Contact Information
• Nickname: ZehB
• Email: zehbrien@gmail.com
• Public Profiles:
GitHub: github profile
Introduction
Hi my name is Zeh Brien. I graduated from the University of Buea in Cameroon in 2023 with a Bachelor’s degree in Electrical Engineering. Since then, I’ve worked as a data scientist for two years, gaining experience in handling and organizing data. I’m also currently working towards a Master’s degree. I’m really interested in music and how data can be used to organize it, which is why I’m applying to contribute to MetaBrainz. I think my data science skills and my engineering background would be helpful to your team.
Proposed Project
Music Recommendations for ListenBrainz using Neo4j and PySpark
AIM
This project aims to improve music recommendations on ListenBrainz by using a graph-based system with Neo4j and PySpark. The goal is to give users more personalized and varied music suggestions by analyzing the relationships in the music data they upload. Advanced graph algorithms will help make these recommendations better. ListenBrainz currently provides valuable listening data. By augmenting this with graph-based analysis, we can discover deeper connections between users, artists, and music, leading to more accurate and engaging recommendations.
Proposed Solution
- Schema Design and Data Flow
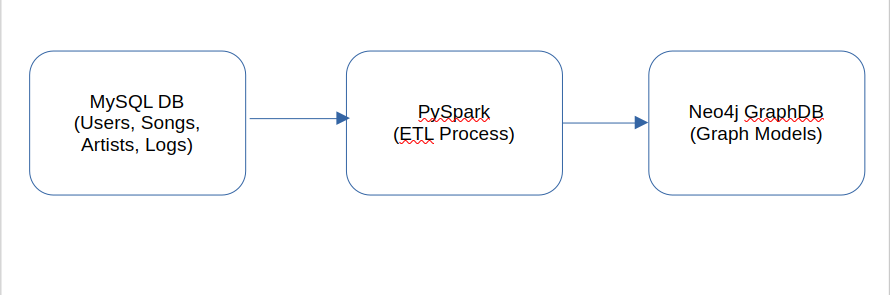
The system uses Neo4j as a graph database to store and analyze relationships between users, songs, artists, and genres. PySpark is used to efficiently process and transform large-scale data before loading it into Neo4j.
Graph Schema
The data in Neo4j is structured as follows:
- User (
Usernode): Represents users in the system. - Song (
Songnode): Represents songs in the system. - Artist (
Artistnode): Represents artists who perform songs. - Genre (
Genrenode): Represents different music genres.
Relationships in Neo4j
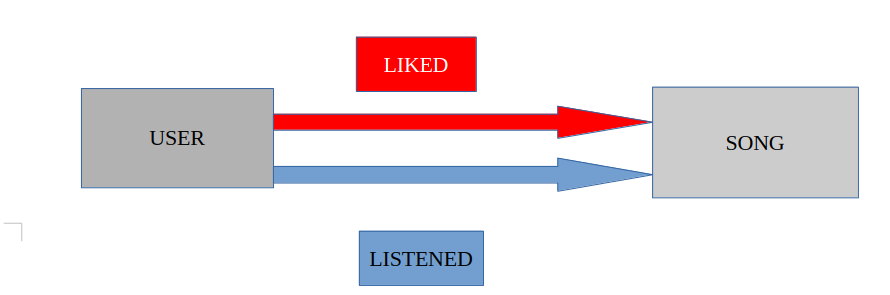
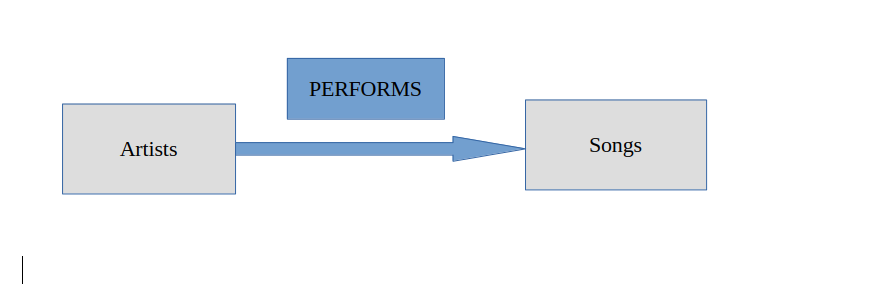
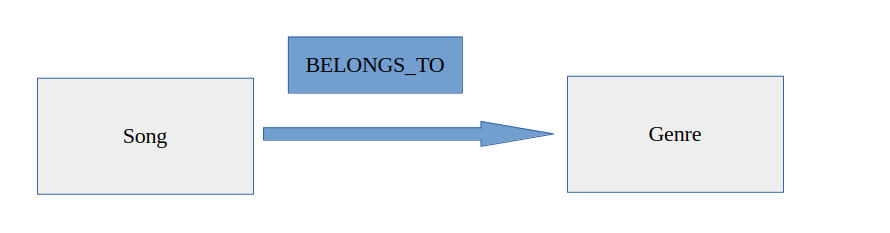
(:User)-[:LIKES]->(:Song): A user likes a song.(:User)-[:LISTENED]->(:Song): A user has listened to a song.(:Song)-[:BELONGS_TO]->(:Genre): A song belongs to a genre.(:Artist)-[:PERFORMS]->(:Song): An artist performs a song.
Integration of PySpark and Neo4j
The provided code below:
- Extracts data from MySQL using PySpark.
- Transforms the data into a format suitable for graph storage.
- Loads data into Neo4j, ensuring proper relationships between entities.
