GSOC 2024: Set up BookBrainz for Internationalization
Pdf version - GSOC 2024: Set up BookBrainz for Internationalization
ReadMe version -https://github.com/aabbi15/bookbrainz-i18n-demo?tab=readme-ov-file
Proposed Mentors: monkey
Languages/skills: Javascript/Typescript
Estimated Project Length: 175 hours
Project Size: Medium
Expected outcomes: Full translation project and workflow set up, with as much as possible of the website text captured for translation
Contact Information
Name : Abhishek
IRC Nickname : aabbi15
TimeZone: UTC +05:30
Email : abhishekabbi.work@gmail.com
GitHub : aabbi15 (Abhishek Abbi) · GitHub
Twitter : https://twitter.com/aabbi_work
LinkedIn: https://www.linkedin.com/in/abhishek-abbi
Project Overview
BookBrainz is currently available only in the English language which limits it from catering to the global audience.
Therefore, we want to internationalize the website, enabling it to support multiple languages and thereby, extending its user base.
The MusicBrainz team has already worked on internationalization and moved to use a Weblate server for the same. So the project would include setting up a new translation project on the same Weblate server, integrating a suitable internationalization framework (i18next) and setting up a workflow for continuous translation updates.
This will enhance the user experience for non-English speakers and contribute to the growth of the BookBrainz community.
Goals
Here are a list of goals that would be expected for the project to be considered as completed. I have also listed optional goals in the end.
- Create a new project on the Weblate server specifically for BookBrainz translations.
- Configure the project settings and permissions for translators and reviewers.
- Install and configure the i18next library in the BookBrainz codebase.
- Implement the necessary components and frontend to display translated text in the application.
- Identify and extract as much as possible user-facing text that requires translation.
- Ensure that all text is properly formatted, divided into components and ready for translation.
- Create separate translation files and directories.
- Design a JSON/csv format for updating the translations.
- Documenting the Internationalization process used in BB in detail for future developers.
[optional]
- Translate a subset of BookBrainz text into Hindi to demonstrate the internationalization workflow.
Integrating the react-i18next framework
Upon exploring various options for internationalization such as Polyglot, LinguiJS, Globalize, FormatJS, Next-translate, and react-intl in React, I’ve chosen to use react-i18next due to its comprehensive features, ease of integration with React applications, extensive documentation, and other reasons mentioned below.
Why i18next?
- User Language Detection: i18next offers plugins that automatically detects the users language using various methods like cookies, sessionStorage, localStorage and htmlTags.
- Translation Loading: i18next offers convenient methods to load translations from the server, caching them in the local storage or combining both of them.
- i18n formats: There are a range of options such as fluent and basic JSON, allowing us to choose the preferred internationalization format that suits our needs.
- Flexibility: i18next is highly customizable, allowing us to use different date formatting libraries, adjust interpolation prefixes and suffixes, or even use gettext-style keys.
- Plugins and Utils: i18next offers a REALLY WIDE range of plugins/utils that can be used to customize our preferences as well as help in other features such as integrating backends, extracting text, post processing or creating our own plugins(mostly will not be required).
- Scalability: i18next supports the separation of translations into multiple files and loading them on demand, which is ideal for larger projects.
- Ecosystem: There is a robust ecosystem of modules built around i18next, including tools for extracting translations from code, bundling translations with webpack, and converting between different translation formats.
Preferred options in react-18next
- Format - I have chosen i18next JSON v4 as it is the default format for the i18next framework with dense documentation/examples available for referral. I18next-fluent was a close second but its complexity for translations is not necessary in our use case.
- Loading translations - For a large website such as BB with infrequent language switches and updates, caching translations would be preferred to enhance performance and reduce the number of calls to the server to fetch translations.
- Detecting user language: The built-in plugin i18next-browser-languageDetector can be used for this purpose and preferences will be paid to cookies and domain.
- Extracting text: i18next-scanner is an API which would parse through the codebase to get key-value pairs. (This would obviously require manual improvements and checks)
Capturing text for translation
- Identify all the texts that need internationalization based on the decided components. This will include all the alerts and messages as well.
- Mark the identified text for translation by replacing a hardcoded string such as “Welcome to BookBrainz” with t(‘welcome_to_bookbrainz’)
- Extract the strings using a builtin library by i18next which is called i18next-scanner and i18next-parser for this feature.
- Add these parsed json templates to their respective files in the locales folder.
