Revamped LastFM Listens Importer
Proposed mentors: lucifer
Languages/skills: Python/Flask/ReactJs
Estimated Project Length: 175 hours.
Expected Outcomes: An improved importer for LastFM users to import their listens into ListenBrainz.
Project Summary:
This proposal aims to create an importer similar to the SpotifyUpdater, which operates on the backend and consistently updates ListenBrainz with the user’s Spotify streams. A UI component will be developed to facilitate user configuration, along with a REST API to handle requests.
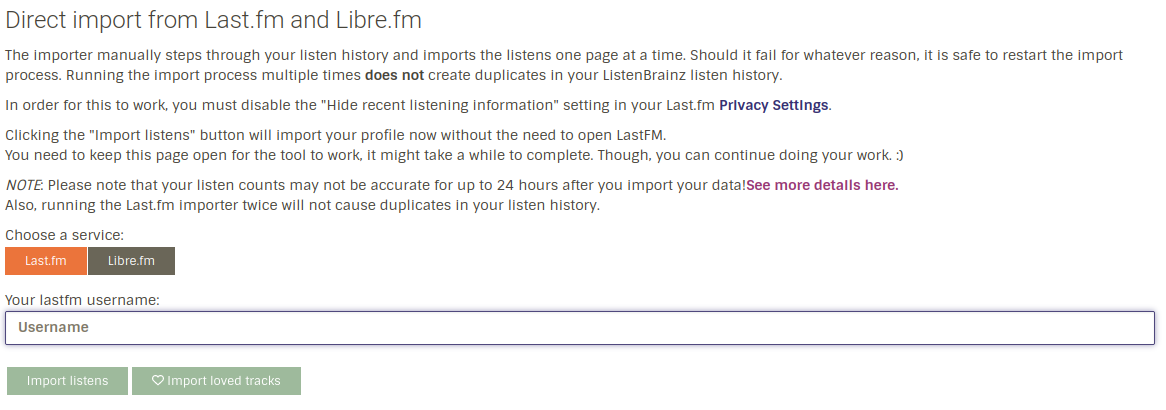
Currently, ListenBrainz features a LastFM importer written in Typescript that operates within the user’s browser. This is a one-time import process that requires manual triggering each time. Users must also keep their browser tab open during the import process, and there have been reported issues of it being blocked by uBlock.
Personal Information
Name: Chong Yong Kin, my friends call me Yongkin.
Discord: couscous4304, IRC: ykc
Email Address: ykchong45@gmail.com
Github: https://ykchong45.github.io
Location: Tokyo, Japan
Time Zone: GMT+9
Company: LP Research Inc.
Degree: Electronic Information and Technology (Bachelor of Engineering)
Introduction
Hello everyone, my name is Yong Kin, also known as ‘couscous4304’ on Discord (yes, I’m the bowl of couscous ![]()
![]() ) and ‘ykc’ on IRC. I’m from Malaysia and have been working in Tokyo with LP Research Inc. for a little more than 2 years on sensor fusion and VR solutions. I completed my undergraduate degree at Tsinghua University in Beijing, China in 2021. During my free time, I like swimming, skating, playing the piano, and meeting cool people! For my passion for music, I listen to anime songs, movie and game original soundtracks, and would heavily track my listened songs.
) and ‘ykc’ on IRC. I’m from Malaysia and have been working in Tokyo with LP Research Inc. for a little more than 2 years on sensor fusion and VR solutions. I completed my undergraduate degree at Tsinghua University in Beijing, China in 2021. During my free time, I like swimming, skating, playing the piano, and meeting cool people! For my passion for music, I listen to anime songs, movie and game original soundtracks, and would heavily track my listened songs.
Goals of the Proposal
- Develop a Python-based LastFM scrobble importer to run on the server side, in coordination with database table
external_service_oauth. - Create an UI component to update the linked username of LastFM, working in conjunction with the API function
music_services_disconnect(). - Document the process for adding new importer support for new streaming services.
- [Extended Feature] Develop an asynchronous processing API for frontend requests to import listens.
For the sake of completeness, I will first analyze the spotify_updater as a point of reference. Subsequently, I will illustrate the plan for constructing each component required for the last_fm_importer.