** Implementation Steps**
- Data Extraction
- PySpark reads tables like
users,songs,artists,genres, andlisten_logsfrom MySQL.
- Graph Schema Creation
- Unique constraints are set for
User,Song,Artist, andGenrenodes in Neo4j.
- Data Loading into Neo4j
- Data is transformed into Pandas format then to a dictionary and loaded into neo4j. For now the process occurs in a single batch as shown in the code below, but can be further improved upon. The pieces of code posted in this proposal is a demo of how the project works and not a reflection of how listenbrainz database tables are in reality.
import os
import pandas as pd
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
from src.db_connection.neo4jDBConnection import Neo4jConnection
class Ingestion:
def __init__(self):
self.spark = SparkSession.builder.appName("ListenBrainzIngestion").getOrCreate()
self.neo4j_connection = Neo4jConnection()
self.mysql_url = f"jdbc:mysql://localhost:3306/{os.getenv('DB_NAME')}"
self.mysql_properties = {
"user": os.getenv("DB_USER"),
"password": os.getenv("DB_PASSWORD"),
"driver": "com.mysql.cj.jdbc.Driver"
}
def read_mysql_table(self, table_name):
"""Reads a table from MySQL using PySpark"""
return self.spark.read.jdbc(url=self.mysql_url, table=table_name, properties=self.mysql_properties)
def fetch_users(self):
return self.read_mysql_table("users").select("id", "name", "country")
def fetch_artists(self):
return self.read_mysql_table("artists").select("id", "name", "country")
def fetch_songs(self):
return self.read_mysql_table("songs").select("id", "name", "country", "genre_id", "created_at")
def fetch_genres(self):
return self.read_mysql_table("genre").select("id", "name")
def fetch_song_artists(self):
return self.read_mysql_table("song_artists").select("song_id", "artist_id")
def fetch_song_likes(self):
return self.read_mysql_table("song_likes").select("user_id", "song_id")
def fetch_listen_logs(self):
return self.read_mysql_table("listened_logs").select("user_id", "song_id", "count")
def create_neo4j_schema(self):
"""Create constraints in Neo4j"""
schema_queries = [
"CREATE CONSTRAINT ON (u:User) ASSERT u.id IS UNIQUE",
"CREATE CONSTRAINT ON (a:Artist) ASSERT a.id IS UNIQUE",
"CREATE CONSTRAINT ON (s:Song) ASSERT s.id IS UNIQUE",
"CREATE CONSTRAINT ON (g:Genre) ASSERT g.id IS UNIQUE"
]
for query in schema_queries:
try:
self.neo4j_connection.query(query)
except Exception as e:
print(f"Error creating schema: {e}")
def load_data_to_neo4j(self, df, query):
