Following on from the Rust version, pre-proposal and a long conversation on matrix this is an updated version. The biggest difference is the language choice, and there’s also an addition of a persistent store for messages in the database.
There’s a lot of elaboration in the footnotes. In discourse they show up as little elipsis icons.
Project summary
Proposed mentor: julian45 (possibly zas, lucifer?)
Languages/skills: Python/Matrix/HTML/Docker/Prometheus
Estimated project length: 350 hours
Difficulty: Medium
Expected Outcomes:
- Matrix-native chat archiver, producing a portable, HTML-based output
- Support Matrix’s reply, redaction and reaction features
- Support Matrix’s media features
Additional Objectives: - Built-in full-text search functionality over past messages
- Full support for Matrix’s threaded conversations (initial support will fall back as replies, with a ‘thread’ marker)
Contact information
- Matrix: @jade:ellis.link, or as fallback @jadedblueeyes:matrix.org
- JadedBlueEyes on IRC
- JadedBlueEyes (Jade Ellis) · GitHub
- https://jade.ellis.link
- Timezone: Europe/London (GMT)
Personal Introduction
Hi there! Those of you who were here last year might know me already, but for those who don’t, I’m Jade.
I’m a second-year Computer Science student at the University of Kent in England, and I had the pleasure of participating in GSoC with MetaBrainz last year (see also proposal, release thread).
I made my first contributions to the MusicBrainz database in 2020, after using Picard to maintain my music library. I’m honestly not sure when I first started using Picard, but it’s been a staple!
Proposed project
Last summer, MeB migrated from IRC to Matrix for communication. We have BrainzBot (a fork of BotBotMe), an IRC-based bot that reads all messages and logs them to a Postgres database. These logs are displayed on chatlogs metabrainz org. Although we have a functioning IRC-Matrix bridge so that BrainzBot’s chat logging still works, BrainzBot is unmaintained and uses dependencies with known vulnerabilities. Due to this and our focus on Matrix as our communications platform of choice, we would quite prefer to move BrainzBot’s functions to a more modern bot.
This project proposes two main parts to replace BrainzBot fully. The first part is an archiver service, operating as a Matrix ‘bot’ account that records all messages from a room as human-readable HTML. The second part is an instance of MauBot, configured with a combination of already-existing plugins and some new plugins to replace the macros and other interactive functions of BrainzBot.
Matrix Archiver
This would be a long-running service written in Python [1], utilising mautrix/python to read the target rooms via a bot account. [2] [3]
The service would ingest both historical messages and new messages as they come in, and write the message content to a database, a search index and a HTML representation of the room on disk. This HTML representation would remain readable using a web browser, regardless of external factors that might otherwise make the message history unreadable or otherwise hard to read. [4]
Additionally, being plain HTML, it would be easily indexable by search engines.
On first encounter with a room, it would retrieve the entire message history, filling out the database and generating the HTML as it goes. It would also be able to regenerate the HTML and search index from the database.
To improve machine readability and for redundancy’s sake, the original event content of each message will be embedded in the HTML as JSON.
These HTML pages would be served over HTTP by the service for simplicity of configuration, although they could be served using a standard web server if the situation calls for it. [5]
Message history will be divided by room (so different timelines don’t interfere) and then, initially, by date[6]. It will be possible to navigate to the previous and next pages chronologically, as well as jump to a specific date via a sidebar.
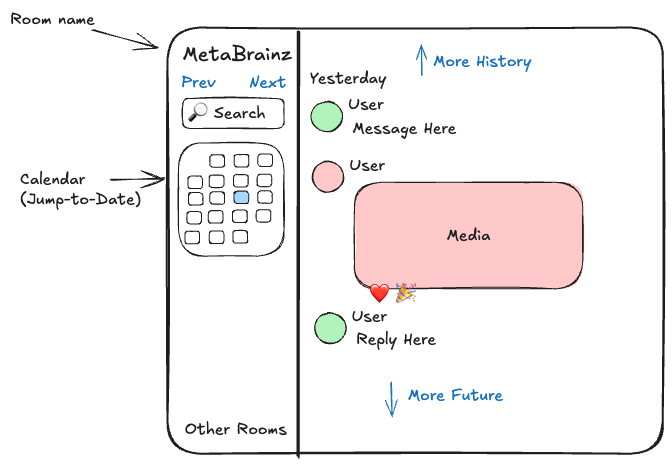
A quick mockup of the layout of the UI
HTML generation would be handled via jinja templates. Each room would have its own folder, and the timeline would be split in to chunks (initially by day, but it’s worth experimenting if there’s a way to get better results with more evenly sized pages, and keeping entire conversations on one page.)
Data and state
The project has a number of different points where data and state is stored, each with slightly different needs.