Spotify Updater - As Reference
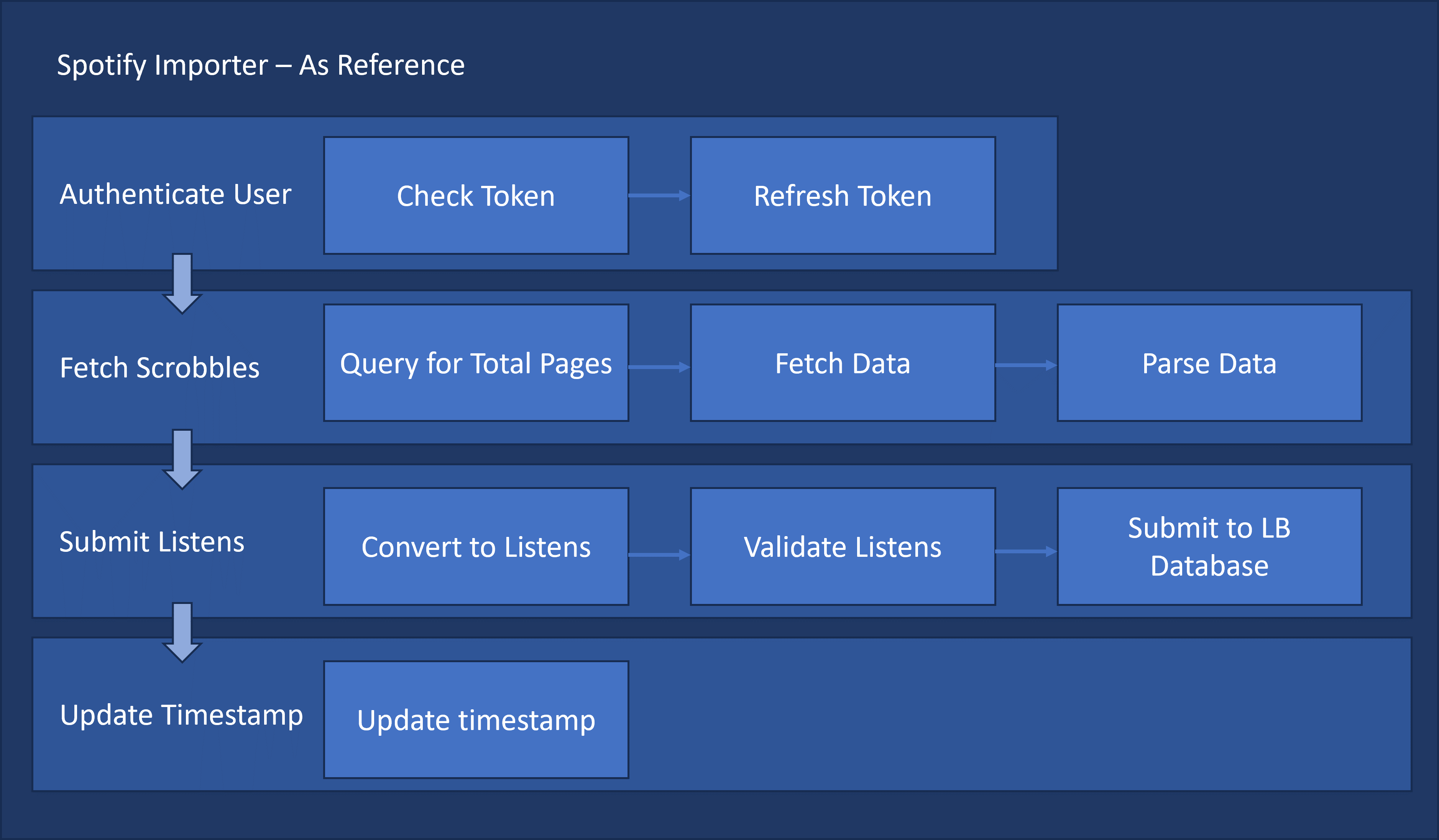
For reference, the spotify_updater script is invoked at regular intervals to import all users’ Spotify listening data into ListenBrainz’s database. process_one_user() function serving as the core, submitting a user’s recently played songs to LB’s database. The function’s workflow can be outlined as follows:
- If
user_oauth_token_has_expired(), callrefresh_access_token()then: get_user_currently_playing()andparse_and_validate_spotify_plays()get_user_recently_played()andparse_and_validate_spotify_plays()- If no listens are received, call
update_user_import_status(). Otherwise, callsubmit_listens_to_listenbrainz()and returnlen(listens). - Call
update_latest_listen_ts().