"""Helper function to load data into Neo4j"""
data = df.toPandas().to_dict(orient="records")
self.neo4j_connection.query(query, {"data": data})
def load_users_to_neo4j(self):
df = self.fetch_users()
query = """
UNWIND $data AS user
MERGE (u:User {id: user.id})
SET u.name = user.name, u.country = user.country
"""
self.load_data_to_neo4j(df, query)
def load_artists_to_neo4j(self):
df = self.fetch_artists()
query = """
UNWIND $data AS artist
MERGE (a:Artist {id: artist.id})
SET a.name = artist.name, a.country = artist.country
"""
self.load_data_to_neo4j(df, query)
def load_genres_to_neo4j(self):
df = self.fetch_genres()
query = """
UNWIND $data AS genre
MERGE (g:Genre {id: genre.id})
SET g.name = genre.name
"""
self.load_data_to_neo4j(df, query)
def load_songs_to_neo4j(self):
df = self.fetch_songs()
query = """
UNWIND $data AS song
MERGE (s:Song {id: song.id})
SET s.name = song.name, s.country = song.country, s.created_at = song.created_at
WITH s, song
MATCH (g:Genre {id: song.genre_id})
MERGE (s)-[:BELONGS_TO]->(g)
"""
self.load_data_to_neo4j(df, query)
def load_song_artists_to_neo4j(self):
df = self.fetch_song_artists()
query = """
UNWIND $data AS sa
MATCH (a:Artist {id: sa.artist_id})
MATCH (s:Song {id: sa.song_id})
MERGE (a)-[:PERFORMS]->(s)
"""
self.load_data_to_neo4j(df, query)
def load_song_likes_to_neo4j(self):
df = self.fetch_song_likes()
query = """
UNWIND $data AS sl
MATCH (u:User {id: sl.user_id})
MATCH (s:Song {id: sl.song_id})
MERGE (u)-[:LIKES]->(s)
"""
self.load_data_to_neo4j(df, query)
def load_listen_logs_to_neo4j(self):
df = self.fetch_listen_logs()
query = """
UNWIND $data AS ll
MATCH (u:User {id: ll.user_id})
MATCH (s:Song {id: ll.song_id})
MERGE (u)-[r:LISTENED]->(s)
SET r.count = ll.count
"""
self.load_data_to_neo4j(df, query)
def load_all_to_neo4j(self):
try:
self.create_neo4j_schema()
self.load_genres_to_neo4j()
self.load_artists_to_neo4j()
self.load_users_to_neo4j()
self.load_songs_to_neo4j()
self.load_song_artists_to_neo4j()
self.load_song_likes_to_neo4j()
self.load_listen_logs_to_neo4j()
return {"message": "Database setup successfully"}
except Exception as e:
return {"message": f"Error: {str(e)}"}
- Recommendations
- Recommendations based on similar users:
This method recommends songs based on what similar users have listened to or liked. It finds users who have interacted with the same songs as the given user, then checks what other songs those users have listened to or liked. Songs that the given user has not interacted with are recommended.