- Provide the template file in .json format to the translators by uploading the locales folder to weblate
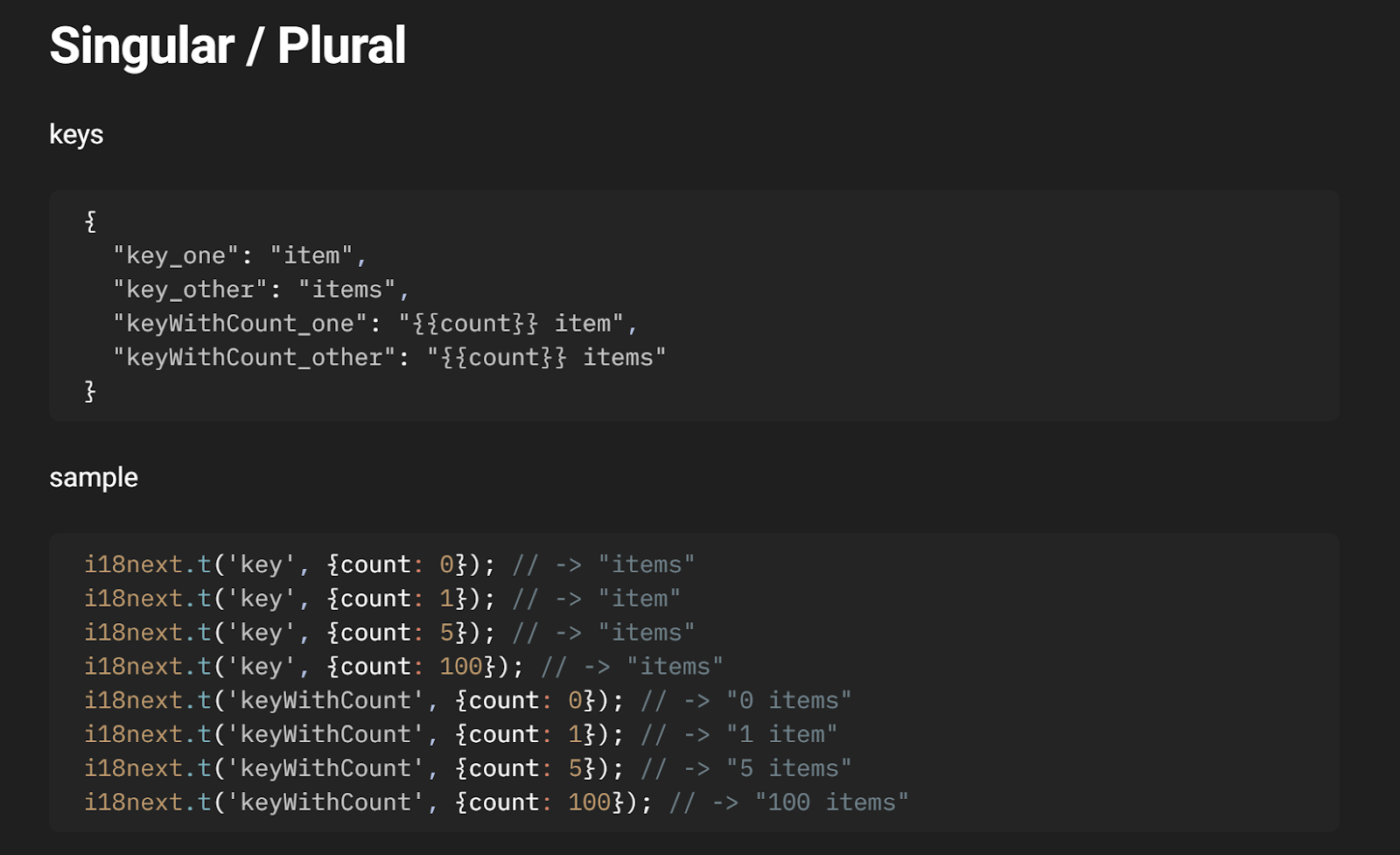
Managing dynamic texts, plurals and genders
- i18next provides us with handy features to manage plural translations an example of this is available on their documentation website which you can check out here: Plurals | i18next documentation
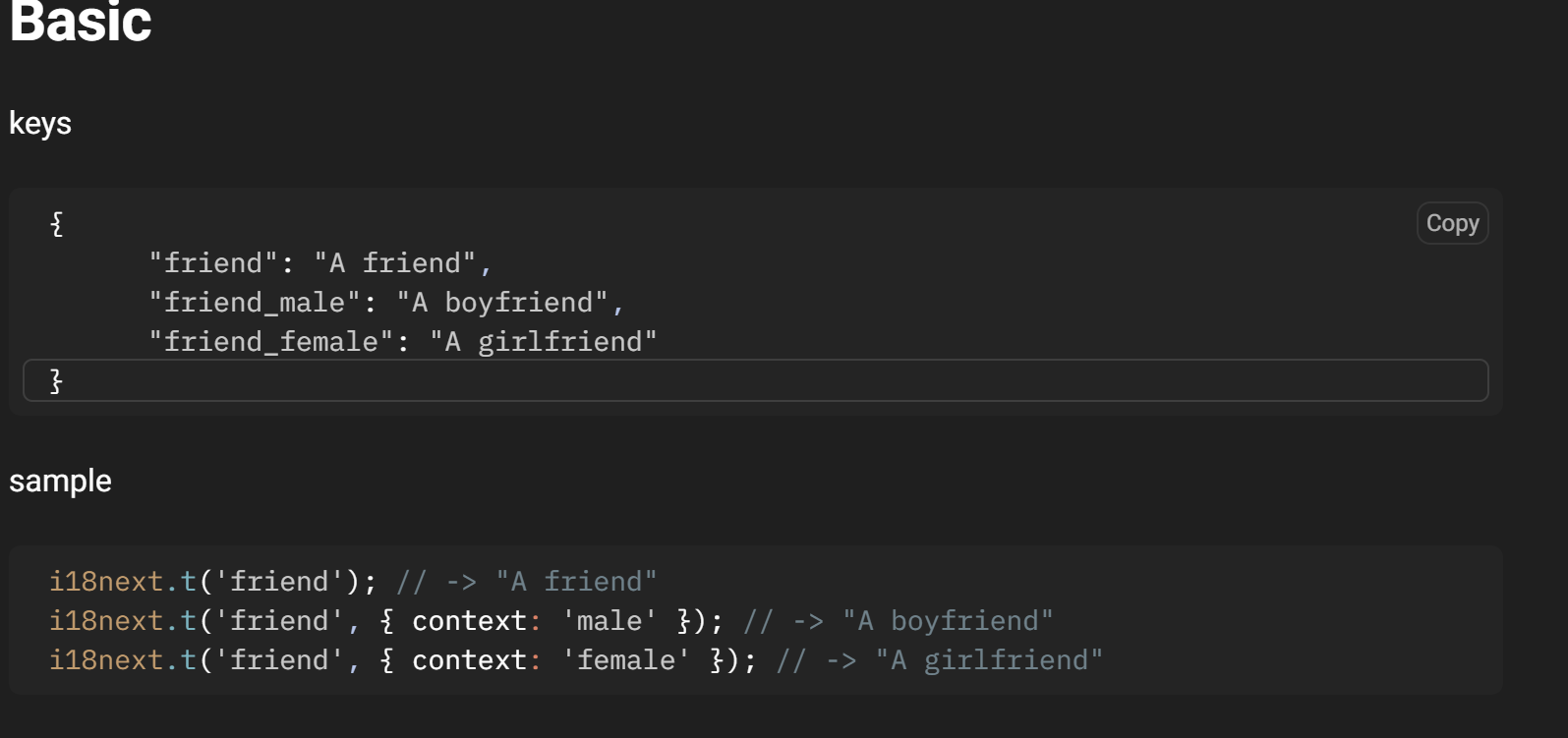
- Gender specific translations can also be mentioned with the help of prebuilt i18next function parameters such as this:
- Dynamic translations can be managed by using the interpolation functions provided by i18next which work like this:

Configuring i18next
The code for initializing i18next in a project using our desired options would look like this would look like this:
import i18next from 'i18next'
import { initReactI18next } from 'react-i18next'
import HttpApi from 'i18next-http-backend'
import LanguageDetector from 'i18next-browser-languagedetector'
import resourcesToBackend from 'i18next-resources-to-backend'
const i18nOptions = {
defaultNS: 'main',
supportedLngs: ['en', 'de', 'fr','hi'],
fallbackLng: 'en',
debug: false,
// Options for language detector
detection: {
order: ['path', 'cookie', 'htmlTag'],
caches: ['cookie'],
},
}
i18next
.use(HttpApi)
.use(LanguageDetector)
.use(initReactI18next)
.use(resourcesToBackend((language, namespace) => import (`/public/assets/locales/${language}/${namespace}.json`)))
.init({
ns: [ 'main','header','footer'],
i18nOptions,
})
Translation Files Structure
The files for translations will be stored in a folder structure as such.