Using this code as a reference, we know that an importer relies on 5 components:
- Service class:
SpotifyService, which manages user authentication tokens. It talks to database tableexternal_service_oauth, which stores access tokens for various services.- Importer Core:
process_one_user(), responsible for getting and parsing listening data.- Utils:
webserver.views.api_toolsmodule, which contains functions for validating and submitting listens to the database. (I will leverage this existing code)- UI: A form for collecting and displaying the user’s connected services configurations.
- REST API: Handles requests for adding / removing connected services.
Component Designs
The number in each block in the diagram corresponds to the 5 components listed in the previous section, while E. indicates the extended feature. In this section, I will provide detailed implementation plans for blocks 1 through 5, as well as for the extended feature denoted by E.
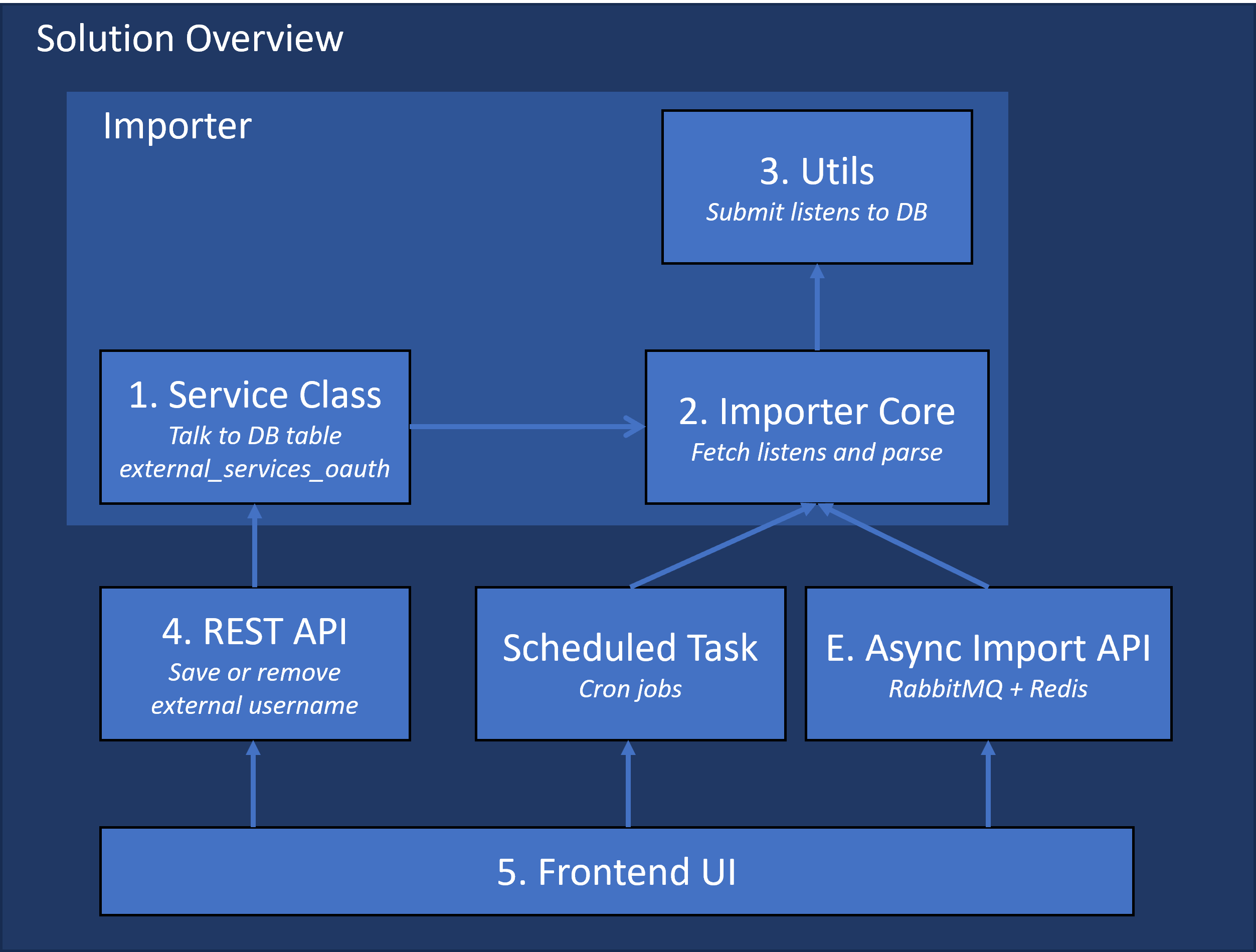
1. Service Class
When fetching listen data from LastFM, it doesn’t require API keys from individual users. Therefore, in the database table external_service_oauth only user_id, external_user_id, and service need to be stored, without access and refresh tokens.