def recommend_based_on_user_activity(self, user_id, limit=20, page=1):
count_query = """
MATCH (u:User {id: $user_id})-[:LISTENED|LIKES]->()<-[:LISTENED|LIKES]-(other:User)
MATCH (other)-[:LISTENED|LIKES]->(rec:Song)
WHERE NOT EXISTS((u)-[:LISTENED|LIKES]->(rec))
RETURN count(DISTINCT rec) AS total_count
"""
count_result = self.neo4j_connection.query(count_query, {"user_id": user_id})
total_items = count_result[0]['total_count'] if count_result else 0
total_pages = ceil(total_items / limit) if total_items > 0 else 1
page = max(1, min(page, total_pages))
offset = (page - 1) * limit
query = """
MATCH (u:User {id: $user_id})-[:LISTENED|LIKES]->()<-[:LISTENED|LIKES]-(other:User)
MATCH (other)-[:LISTENED|LIKES]->(rec:Song)
WHERE NOT EXISTS((u)-[:LISTENED|LIKES]->(rec))
WITH rec, count(other) AS common_activities
RETURN rec.id AS song_id,
rec.name AS song_name,
common_activities AS activity_score,
[(a)-[:PERFORMS]->(rec) | a.name][..3] AS artists,
[(other)-[:LISTENED|LIKES]->(rec) | other.id][..5] AS similar_users
ORDER BY activity_score DESC
SKIP $offset
LIMIT $limit
"""
params = {
"user_id": user_id,
"offset": offset,
"limit": limit
}
recommendations = self.neo4j_connection.query(query, params)
return {
"recommendations": recommendations,
"total_items": total_items,
"total_pages": total_pages,
"current_page": page,
"per_page": limit
}
- Recommendations based on Artiste:
This method suggests songs based on the artists a user has listened to or liked. It checks which artists have performed the user’s favorite songs and then finds other songs by those artists. If the user has not heard these songs, they are recommended.
def recommend_based_on_artists(self, user_id, limit=20, page=1):
count_query = """
MATCH (u:User {id: $user_id})-[:LISTENED|LIKES]->(s:Song)<-[:PERFORMS]-(a:Artist)
MATCH (a)-[:PERFORMS]->(rec:Song)
WHERE NOT EXISTS((u)-[:LISTENED|LIKES]->(rec))
RETURN count(DISTINCT rec) AS total_count
"""
count_result = self.neo4j_connection.query(count_query, {"user_id": user_id})
total_items = count_result[0]['total_count'] if count_result else 0
total_pages = ceil(total_items / limit) if total_items > 0 else 1
page = max(1, min(page, total_pages))
offset = (page - 1) * limit
query = """
MATCH (u:User {id: $user_id})-[:LISTENED|LIKES]->(s:Song)<-[:PERFORMS]-(a:Artist)
MATCH (a)-[:PERFORMS]->(rec:Song)
WHERE NOT EXISTS((u)-[:LISTENED|LIKES]->(rec))
WITH rec, a, count(*) AS artist_affinity
RETURN rec.id AS song_id,
rec.name AS song_name,
a.name AS artist_name,
artist_affinity,
[(a2)-[:PERFORMS]->(rec) WHERE a2 <> a | a2.name][..2] AS other_artists
ORDER BY artist_affinity DESC
SKIP $offset
LIMIT $limit
"""
params = {
"user_id": user_id,
"offset": offset,
"limit": limit
}
recommendations = self.neo4j_connection.query(query, params)
return {
"recommendations": recommendations,
"total_items": total_items,
"total_pages": total_pages,
"current_page": page,
"per_page": limit
}
- Recommendations based on Genre:
This method recommends songs based on the genres the user listens to. It identifies the genres of songs the user has played and then suggests other songs from the same genres that the user has not heard yet.
def recommend_based_on_genre(self, user_id, limit=20, page=1):
count_query = """
MATCH (u:User {id: $user_id})-[:LISTENED|LIKES]->(s:Song)-[:BELONGS_TO]->(g:Genre)
MATCH (g)<-[:BELONGS_TO]-(rec:Song)
WHERE NOT EXISTS((u)-[:LISTENED|LIKES]->(rec))
RETURN count(DISTINCT rec) AS total_count
"""
count_result = self.neo4j_connection.query(count_query, {"user_id": user_id})
total_items = count_result[0]['total_count'] if count_result else 0
total_pages = ceil(total_items / limit) if total_items > 0 else 1
# Adjust page if out of range
page = max(1, min(page, total_pages))
offset = (page - 1) * limit
# Get paginated recommendations with genre affinity
query = """
MATCH (u:User {id: $user_id})-[:LISTENED|LIKES]->(s:Song)-[:BELONGS_TO]->(g:Genre)
MATCH (g)<-[:BELONGS_TO]-(rec:Song)
WHERE NOT EXISTS((u)-[:LISTENED|LIKES]->(rec))
WITH rec, g, count(*) AS genre_affinity
RETURN rec.id AS song_id,
rec.name AS song_name,
g.name AS genre,
genre_affinity,
[(a)-[:PERFORMS]->(rec) | a.name][..3] AS artists
ORDER BY genre_affinity DESC
SKIP $offset
LIMIT $limit
"""
params = {
"user_id": user_id,
"offset": offset,
"limit": limit
}
recommendations = self.neo4j_connection.query(query, params)
return {
"recommendations": recommendations,
"total_items": total_items,
"total_pages": total_pages,
"current_page": page,
"per_page": limit
}
- Recommend New Releases
This method recommends songs that have been recently added to the system and that the user has not listened to yet. It first checks the total number of such songs and calculates the number of pages needed to display them in a paginated format.