-
Locales
-
<lang_name>
-
<namespace_name>.json
-
<namespace2_name>.json
-
<namespace3_name>.json
-
<lang2_name>
-
<namespace_name>.json
-
<namespace2_name>.json
-
<namespace3_name>.json
An example of this folder structure can be seen as in my demo website, which offers translations in four languages. These translations are further divided into three namespaces: header, footer, and main.

Essentially, namespaces in i18next are like categories or containers that group related translation keys together. This organization makes it easier to manage translations, especially as the project grows and becomes more complex. For example, in BB we can create a separate namespace for each of the different components such as Relationships, Attributes, Languages, Countries, etc.
This reduces the load on the server as namespaces are only loaded when a page requires them.
Demo Project
I have been experimenting with internationalization and here is a demo project in which I implemented it using a simple React App and i18next. I was focusing mainly on the working of translation. (Don’t focus on the UI, it was built in just a couple of days).
Translation Components
Here is the list of tentative components that will be set up for translation as of now.
Area
All the lists of places to display the birth/death places of the author and the place where a publisher is registered.
Entities
The entities - author, work, edition, edition group, publisher and series, and the way they are linked together allow us to describe what “a book” really is. So the translation of their name and description is essential.
Glossary
This includes different terms along with their meanings mentioned here.
Languages
This denotes the language that a book was written in.
Server
This denotes the messages and alerts shown on the screen to users by the BB server.
Work types
It contains all the types of work you can assign to a work/book. Also includes their description. Reference given below -
Relationship Names
Includes only the different relationship names as mentioned here.
Relationship Descriptions
This includes all the additional details for the relationships. Reference given below -

Achievements and Profile
It includes all the achievements from Achievement_type as well as the profile details of each user.For example the attributes of this user:
Setting up Weblate
Create a new weblate project
On the existing weblate server of MetaBrainz (https://translations.metabrainz.org/), we will create a new project for Bookbrainz.
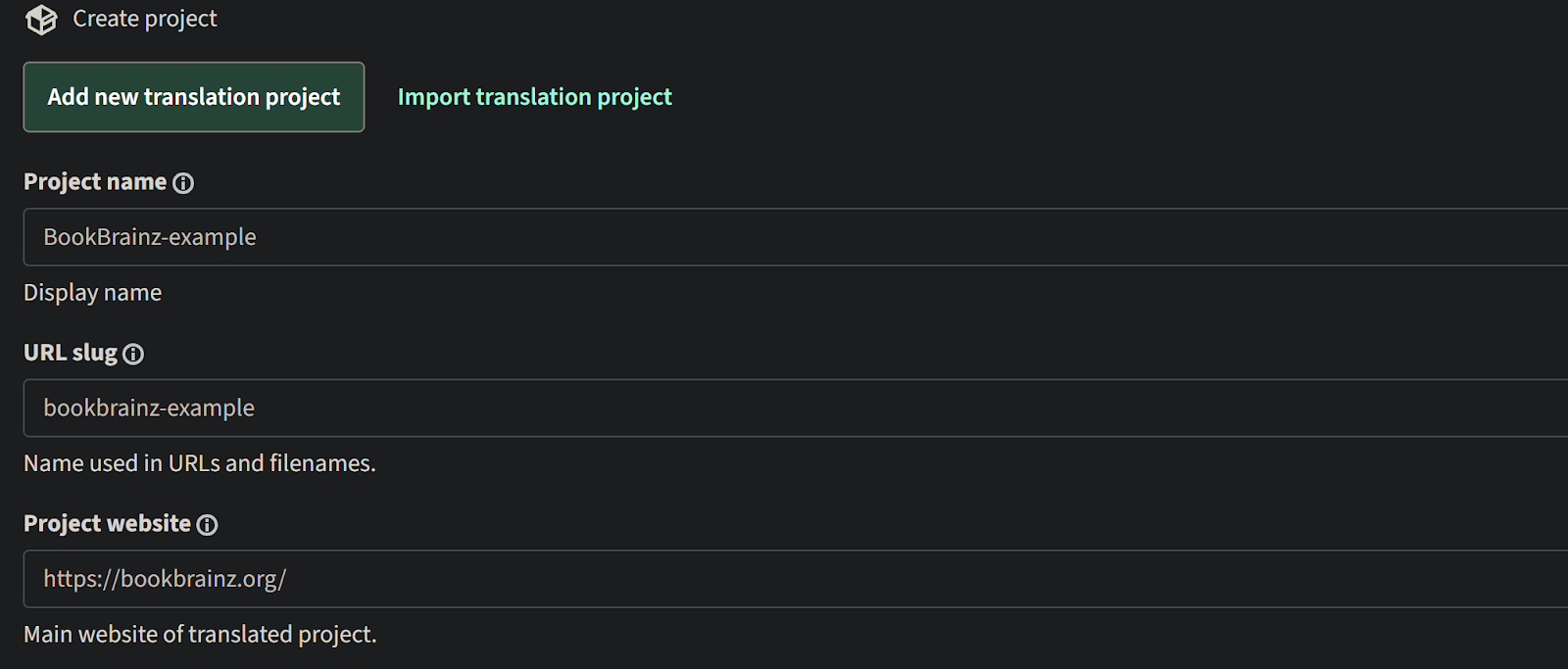
Connect it to the BB Github Repository
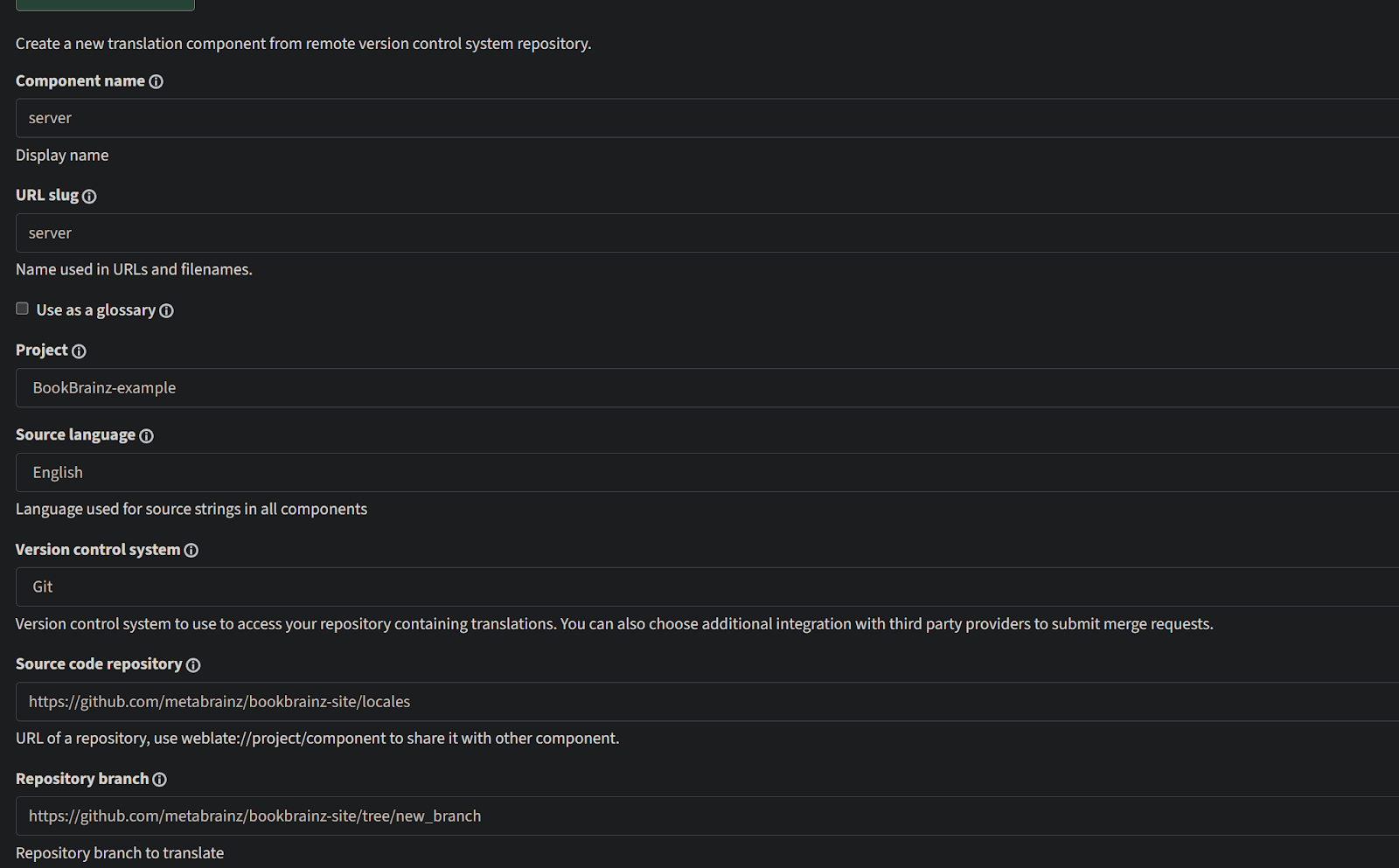
We will create a new component and then link it to our github repository as follows. A new branch for managing these translations will also be required. Afterwards an SSH key will need to be added for authentication purposes.