Please refer to domain/spotify.py and db/external_service_oauth.py.
2a. Importer Core Part 1/2 - Getting Scrobbles
The current LastFM Scrobble importer is implemented in TypeScript integrated within the React framework, and I will translate it into Python. Its core functionality, startImport(), focuses on importing from the oldest scrobbles, with importLoop() performing the following tasks:
getTotalNumberOfScrobbles()andgetNumberOfPages(): Prefetch scrobbles’ total count and page counts.getPage(): Fetch and parse the scrobbles into ListenBrainz’s standardized listen format. Right now it returns in the following format:
[
{
"track_metadata": {
"track_name": "Time (Alan Walker Remix - Extended Version)",
"artist_name": "Alan Walker, Hans Zimmer",
"additional_info": {
"submission_client": "ListenBrainz lastfm importer"
}
},
"listened_at": "1710934307"
}
]
submitPage(): Submit the parsed data to ListenBrainz’s backend API.
This process uses LastFM’s user.getRecentTracks API.
2b. Importer Core Part 2/2 - Parsing and Storing
After getting the listen data from LastFM, I will modify the record_listens() from webserver.views.api_compat.py, to parse and submit LastFM listening data to the database:
- get the current
userfrom the database tableuser. - parse LastFM format
datainto alookupdictionary - then parse the data again with