- State needed for using the Matrix APIs. This is handled by
mautrix/pythonwith a pluggable backend. This would be deployed with the postgres backend. - Maintaining a store of Matrix timeline events (message contents). This is an ordered stream of event IDs and JSON contents, [7] and would primarily sit between the Matrix SDK and Search/HTML generation. This would go in postgres.
- Maintaining a mapping between event IDs and HTML pages. This is essential for knowing which page to regenerate when handling an event like an edit or reaction, that effectively updates a previous message. This can go in postgres.
- Reference counting files in the media repo, to allow cleanup of unused media. This can go in postgres.
- The media itself. This is best written to disk as flat files, both because media files are large blobs and because files on disk can be served by a standard web server (precluding a S3 bucket)
- The HTML files. Again, this is best written to disk, as this allows serving using a standard web server.
- The search index. This would be an embedded Tantivy instance, with the index on disk. [8]
With all of that, we end up with data in two places:
- Postgres, holding Matrix state, the message history and state for regenerating HTML files and tracking media
- Files on disk, containing the HTML, media and search index
Details for specific functionalities
Full-text search support will be provided via a JSON API, protected with rate limiting. If the search endpoint is unreachable or JS is disabled, the search box will be hidden. [9]
On the client side, there would be some simple JS to provide interactive search via a dropdown box, and a full screen search page.
Since the Authenticated Media change, Matrix media cannot be hotlinked. To support Matrix’s media features, the service will download and maintain a repository of files corresponding to matrix’s mxc identifiers. It will not provide an equivalent to Matrix’s thumbnail API, and will only serve the original file uploaded to Matrix.
The service will maintain a database mapping the media to the messages that reference it. If all messages referencing the media are redacted or otherwise deleted, the media will be automatically deleted. Additional necessary metadata, like the MIME type, will be stored there too. [10]
When serving the media to clients, to avoid XSS attacks the media will be served using the headers specified in the matrix spec. [11]
Matrix has a number of features that effectively update past messages. The key ones are edits, redactions and reactions. When the service receives one of these events, it will use the database to determine the page that the affected message is on and then ‘rerender’ that page to show the new state.
Threads are one of the more complex features of Matrix to implement. From a user perspective, they effectively create a room within a room, starting from any message. In terms of the underlying protocol, threaded messages are effectively specially marked replies - but otherwise are normal events.
Because of the additional UI complexity of displaying threads as intended, they will initially just be rendered as normal replies with an indicator to mark them as threaded. This is a common approach used by many clients.[12]
When these are properly implemented, threaded replies will be hidden in the main timeline. The start of the thread will be marked with a link to a page that contains the full thread. Additionally, every page with a threaded message will link to that thread in the sidebar.
The list of rooms that are logged by the bot will be controlled by a configurable list of admin users. When invited into a room by one of these admins, it will join the room and start logging messages. If an admin is not a room admin/moderator, the bot will leave the room and stop logging. When kicked from the room by a room admin/moderator, it will stop logging that room.
A list of all archived rooms will be maintained as a sort of homepage to allow easy discovery. [13]
Tooling
The service will be deployed via a Docker image.
Python dependancies will be managed via UV.
The project will be automatically linted via Ruff in CI.
Bundling/minification of JS and CSS would be handled via a minimal Vite setup.
For operations, Sentry and Prometheus statistics will be integrated into the service.
MauBot
A MauBot instance would be set up on MeB servers to replace the remaining functionality of BrainzBot. [14]
MauBot is a Python-based Matrix bot centered around a plugin framework. At a high level, it is relatively similar to the framework BrainzBot is based on, aside from the obvious differences.
To replicate the functionality used by the community, the following plugins would be set up
- GitHub - maubot/github: A GitHub client and webhook receiver for maubot · GitHub, for GitHub notifications
- A port of bangmotivate_redux.py
- A port of jira.py, for previewing ticket IDs
Additional plugins, like the RSS plugin, could also be set up.
Timeline
(TODO)
Community affinities
What type of music do you listen to?
My picks from last year still get regularly listened to, but here are some new favourites:
- Release group “Off With Her Head” by BANKS - MusicBrainz Banks’ latest album, you can see me in the top listeners on ListenBrainz for this one!
Favourite track: Guillotine - Release group “Negative Spaces” by Poppy - MusicBrainz
Favourite tracks: the cost of giving up, surviving on defiance - Release group “What Happened to the Heart?” by AURORA - MusicBrainz
Favourite track: My Body Is Not Mine
What aspects of MusicBrainz/ListenBrainz/BookBrainz/Picard interest
you the most?
I think my answer from last year still stands. It’s been gratifying watching everything that’s been happening over the last year. I noticed @holycow23 's graph in ListenBrainz recently, and there have been many, many other delightful changes across MeB!
Programming precedents
My GitHub might be worth an explore. Here are some relevant shouts from the last year:
- GitHub - JadedBlueEyes/matrix-bots · GitHub - A simple Matrix bot using the matrix Rust SDK that runs a sed-like regex replacement on a message.