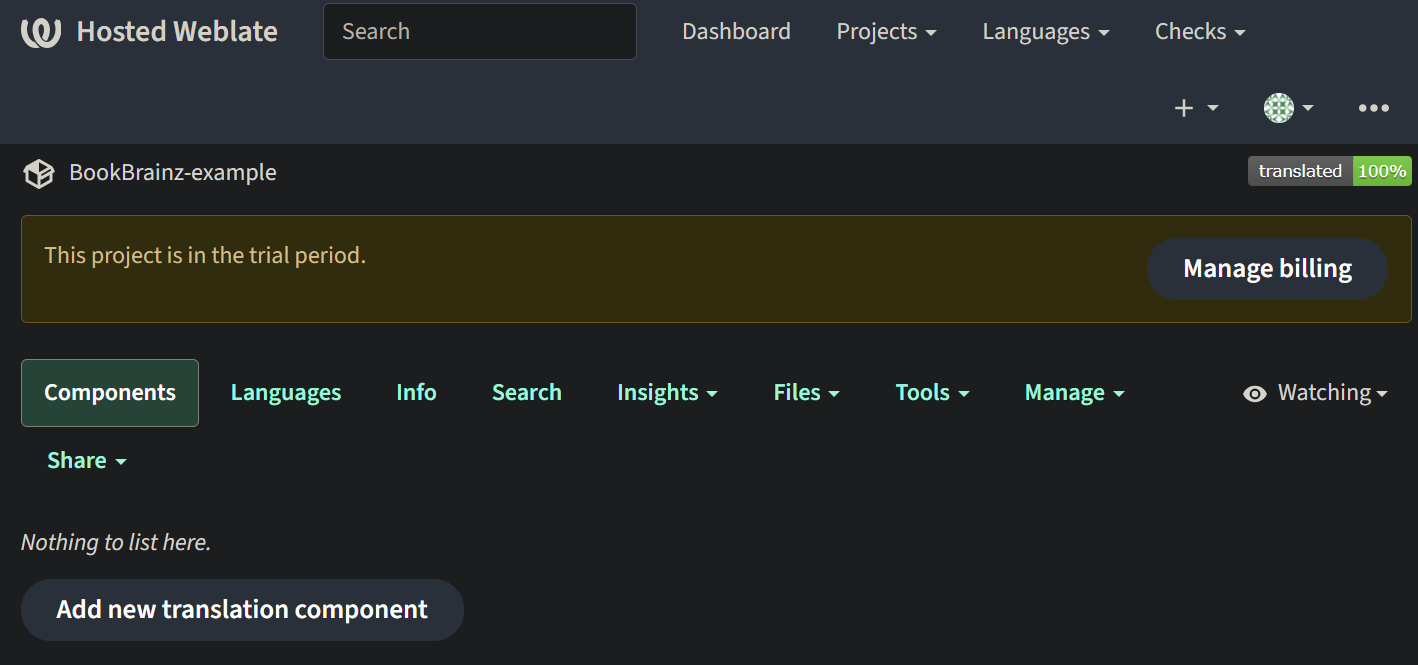
Adding all the valid Components to weblate
The created project in weblate is like a shelf, in which real translations are stacked. All components in the same project share suggestions and their dictionary; the translations are also automatically propagated through all components in a single project.
Components are added directly on the weblate server from their project homepage by using the desired configurations. Here are some snapshots from the weblate server site which would help give an overview of how that looks.
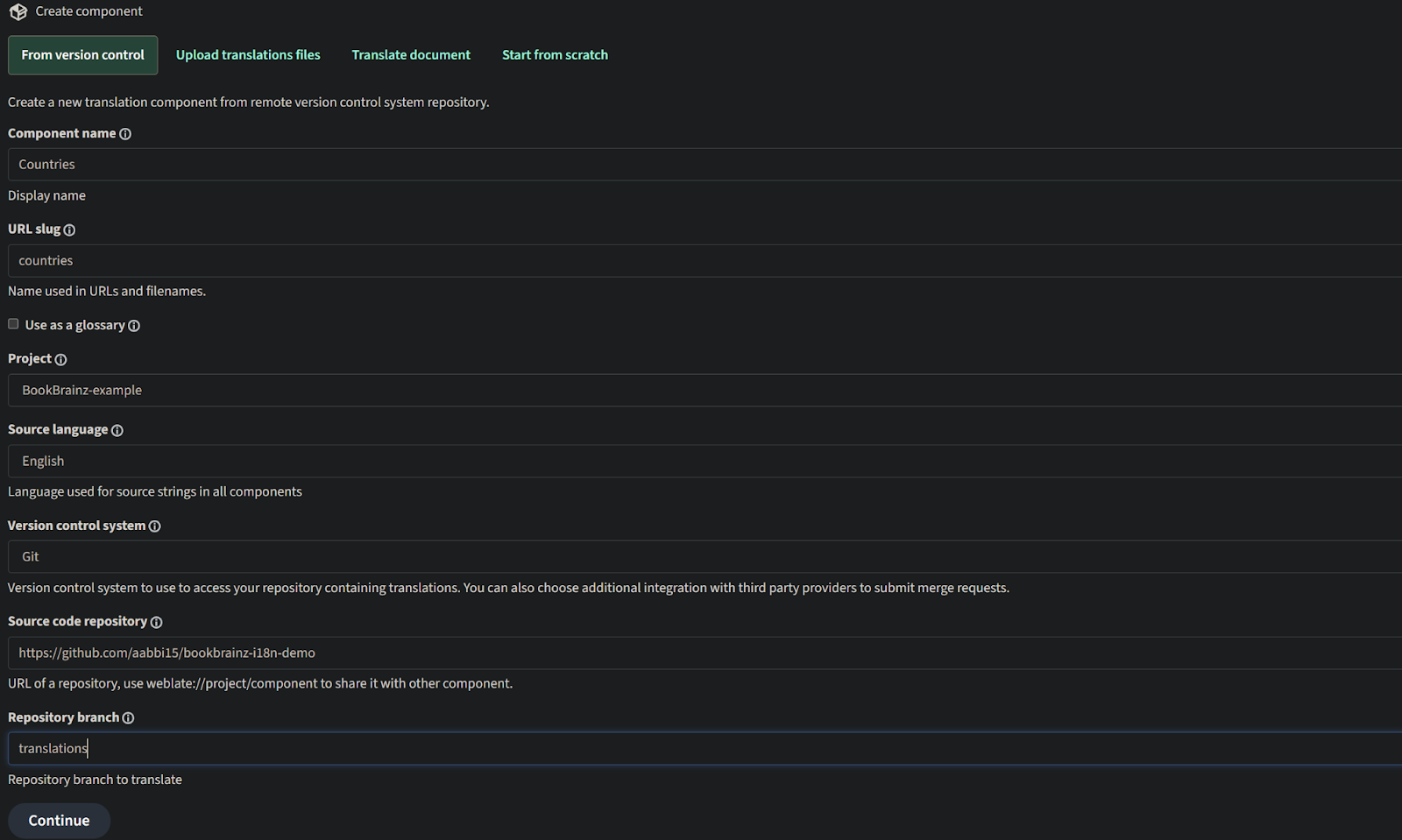
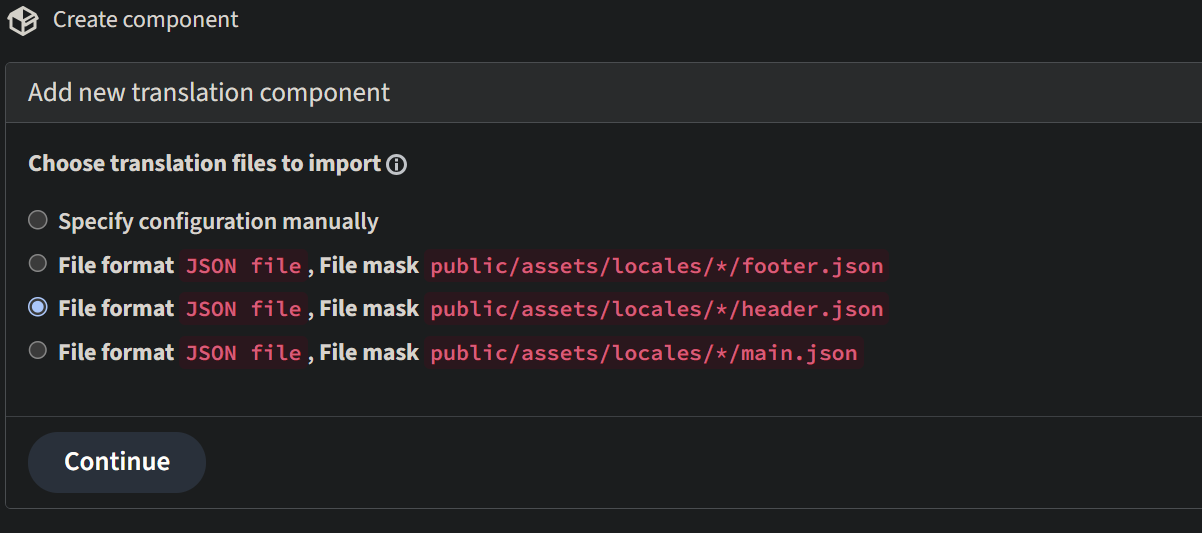
Once added, weblate automatically detects the translation files and the added component looks like this.

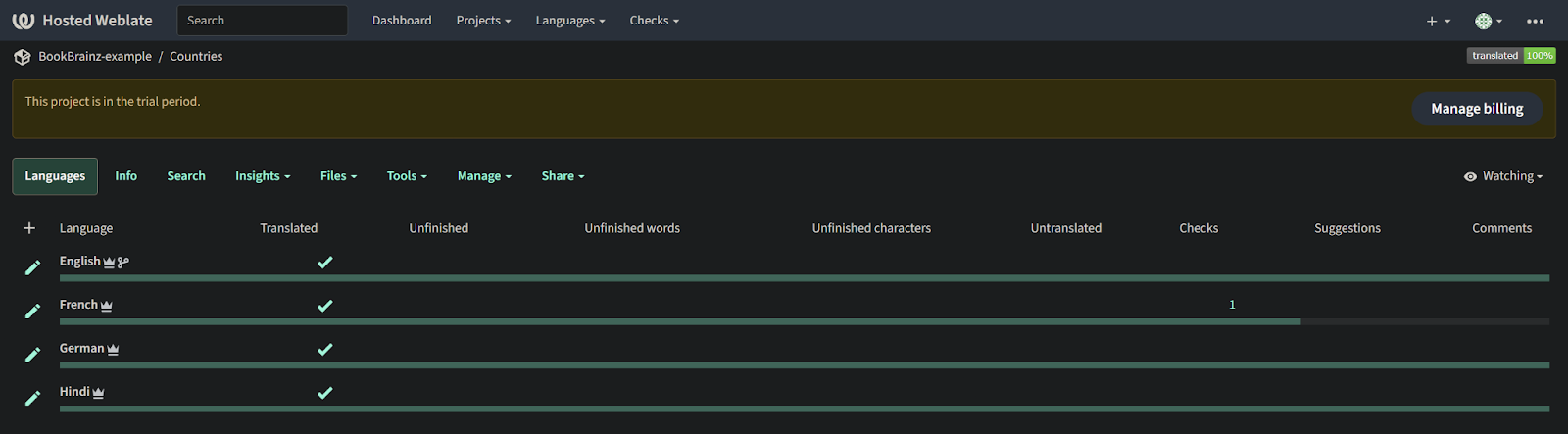
Workflow
- Repository Structure:
- locales-dev Directory: Located within the main repository, this directory is used by developers to add or update translation keys and default translations.
- locales Directory: Also within the main repository, this directory is used for production-ready translations and is managed by Weblate.
- Development Process:
- Developers work on translations in the locales-dev directory.
- When translations are ready to be moved to production, the ops team copies the updated content from locales-dev to locales through a pull request for review and version control.
- Weblate Integration:
- Weblate is configured to track the locales directory for translation changes.
- A webhook triggers Weblate to update its translation projects when changes are pushed to the locales directory.
- Translators provide translations within Weblate, which are periodically committed back to the locales directory but not automatically pushed.
- Deployment:
The deployment process includes the locales directory, ensuring that the live website serves the latest approved translations.
- Continuous Translation:
The workflow repeats with developers updating the locales-dev directory, the ops team handling the transfer to locales, and translators working in Weblate.