_to_native_api()into the listen formatnative_payload, along with alisten_type. - validate the parsing result.
- populate
user_metadataand submit withinsert_payload().
In addition to the steps above, the code should make a call to listens_importer.update_latest_listened_at().
3. Utils - Submitting to Database
This section contains functions used by spotify_importer for parsing and submitting listen data to the database. The LastFM importer can leverage the existing functions. Check them out in api_tools.py.
4. UI
The existing UI allows users to configure their connected services in two different places. For my task, I can modify it to use either of these:
settings/import/ImportListens.tsx: This component has an input box where users can enter their LastFM username.
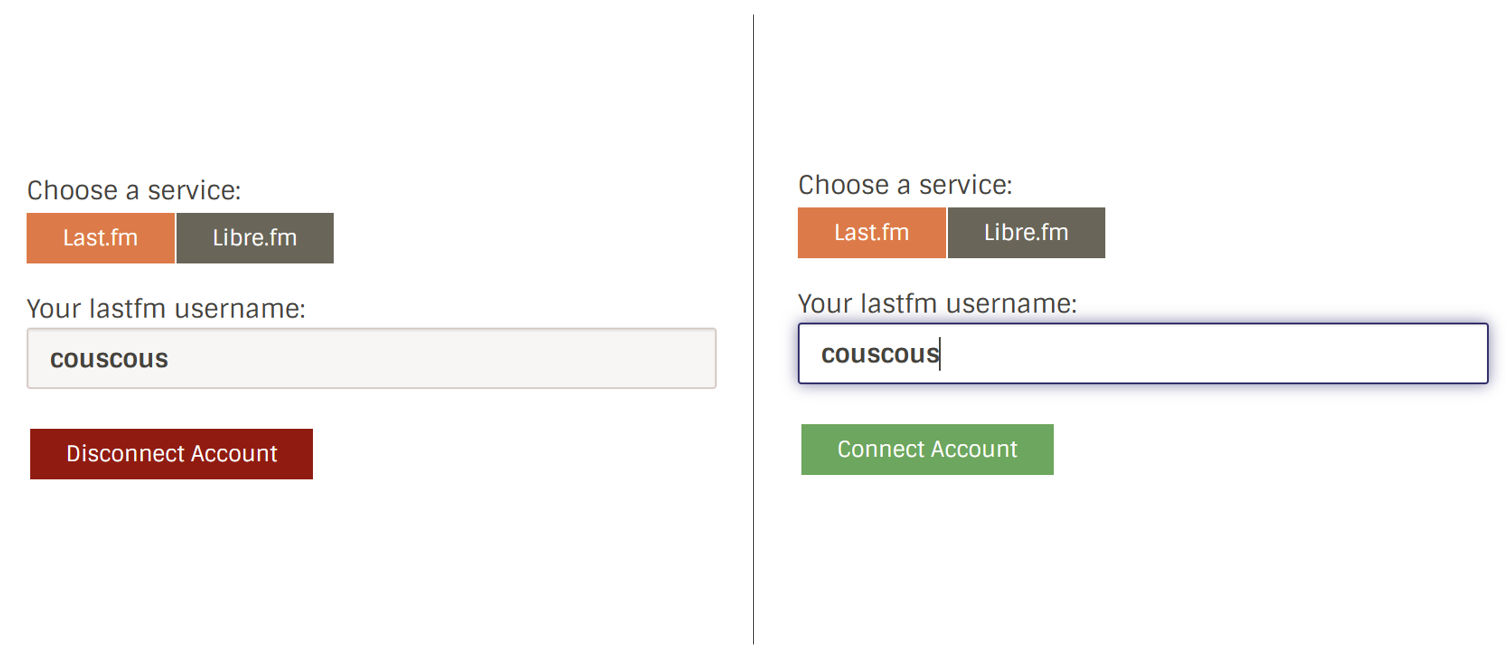
settings/music-services/details/MusicServices.tsx: This component facilitates user connections and disconnections to/from external services. Clicking the “Play music on ListenBrainz” button (right) triggers a modal where users can input their information (left).
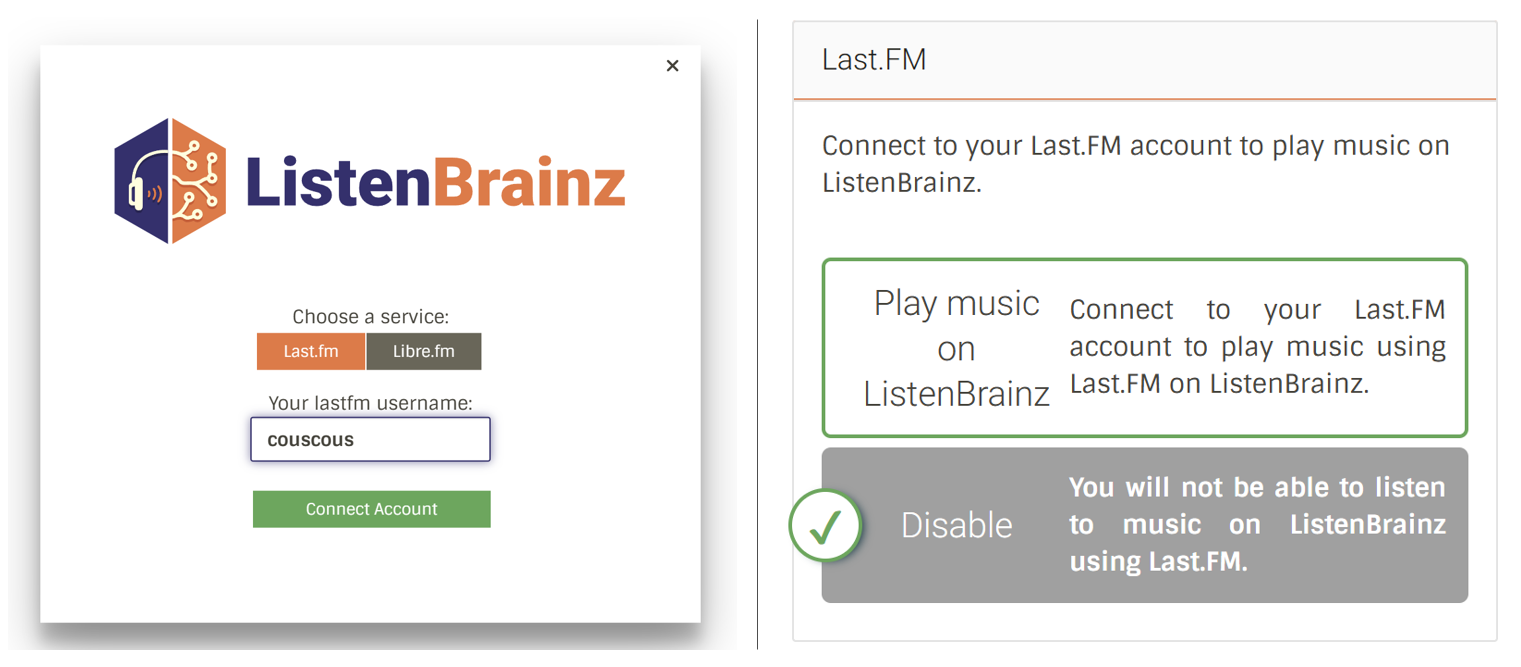
In either way, a user will have access to an interface with a form to achieve the following:
-
Collect LastFM username, submit to the REST API, and save it in the database.
