibre’s internal API. Additionally, I will create a detailed and useful README.md file for the plugin, including setup instructions, a user guide, and other relevant documentation. I also plan to add meaningful comments within the code, especially for important or complex functions. For example, a function like fetch_metadata(book_id) will have clear comments:
-
User Guide: A simple step-by-step guide will be created for end users, covering:
Installation: How to install the plugin via Calibre’s plugin manager.Usage: How to retrieve book metadata, update book details, and sync collections. -
Additional Resources: If needed, I will write a blog post or record a demo video showcasing the plugin’s features and explaining how users can integrate it into their workflow.
5. Packaging & Distribution
To ensure smooth distribution and installation, I will follow Calibre’s standard packaging guidelines.
-
Packaging the Plugin: Calibre plugins are packaged as .zip files containing essential files such as
main.py, ui.py, about.txt, and __init__.pyetc. I will ensure the correct folder structure is followed to allow easy installation via Calibre’s plugin manager. -
Public Distribution: Once finalized, I will submit the plugin for public distribution through Calibre’s Plugin Repository on the MobileRead Forums and also on GitHub to encourage open-source collaboration and further improvements. If required, I will additionally provide versioned releases using GitHub’s release system to ensure users can access stable and trackable updates.
Extras
Apart from that, if time permits and my mentor agrees, I would love to work on additional features that I plan to implement :
1. Bulk Metadata Verification
Instead of checking one edition at a time, allow users to verify metadata for multiple books in their Calibre library at once.
Generate a report highlighting books with complete metadata and those missing details in BookBrainz.
2. Contribution Mode: Add Books to BookBrainz
If a book does not exist in BookBrainz, allow users to submit the missing edition directly from Calibre. Provide a pre-filled form with Calibre metadata, making it easier for users to contribute new books to the database.
Post-GSoC Plan
Even after GSoC ends, I want to continue contributing to BookBrainz. If for some reason I’m unable to complete the extra features during GSoC, they will be my first priority afterward. Apart from that, there are a few areas I’d like to improve:
-
Responsiveness – Ensure a better UI across various screen sizes.
-
UI/UX Enhancements & Bug Fixes – Improve the overall design and user experience while addressing minor bugs.
-
Solr Search Server – Since search is a major pain point, I plan to contribute to improving it. Although I’m not very familiar with Solr infrastructure at the moment, I’m eager to learn and work on it in the future.
Additionally, I’ll stay engaged in discussions and contribute to future updates of the New Calibre Plugin. MetaBrainz has a fantastic open-source community, and I’d love to remain involved in the long run.
Timeline
Phase 1: Community Bonding Period & Initial Development
| Week | Technical Details |
|---|---|
| May 8 - June 1 | - Complete all tasks related to community bonding period. - Finalize detailed UI design with mentors and gather feedback. - Create missing or updated Figma designs based on suggestions. - Complete all onboarding and setup tasks (repository, issue/PR templates, contribution guide). - Interact regularly with mentors to align on expectations. |
| June 2 - June 8 | - Initialize plugin development - set up folder structure - Initial setup of the plugin that is necessary configurations - Build basic UI components - layout, Search (Home) page etc |
| June 9 - June 15 | - Implement Edition Search functionality: input handling, search by title/author/BBID. - Set up API calls to BookBrainz API and handle various responses. - Begin writing internal documentation for project setup and API integration decisions. - Display results in a user-friendly list. |
| June 16 - June 22 | - Add unit tests for search logic. - Implement metadata extraction for selected edition: fetch and parse relevant data (title, authors, identifiers, etc). - Create UI component and display metadata in it. - Write integration tests for fetching and displaying metadata. |
| June 23 - June 29 | - Add in-code comments and update the documentation. - Implement metadata update functionality - allow users to save changes. - Write unit and functional tests for metadata update functionality |
| June 30 - July 6 | - Test complete flow: search → select edition → fetch metadata → save. - Create user guide with detailed instructions - Write test cases for all remaining implemented functionalities |
| July 7 - July 13 | - Complete documentation of entire workflow. - Create and implement dialogue boxes for UI components like About Us or User Guide etc. - Write test cases for these functionalities - Add in-code comments etc. |
Midterm Evaluation (July 14 - July 18)
Focus on submitting the midterm evaluation, bug fixes, and feedback from mentors.