Tests
Key Consistency test
Used to check if the names of the keys are consistent across all languages. The code for it could look something like this:
const fs = require('fs');
const path = require('path');
const localesDir = path.join(__dirname, 'locales');
const languages = fs.readdirSync(localesDir); //this reads all languages
let referenceKeys = null;
let valid= true;
languages.forEach((language) => {
const languageDir = path.join(localesDir, language);
const files = fs.readdirSync(languageDir);
files.forEach((file) => {
const filePath = path.join(languageDir, file);
const translations = JSON.parse(fs.readFileSync(filePath, 'utf8'));
const keys = Object.keys(translations);
if (referenceKeys === null) {
referenceKeys = keys;
} else {
// Check consistency with the set keys
const missingKeys = referenceKeys.filter((key) => !keys.includes(key));
const extraKeys = keys.filter((key) => !referenceKeys.includes(key));
if (missingKeys.length > 0 extraKeys.length > 0) {
valid= false;
console.error(`Inconsistency found in ${language}/${file}:`);
if (missingKeys.length > 0) {
console.error(` Missing keys: ${missingKeys.join(', ')}`);
}
if (extraKeys.length > 0) {
console.error(` Extra keys: ${extraKeys.join(', ')}`);
}
}
}
});
});
if (valid) {
console.log('All translation files are OK.');
} else {
console.error('Error! Check above logs');
}
Missing translation files check
Used to check that files for all components are present in the folder for each language. It could look something like this:
const fs = require('fs');
const path = require('path');
const localesDir = './locales';
const languageCode = 'en-US'; // Language code to check make it into a //variable later on as number of languages increase
function getTranslationFiles(dir) {
return fs.readdirSync(dir)
.filter(file => path.extname(file) === '.json')
.map(file => path.basename(file, '.json'));
}
function checkMissingTranslations() {
const folders = fs.readdirSync(localesDir).filter(folder => fs.statSync(path.join(localesDir, folder)).isDirectory());
const referenceFiles = getTranslationFiles(path.join(localesDir, languageCode));
folders.forEach(folder => {
if (folder !== languageCode) {
const folderFiles = getTranslationFiles(path.join(localesDir, folder));
const missingFiles = referenceFiles.filter(file => !folderFiles.includes(file));
if (missingFiles.length > 0) {
console.log(`Missing translation files in '${folder}': ${missingFiles.join(', ')}`);
} else {
console.log(`No missing translation files in '${folder}'.`);
}
}
});
}
checkMissingTranslations();
JSON validity check
Since our translation files would be stored in a JSON format. We would need to check that the updated files are correct. The code would look something like this:
const fs = require("fs");
const path = require("path");
const { argv } = require("process");
if (argv.length != 3) {
console.error(
"This script takes exactly one argument: `node checkJSONValidity.js <path_to_directory>"
);
process.exit(1);
}
console.log(
`Recursively validating JSON files in the '${argv[2]}' directory...`
);
function* walkSync(dir) {
const files = fs.readdirSync(dir, { withFileTypes: true });
for (const file of files) {
if (file.isDirectory()) {
yield* walkSync(path.join(dir, file.name));
} else {
if (file.name.split(".").pop() === "json") {
yield path.join(dir, file.name);
} else {
continue;
}
}
}
}
// for each files in locales directory, we check json validity
for (const filePath of walkSync(`${argv[2]}`)) {
try {
let rawdata = fs.readFileSync(filePath);
JSON.parse(rawdata);
} catch (e) {
console.error(`Error while parsing json file '${filePath}'`, e);
return 1;
}
}
console.log(`Success! all JSON files are valid.`);
return 0;
Timeline
-
May 1 - May 26: Community Bonding period
-
Go through the documentation of i18next thoroughly.
-
Dive deep into the weblate documentation for configuration of the github repository to our weblate server.
-
Connecting with monkey and other project mentors to discuss the project and in general the future of MetaBrainz.
-
May 27 - June 2: Coding period - Week 1-2
-
Install the required libraries and check their version requirements.
-
Set up all the directories and files required for translation at their correct location.
-
Configure the i18next options correctly according to the required need and initialize it.
-
Create a new Weblate project for BookBrainz in the existing server. Configure project settings and required permissions.
-
Focus on translating the homepage of the website first in a couple of languages (For eg. Spanish and French).
-
Identify all the user-facing text in the homepage that needs translation.
-
Start marking the identified texts with t(‘ ’) tags from i18next.
-
Setup the locales directory required for storing the translation files.
-
June 10 - June 16 : Coding period - Week 3
-
Add a temporary test-homepage component in the BB Weblate project.
-
Add the user-facing (now marked text) to the translation files.
-
Merge the weblate server with the locales folder for translators to access the translations.
-
Add a few mock translations and check if it is being displayed correctly.
-
June 17 - June 30: Coding period - Week 4-5
-
Now, identify all the user-facing text that needs translation for a particular subset of BookBrainz.
-
Start tagging them with the
t(‘ ‘ )tags provided with the useTranslation() component from i18next. -
July 1 - July 7: Coding period - Week 6
-
Parse the user-facing (now marked text) using i18next libraries to extract the text in desired .json format.
-
Divide the said text into components and add them to their .json files.
-
Finish setting up all the translation files in the locales folder according to their respective components by dividing them into namespaces.
-
July 8 - July 14: Coding period - Week 7
-
Buffer week
-
Write documentation for the work done until now.
-
Prepare a mid-evaluation report
-
Mid Term Evaluation
-
July 15 - July 21: Coding period - Week 8
-
Work with translators to translate a subset of BookBrainz text into any target language.
-
Ensure the workflow for getting translations and implementing them in the server is done correctly for the translated subset of BB.
-
Write tests.
-
July 22 - July 28: Coding period - Week 9
-
Test the internationalization workflow and ensure that translations are displayed correctly in the application.
-
Make sure to capture as much text as possible for translation. And continue adding them to translation files.
-
July 29 - September 4: Coding period - Week 10-11
-
Continue testing the internationalization implementation.
-
Fix any required bugs and make any necessary adjustments based on feedback from translators and the mentors.
-
Develop automated tests to verify the functionality of our i18n implementation.
-
September 12 - September 18: Coding period - Week 12
-
Buffer Week
-
Write documentation for the complete workflow.
-
Prepare the final evaluation report.
-
Final Evaluation
The buffer weeks are stored in case I fall behind schedule in any of the weeks. Otherwise I would continue the work in order by doing the work for the upcoming week.
About Me
Hey! I’m Abhishek Abbi, a BTech student at DA-IICT. I’m all about diving deep into the world of web development and bringing cool ideas to life. I’m part of the Google Student Developers Club at my college, where we geek out on coding and collaborate on some pretty awesome projects.