- Some contributions to GitHub - x86pup/conduwuit: a very cool, featureful fork of conduit (rust matrix homeserver) · GitHub - a Matrix homeserver
- GitHub - metabrainz/mb-mail-service: Service for MusicBrainz to send emails · GitHub - Last year’s GSoC project, of course!
Most of my Web-related code is private, although you can visit my personal website - It is currently built on SvelteKit and MarkDown files, and styled with plain text.
I also have a variety of coursework from the past couple of years that’s private. Most of it is pretty uninteresting, although there are a couple of fascinating ones - most recently breaking a variety of simple cyphers (from Caesar to simple substitution) using cryptanalysis techniques.
Practical requirements
What computer(s) do you have available for working on your SoC
project?
- Linux desktop (Fedora)
- Macbook Pro
- Windows 11 Pro laptop
- Android Phone
- Dedicated linux server with a matrix server and maubot instance set up
How much time do you have available per week, and how would you plan
to use it?
From now until the start of May, it’s the Easter break for me. Term starts again at the start of May (and my birthday is then, too!) and from the 6th May to the 23rd May I have exams. After that, the Summer break starts and I’ll have no other significant time commitments.
As a rough ballpark, I’ll be able to dedicate about 20 hours a week to GSoC related work until May. From then, I’ll be heads-down with exams until they finish on the 23rd. I might still be able to take some time, but not much - I have 8 different 2 hour exams!
Once that’s all done, from the 26th I’ll be able to work full time on the project, barring a few days for moving, etc. As with last year, that’s about 30 hours per week.
See the chat conversation, Rust proposal and pre-proposal for more on this choice. TLDR is that MeB has much more Python knowledge, and although Python’s matrix ecosystem isn’t quite as good as Rust or Go, it’s sufficient for the task at hand. We also get to use the same ecosystem as maubot! ↩︎
A matrix SDK provides an interface over the matrix protocol that handles the details of the protocol and allows connecting to any standard-compliant server. Alternatives like reading directly from Synapse’s database were considered and discarded due to relying on unstable implementation details and incompatibility with other homeservers. ↩︎
There are multiple Matrix SDKs for python.
matrix-org/matrix-python-sdkis abandoned, and suggestsmatrix-nioinsteadmatrix-nio/matrix-nioseems to have some activity. However, talking to community members, it has major unresolved issues and is quite complex internally, which slows maintenance. Quote “If you’re fine with building a hotel on a sinkhole, niobot serves what you desire.” They instead suggestmautrix/pythonmautrix/pythonhas some activity, and is used by maubot and two of mautrix/beeper’s bridges (so pretty large production use). beeper are moving away from python, so it’ll likely be mostly community support, but it has been battle tested.
For example, Matrix specification changes or the chatbrainz.org server going down or suffering data loss. ↩︎
For example, the unlikely event that the service becomes inoperable, or MeB moving off Matrix and closing the rooms. ↩︎
I’ll experiment with other algorithms for dividing pages to see what results in the best experience ↩︎
not necessarily ordered by timestamp, though! It’s primarily ordered by the time that your homeserver gets the event, with some stuff where events reference prior events, and your homeserver will fetch missing previous events from other servers. This does occasionally result in badly-behaving servers causing messages to pop up in the timeline that were sent months ago, but not actually federated.
A typical event JSON, from the event API endpoint: event.JSON · GitHub ↩︎
We could use pg for this, but Tantivy python bindings are available. Tantivy has many more search features built in, most importantly a query parser. It’s also embedded as a library, making it much simpler to operate than something like ElasticSearch, and very efficient.
Finally, as an added bonus, there is a soft-fork that compiles to WebAssembly called summa, allowing full-featured search in the browser. Getting that working with this service would be a fun project! ↩︎
As mentioned in a different footnote, searches could be done cleint side with Tantivy compiled to WASM. This could be a bit of a project, but would allow just serving the index as static files, with the client only grabbing what it needs with range requests. ↩︎
I’m not sure what the best way is to convey this data to a traditional webserver is, if it is serving them directly. As-is, my best guess is to add ‘guessed’ file extensions that it can use. Or maybe the server can just guess the mime type. ↩︎
If this isn’t enough, then disabling non-image media is an option, as is setting more restrictive headers. ↩︎
Off the top of my head: Element X and its forks, Cinny, Gomuks Web. ↩︎
This brought creating a sitemap for SEO to mind - using the database, this would be feasible as an additional goal. ↩︎
Hookshot, another matrix bot, could be used for Git and RSS feeds and has Element’s hosted public instances, but it doesn’t have the flexibility of MauBot - it has no plugin system AFAICT, so some functionality can’t be replicated. It would also be in JS, whereas maubot is in python and shares the same underlying SDK as the main chunk of the project ↩︎