It then retrieves songs ordered by their release date, making sure they have not been listened to or liked by the user. The method also fetches extra details like the song’s genre, the top three performing artists, and the release date.
def get_recently_added_songs(self, user_id, limit=20, page=1):
count_query = """
MATCH (s:Song)
WHERE NOT EXISTS((:User {id: $user_id})-[:LISTENED|LIKES]->(s))
RETURN count(s) AS total_count
"""
count_result = self.neo4j_connection.query(count_query, {"user_id": user_id})
total_items = count_result[0]['total_count'] if count_result else 0
total_pages = ceil(total_items / limit) if total_items > 0 else 1
# Adjust page if out of range
page = max(1, min(page, total_pages))
offset = (page - 1) * limit
# Get paginated recent songs with additional metadata
query = """
MATCH (s:Song)
WHERE NOT EXISTS((:User {id: $user_id})-[:LISTENED|LIKES]->(s))
OPTIONAL MATCH (s)-[:BELONGS_TO]->(g:Genre)
OPTIONAL MATCH (a)-[:PERFORMS]->(s)
WITH s, g, collect(DISTINCT a.name)[..3] AS artists
RETURN s.id AS song_id,
s.name AS song_name,
artists,
g.name AS genre,
s.created_at AS release_date,
date().epochSeconds - datetime(s.created_at).epochSeconds <= 2592000 AS is_new_release
ORDER BY s.created_at DESC
SKIP $offset
LIMIT $limit
"""
params = {
"user_id": user_id,
"offset": offset,
"limit": limit
}
recommendations = self.neo4j_connection.query(query, params)
return {
"recommendations": recommendations,
"total_items": total_items,
"total_pages": total_pages,
"current_page": page,
"per_page": limit
}
API MOCKUP
This API endpoint provides song recommendations based on different criteria for a given user. It listens for POST requests at "/recommendations" and expects a JSON payload containing a user_id, along with optional parameters for limit (number of results per category) and page (pagination control).
How It Works
When a request is received, the API first checks if user_id is present. If it’s missing, it returns an error response. Otherwise, it proceeds to generate recommendations using four different methods from the recommendationService:
- New Songs – Finds recently added songs that the user has not listened to yet.
- Genre-Based Recommendations – Suggests songs based on the genres the user listens to the most.
- Artist-Based Recommendations – Recommends songs from artists the user already likes.
- User Activity-Based Recommendations – Suggests songs that similar users have listened to but the given user has not.
Each method returns a structured response with recommendations, total available songs, total pages, and current page details. The API then combines all these recommendations into a single JSON response and sends it back to the client.
If an error occurs at any stage, the API catches it and returns a 500 Internal Server Error with the error message. Below is the sample code.