Phase 2: Final Touches to the Plugin & Work on Extras
| Week | Technical Details |
|---|---|
| July 19 - July 25 | - Fix bugs or incomplete tasks(if any) from Phase 1. - Implement collection search and result display. - Write accompanying tests and update internal documentation. |
| July 26 - August 1 | - Complete collection sync implementation: fetch and map local and remote collections. - Implement UI for sync status display - Setup logic to handle private/public collections. - Write tests for sync scenarios and implement proper error handling. |
| August 2 - August 8 | - Implement Auto-Sync Strategy - Setup settings configuration for the plugin with the UI - Continue writing and updating technical documentation. - Write test cases for sync functionality - Create a detailed user guide, README.md or blog as per requirements. |
| August 9 - August 15 | - Work on extra features. — Bulk Metadata Verification. — Contribution Mode: Add Books to BookBrainz. - Write tests for the new features - Update feature-specific documentation for extra features. |
| August 16 - August 22 | - Conduct full plugin testing (manual + automated). - Final adjustments needed to complete development. - Packaging & distribution: - Compressed ZIP file setup - MobileRead Forum submission. - Update final user documentation and README. - Prepare short demo video or screenshots (optional). |
Final Evaluation - Final Week
| Week | Technical Details |
|---|---|
| August 23 - September 1 | - Any remaining critical task - Prepare final presentation and GSoC submission. - Final evaluation. - Future guidance & discussion. - Prepare & submit final GSoC evaluation. |
Why me?
Over the past few weeks, I have spent a significant amount of time inspecting the BookBrainz codebase and working on resolving issues. I took a deep dive into the Calibre plugin’s API documentation and plugin development documentation. I also explored the codebase of an old BookBrainz plugin, namely CaliBBre.
I have been actively contributing to BookBrainz since joining the community and have gained a solid understanding of both the frontend and backend codebases. My contributions include multiple UI improvements, bug fixes, and code refactoring. Some of my key PRs are:
- Converted Promises to async/await in component pages
- Implemented a new footer design
- Displayed the full BookBrainz logo on the Home Page
- Refactored Promises syntax to async/await in form components
More details can be found in my PRs.
In conclusion, this project aligns well with my skill set and interests, and I am extremely excited to join GSoC 2025 while contributing to MetaBrainz as this opportunity adds great value to my portfolio. I assure you that I am a quick, self-motivated learner. While I am a student and a beginner in open source, not an expert, I am eager to embark on this exciting journey with the MetaBrainz community.
Community affinities
What type of music do you listen to? (please list a series of MBIDs as examples)
I mainly listen to Haryanivi, Bollywood and Punjabi music. Some of my favourite songs (recording MBIDs) are :
Same Beef - acc70490-89ff-43d3-8a43-1056f915e3e3
Ok Report - 36f9026f-a9d5-473a-8da0-a4a370978301
White Brown Black - 52293877-3768-4708-bafe-ff6da8fe8609
So High - 5993c11e-df08-487b-95c3-2ea3c8321840
Tum Hi Ho - 3e5bc764-dfa4-454d-a2a9-0ee84ae35db2
Tere Mitti - defbc3b7-4a8d-43e7-a016-a3aa472f3868
Billionaire - 8b6cec9e-bae7-4d3e-a421-784df1a72a6b
My favourite artists are (artist MBIDs):
Arijit Singh - ed3f4831-e3e0-4dc0-9381-f5649e9df221
Sidhu Moose Wala - 119a6864-622b-4e6c-8aab-a422080530c6
Yo Yo Honey Singh - 0dc9c4bc-8bcc-42f1-9033-bec41160377f
Karan Aujila - 4a779683-5404-4b90-a0d7-242495158265
What type of books do you read? (Please list a series of BBIDs)
Books that I read are -
Rich dad poor dad – 3a178573-cec4-4987-8c4e-683d90f8c20f