-
Request the REST API to delete the saved record of the LastFM username.
5. REST API
I plan to extend the current API function music_services_disconnect() to record or remove the LastFM username linked to the ListenBrainz user. Since both services do not involve redirection to external pages and only involve modifying the record in the database table, the logic is simple:
def music_services_disconnect(service_name: str):
...
elif service_name == 'lastfm':
external_service_oauth.save_token(...)
return jsonify({"success": True})
E. Async Import API [Extended Feature]
A valuable addition would be to transform the LastFM and Spotify importers into on-demand APIs, allowing users to initiate updates as needed. To ensure the frontend isn’t delayed during the import, tasks should be executed asynchronously in the backend, and a rate limiter will help safeguard this feature from abuse. The community can discuss the feasibility and usefulness of this feature, and I would propose listing it as an extended feature for this project. RabbitMQ has been selected as the message broker because it facilitates reliable message delivery and scalable asynchronous task processing.
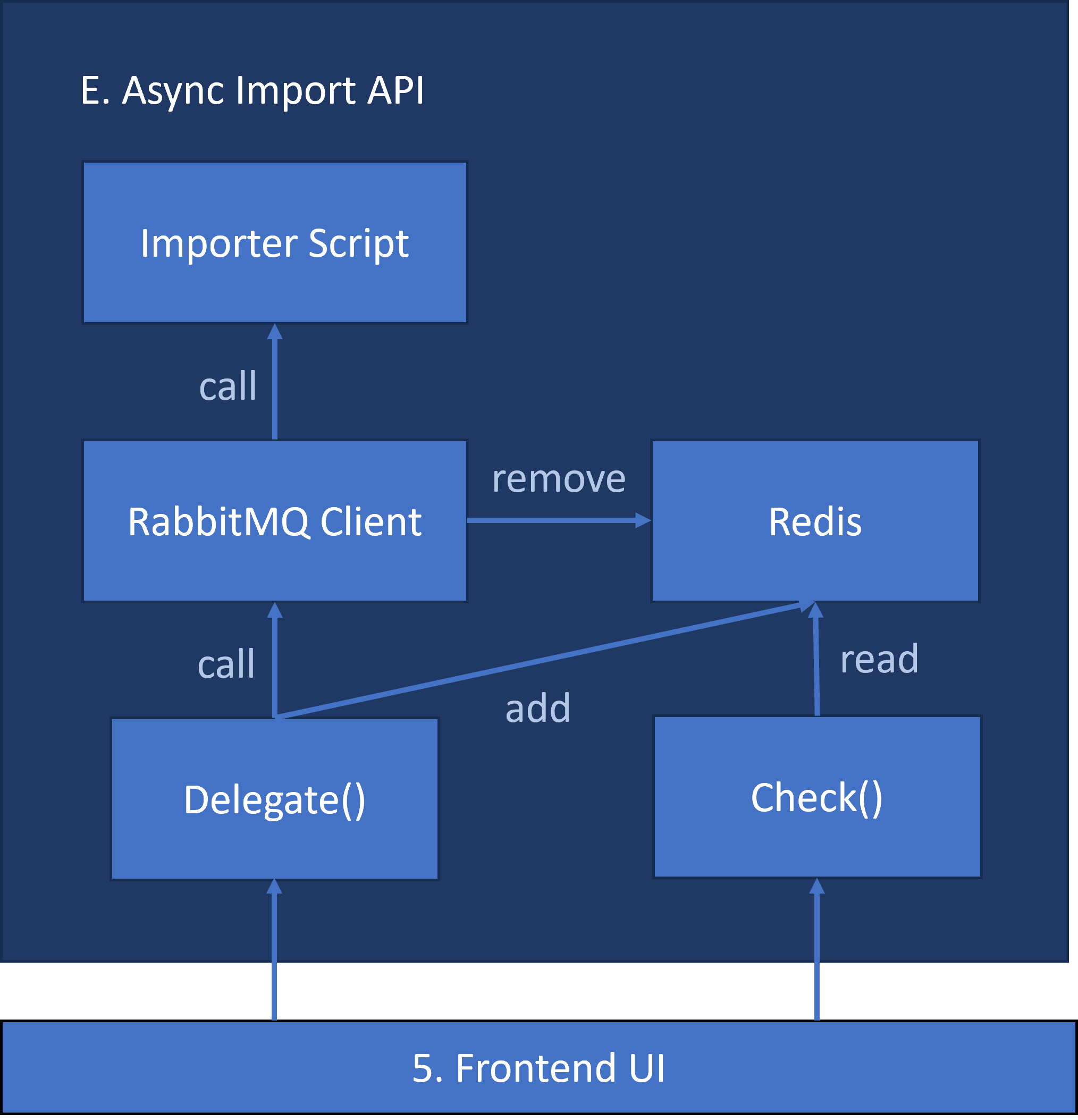
Plans on this task:
- Implement RabbitMQ client based on the asynchronous consumer example. Utilize the
on_message()to calllast_fm_importerAPI. - Maintain a Redis set to store
userID_importServiceNameitems, and remove upon processing completion. Develop an API to check processing status. - Test this API through scripts and UI. Ensure an easy way to verify if their task is in the queue by querying the
check()endpoint.
Timeline
| Time | Plan |
|---|---|
| Before the GSoC | - Discuss details of the project with Lucifer, go over the implementation of Web API endpoint. - Work on open tickets to explore the RabbitMQ usage in the project and Troi recommendation. |