I’ve had the chance to intern as a full-stack developer at Maitri Manthan and PGAGI, and let me tell you, it’s been a blast! From brainstorming ideas to launching them into the real world, I’ve learned a ton and had a lot of fun along the way.
When I’m not coding, you can find me on the football field or working out in the gym. I find it really comforting to stay active. Plus, it’s a great way to relax after a long day behind the desktop!
When did I first start programming?
I first started programming when I was 16 years old, in my 10th grade. I found programming very fascinating from what I was taught in my school and so decided to join coaching classes to learn more about it. My first real coding experience there was in C++, where I learnt the basics of data structures and Object oriented programming.
Since then, it has been a really amazing journey towards cracking a good IT college, learning web Development with React, making a ton of projects and now contributing to open source.
My contributions at BookBrainz
I have been active in both the BookBrainz and MetaBrainz IRC channel from January. Due to health issues, I was unavailable for a couple of weeks in between. SInce joining, my main focus was getting to know the BB codebase and working structure really well. I have also attended a few of the Monday weekly meetings that occur and shared my work progress as well as gained insights from the devs.
I have worked on a few tickets until now and all of them have helped me in understanding the BB code even better. The tickets focused on updating SQL databases, fixing a RegEx bug in the code and also adding a new feature for allowing users to choose dimension units.
This was the first major Open Source Org that I have contributed to and so the learning was hard but I believe I am up to speed with the codebase now to make even faster contributions. Here are my PRs for BookBrainz along with a few tickets I have been working on:
- #1073 Add begin date and end date attribute to relationship
- #1050 fix(revision): Links with symbols like % - # now work
- BB-490 Allow attributes on relationships
- BB-770 “Stay on beta” style cookie
- BB-620 Allow measurements in more formats
Personal Projects and Experience
I have been building projects since the past couple of years and here are a few of them:
- Maitri Manthan Internships: This website was a complete end to end project built by me during my duration of internsip at Maitri Manthan Org. It offers remote internship offers for people to contribute to the society. Check it out live here
- PG-AGI website: While I was working at this startup, I made a landing page with call-booking features and other designs for them. YOu can check it out live here
- Portfolio: This was my personal portfolio built using NextJS, Tailwind CSS, NodeJS and other React frameworks for email service as well as UX/UI components. You can see it live here.
- There are many more projects including React Apps, Python scripts and Web-scraping apps that I have made personally in my free time that you can see in my portfolio mentioned above..
What type of music do I listen to?
I am really involved in almost all kinds of music. My favorite kind of music is mostly soft songs with really good vocals. Some of my favorite singers include
- Ed Sheeran(b8a7c51f-362c-4dcb-a259-bc6e0095f0a6)
- Arijit Singh(ed3f4831-e3e0-4dc0-9381-f5649e9df221)
- Zayn Malik(985f7e6f-0a7e-4de7-b9ec-a5dac63cb2f7)
- Harry Styles(7eb1ce54-a355-41f9-8d68-e018b096d427)
I have also lately been getting into hip-hop a lot these days with tracks from these being on my repeat list.
- Central Cee(b0337af1-8d93-4671-b6c9-ba306bf942bf)
- Dave(f93bac9e-b20a-403e-abc9-06a2fc151df1)
- KR$NA(86ba68eb-ea24-4e78-a009-b35e99cb6193)
Here’s a few of my all time favorite songs along with their MBIDs:
- Hotel California (b934e019-9426-4091-a1c4-6b7590dc6c47)
- Watermelon Sugar (803eb995-2b7b-4a35-8d11-db2c9ff54989)
- Sprinter (cd3bde26-2929-4404-86ef-4623e57b66cd)
- No Cap (cea2e106-7d27-4917-84da-f0ba99170b57)
- Tum Hi Ho (52ce59d7-9d12-405a-acbb-1e50970b81bb)
- Trampoline (04430b31-0159-4b3c-bf2b-a7ac806535dd)
- Shada (ea7cc5a7-2b89-4966-9903-1c1ee5a7cfe0)
What type of books do I read?
I mostly read self help books as I feel it helps me grow and become a better person. Occasionally, I indulge in some short-fiction books and comic books just to relax my mind for a while. Here’s some books which I have read along with their BBIDs:
- Atomic Habits (20055e91-d0e9-446b-a841-aafa3eff6441)
- The Psychology of Money (10fb9c4f-21b9-4c9c-9d7a-9aad275a7d31)
- Diary of a Wimpy Kid (ed472f1-ef3c-45cb-9350-f05aa065e86c)
- Deathnote Manga (8b467e1c-72e9-4654-9212-bb4559a8eec8)
What about BookBrainz intrigues me the most?
I feel that BookBrainz holds two important use cases that the users would benefit from:
- Sometimes I want to get resources about a book online but there are a lot of different articles/blogs offering reviews. The articles can be biased sometimes and I feel there is a need for all of this data to be concentrated into one place where I can get the history, the facts, the reviews as well as the description in one place.
- With the abundance of Ebooks and audiobooks in the market now. Maintaining a record of a book you have read/want to read would be much easier with the help of software rather than a physical library.
- BookBrainz can also kind of serve as a platform to find people who read the same books as you and connect to them. This can be done by checking out their public Collections. This feature is really good for finding reading buddies.
I feel once BookBrainz is filled abundantly with a lot of data it will become a really exciting platform for not only gathering book data but also to connect eith other fellow book readers.
Practical Requirements
My current computer during GSoc 2024
I have a Samsung Galaxy Book 3 Pro 360 with a 13th Gen Intel(R) Core™ i7-1360P 2.20 GHz Processor, 16 GB RAM, 1TB SSD, 64-bit operating system, x64-based processor, pen and touch support which is running Windows 11.
How much time will I dedicate?
I will be on my college summer break during the coding period for GSoC, which starts from May 27. So, this project will be my major focus during that period of time.Hence, I will be able to dedicate around 25-30 hours per week for the project.
This Is a tentative proposal and I would love some improvements/feedback from your side.