@api.route("/recommendations", methods=["POST"])
def recommend():
data = request.get_json()
user_id = data.get("user_id")
limit = data.get("limit", 20)
page = data.get("page", 1)
if not data.get("user_id"):
return make_response(jsonify({"error": "user_id required"}), 400)
try:
new_songs = recommendationService.get_recently_added_songs(user_id, limit, page)
genre_based_recommendations = recommendationService.recommend_based_on_genre(user_id, limit, page)
artist_based_recommendations = recommendationService.recommend_based_on_artists(user_id, limit, page)
user_activity_recommendations = recommendationService.recommend_based_on_user_activity(user_id, limit, page)
response = {
"new_songs": new_songs,
"genre_based_recommendations": genre_based_recommendations,
"artist_based_recommendations": artist_based_recommendations,
"user_activity_recommendations": user_activity_recommendations
}
return make_response(jsonify(response), 200)
except Exception as e:
return make_response(jsonify({"error": str(e)}), 500)
Timeline
Week 1-2: Environment Setup & Data Exploration
- Set up the development environment, including Neo4j, PySpark, and ListenBrainz API access.
- Familiarize with ListenBrainz dataset and Neo4j graph database concepts.
- Define an initial schema for graph representation in Neo4j.
- Perform exploratory data analysis to understand user interactions and song metadata.
Week 3-4: Data Ingestion & Graph Construction
- Implement data ingestion pipelines using PySpark and Neo4j Spark Connector.
- Transform and load ListenBrainz data into Neo4j as a graph structure.
- Develop Cypher queries to explore the graph and verify data integrity.
- Optimize data ingestion to handle large-scale streaming data efficiently.
Week 5-6: Graph-Based Recommendation Algorithms
- Implement Personalized PageRank to identify influential songs and users.
- Develop community detection algorithms to group users based on listening patterns.
- Evaluate the effectiveness of graph-based recommendations using initial metrics.
Week 7-8: Hybrid Recommendations Development
- Begin developing a hybrid recommendation approach by using graph-based methods.
Week 9-10: API Development & Integration
- Develop a REST API for recommendation delivery.
- Implement endpoints for different recommendation types.
- Integrate API with ListenBrainz for real-time recommendation retrieval.
- Ensure API scalability and optimize response times.
Week 11: Testing & Second Evaluation
- Conduct a second evaluation of all recommendation methods.
- Perform testing for accuracy, performance, and scalability.
- Optimize recommendation models and API response times.
Week 12: Documentation, Cleanup & Final Evaluation
- Document the implementation details, API usage, and evaluation results.
- Refactor and clean up the codebase for maintainability.
- Conduct a final evaluation of recommendation effectiveness.
- Prepare for deployment and potential future improvements.
Other Information
Tell us about the computer(s) you have available for working on your SoC project!
I own a Dell latitude 7490 laptop with an i5 8th gen processor and 16 gigs of ram.
When did I start programming
I first started writing code in high-school in our computer science course. My first programming language was C, before I moved on to Python and Java.
Type of music i listen to
I love listening to hiphop/rap and reggae, below are some of my favorite songs MBIDs
- b1a8bf21-6d81-42c5-a73a-f193f5358503
- c296e10c-110a-4103-9e77-47bfebb7fb2e
What aspects of the project you’re applying for (e.g., MusicBrainz, AcousticBrainz, etc.) interest you the most?
The aspect of the project that interest me the most are ListenBrainz. ListenBrainz provides a rich dataset of user listening history, which can be leveraged to build personalized music recommendations. I am particularly excited about using graph-based techniques in Neo4j to model relationships between users, songs, artists, and genres, allowing for more insightful and explainable recommendations.
Have you contributed to other Open Source projects? If so, which projects, and can we see some of your code?
I haven’t contributed to other open-source projects yet, but I have worked on several projects that showcase my skills in data engineering, recommendation systems, and machine learning. You can check my GitHub profile here to see my projects.
What sorts of programming projects have you done on your own time?
I have built a product search engine using Flask and Elasticsearch and a music recommendation engine with Flask and Neo4j. I also have experience with Django and Spring Boot as a backend Engineer.
How much time do you have available, and how would you plan to use it?
I have 30 hours per week available for this project. I plan to use this time for research, development, testing, and documentation. My schedule will be structured to ensure steady progress, with regular evaluations and adjustments as needed.