| Week 1 | Project Planning & Research - Finalize project scope and objectives, including the extended goal. |
| Week 2-3 | Development Setup - Setup test for the new LastFM importer. - Research and verify LastFM APIs’ query and data format. |
| Week 4-5 | Importer Development - Implement logic for fetching scrobbles from LastFM API. - Develop algorithms for parsing and validating scrobble data. - Integrate and streamline both parts into one. |
| Week 6-7 | UI and API Development - Modify the existing UI for editing the connected LastFM username. - Modify the backend API to save / remove records in external_services_oauth table. - Integrate frontend and backend. |
| Week 8 | Async Import API Development (experimental) - Implement an API endpoint for importing scrobbles asynchronously for the frontend. - Implement queueing and processing logic with RabbitMQ and Redis. - Test API functionality and integration with the frontend page. |
| Week 9-10 | Testing and Optimization - Conduct thorough testing for the importer and the Web API. - Identify bugs and optimize the performance for efficiency. |
| Week 11 | Documentation & Deployment - Document codebase and deployment instructions. - Deploy the new importers and Web API to the production environment. |
| Week 12 | If there are no remaining tasks to do, I will work on integrating more importer services. |
About Yourself
Why me?
I am confident that my experience in different roles speaks loud for my skills for the task. I was an active participant in Web3 hackathons, where I was one of the core contributors to the code base. During those hackathons, I was able to learn the tool sets from sponsoring companies quickly and made tailored integrations to our unique solutions in a short time. It also taught me the importance of teamwork.