Think and Grow Rich - 83fd6313-bc4b-4d79-84b2-74890b4eb83c
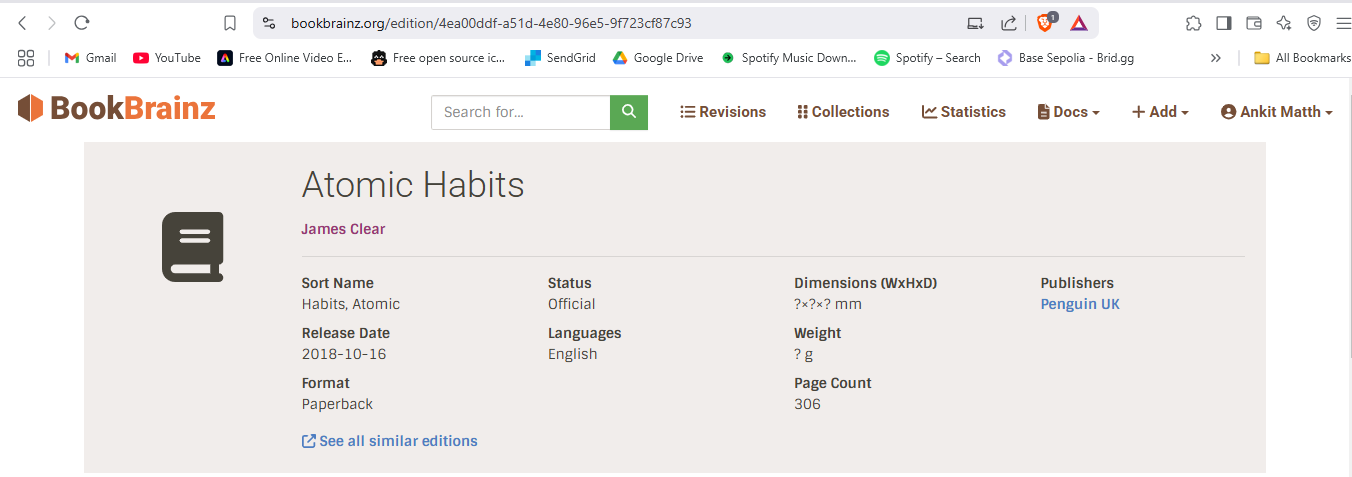
Atomic Habits - 4ea00ddf-a51d-4e80-96e5-9f723cf87c93
Gitanjali - 6103f0e1-5cc1-4d79-8d89-02ba91668215
Bhagavat Gita - 6cdb82a8-1e4e-4ae8-9fb8-039f77a8cba2
What aspects of MusicBrainz/ListenBrainz/BookBrainz/Picard interest you the most?
I am genuinely impressed by MusicBrainz for its vast database, as it includes almost every song I searched for, even niche tracks. I was particularly surprised to find Haryanvi and other local songs despite their relatively small audience. I also like ListenBrainz, especially BrainzPlayer, as it is very convenient. The way it efficiently tracks my listening habits and allows easy export for analysis is something I appreciate. I was also surprised by the BookBrainz database, as it contains detailed information on book editions, including authors, ISBN identifiers, publishers, and more for most books.
Have you ever used MusicBrainz Picard to tag your files or used any of our projects in the past?
No, I haven’t tried MusicBrainz Picard yet, but I plan to try it soon. As mentioned above, I have used ListenBrainz for listening to and analyzing my music preferences. I have also contributed to BookBrainz by adding editions, works, and other details to explore the workflow and understand the entire process. Additionally, I sometimes explore information about a book, such as its author, publisher, and other details, by searching for it on BookBrainz.
Programming precedents
When did you first start programming?
I started programming in my first year of B.Tech, around early 2022, when C language was introduced in our curriculum. Over time, it became a hobby, and I gradually became more serious about coding.
Have you contributed to other open source projects? If so, which projects and can we see some of your code?
No, I haven’t participated in any major open-source programs before this. However, I made small contributions to DocsGPT during Hacktoberfest 2023. My PRs can be found here.
Currently, I have primarily contributed to BookBrainz in the MetaBrainz ecosystem. You can find all my PRs here.
What sorts of programming projects have you done on your own time?
I primarily focus on project-based learning and aim to become a Full Stack Developer. I chose the MERN stack as my main tech stack, but I also explored testing, deployment, and code formatting tools. Below are some of the projects I have built:
-
Multiplayer Tic-Tac-Toe | React.js, Socket io, Cypress
-
Maze Escape | p5.js, HTML, CSS, JavaScript, DSA
-
My Portfolio | MongoDB, Express, React.js, Node.js
-
Personal Doctor | Handlebars, CSS, JS, Node.js, Express, MongoDB
-
Scientific Calculator | HTML, CSS, JavaScript
-
Advanced To-Do List | HTML, CSS, JavaScript
Note: All the projects are properly deployed. The live links and source codes of these can be found in the pinned repositories on my GitHub account. Feel free to check them out!
Practical requirements
What computer(s) do you have available for working on your SoC project?
I use Windows as my primary operating system and have set up my development environment using WSL (Windows Subsystem for Linux). My HP Pavilion laptop has the following specifications:
CPU: 11th Gen Intel® Core™ i3-1115G4 @ 3.00GHz
RAM: 8GB
Storage: 512GB SSD
System Type: 64-bit OS, x64-based processor
Operating System: Windows 10 Pro
GPU: Intel® UHD Graphics with HD display
How much time do you have available per week, and how would you plan to use it?
I am mostly free during my summer break and can dedicate around 30-40 hours, or even more, per week to the GSoC project. This summer, I am fully committed to working on this project, as I have no other obligations—no job or university coursework. With ample free time, I am entirely focused on contributing to GSoC and making a meaningful impact.