From my experience in working on the DeFi project, I started as a front-end developer and advanced steadily to the role of a project manager. Beyond ensuring code functionality, my additional responsibilities involved conducting code reviews, managing pull requests, and interacting with stakeholders. This includes understanding their requirements, negotiating and explaining technical concepts in simple terms. Developing strong interpersonal skills was crucial for ensuring team and client satisfaction. I truly value this experience that shaped me into a more well-rounded individual.
ListenBrainz aims to host a free, public store of users’ listening history, and provide an open-source recommendation engine and ways to share. I’m excited to join the team to shape the future of open music history stores and am looking forward to learning from and contributing to the ListenBrainz community.
Why Metabrainz?
I was drawn to the project due to a few reasons.
Firstly, I was attracted by the functionality of the product - ListenBrainz. It helps me to aggregate my listening data from various platforms, and produce useful analysis. Countless times I was troubled by the closed system of streaming services, where my listening history was trapped inside and no way to be unified. ListenBrainz solves this challenge, and it is better than what I want.
Moreover, it is a huge web project with big data processing technologies like Spark and Redis, it is technically cool too! No programmer can say no to cool architectures and technologies. On the other hand, are the passionate and kind people I met on the IRC channel. They are talented, yet very kind to help out new members. I was very surprised that core members of the team treated my newbie question very seriously and promptly replied with suggestions. I feel that it would be very nice and full of joy to work with these kind people.
Lastly, I’m very motivated to work on the project also because I can see my skills and knowledge can be applied to the enhancement of the product. For example, having a dark mode and other options for improved accessibility, supporting internationalization and language-based categorization of music boards. I’m comfortable working with Python and React. With my experience learning from open-source software for sensor data and VR streaming, I became more comfortable reading docs and codes written by others.
My PRs
I may be new to the party, but I am eager to hit the ground running, collaborate closely with the team, and contribute my skills and ideas to help achieve our shared objectives.
Submitted:
LB-476 Use https on demos when endpoint is api.listenbrainz.org
LB-1550 Inconsistent status between brainzPlayer and the Youtube widget
LB-620: Document way to run specific integration tests
Docs: Add windows docker installation instruction
Working on:
LB-770 Inform users when statistics are generated
Tell us about the computer(s) you have available for working on your SoC project!
I will be using a Lenovo XiaoXin CHAO 7000 laptop with Intel i5-8250U CPU, and 16GB RAM. I have previously used this PC for submitting some of the PRs and for developing other DeFi projects and participating in hackathons.
When did you first start programming?
I became interested in building projects for the community in 12th grade. When I decided to sell my textbooks to juniors after high school graduation, I taught myself HTML, CSS, and PHP to create a system for this purpose. It included database CRUD and webpage access controls. I also spent time carefully tuning the CSS styles for the website. From there, I learned that there are plenty of learning opportunities on the internet. It is a place to learn, hone skills, and contribute.
What type of music do you listen to? (please list a series of MBIDs as examples)
I’m a fan of Maroon 5, Owl City, and some Chinese singers like Jay Chow. I’m also a big fan of video game OSTs and anime songs. When it comes to games, I enjoy music pieces from Wii Sports and “Super Mario and Galaxy” as they evoke a sense of adventure and serenity. As for anime music, I listen to tracks like “Unravel” (Tokyo Ghoul), “This Game” (No Game No Life), “Blue Bird” (Naruto), and all Ghibli songs.
I’m really excited about the prospect of meeting like-minded people on ListenBrainz!
Pop Music
Maroon 5, Payphone: bcd54ab6-9552-44cd-a09d-d46a8a374c35
Owl City, To The Sky: cc145d3b-fc0e-4c4f-afe1-7135bf5e9df2
Jay Chow, Qi Li Xiang: bf546753-256b-43cb-9310-e78d5b341075
Game OSTs
Koji Kondo, Rosalina in the Observatory 1: a319fa70-7614-44be-a14b-7260bd133ce7
Anime songs
Animenz, Blue Bird: d35339be-6f88-4087-bd95-060b88df7348
Joe Hisaishi, My Neighbor Totoro: a9a9f2f9-e562-4c49-9316-b67c44f17e1c
What aspects of MusicBrainz/ListenBrainz/BookBrainz/Picard interest you the most?
What I appreciate most about ListenBrainz is the openness of its system. Most media streaming services collect users’ data and analyze them extensively, but they rarely disclose their processes. Users are often left in the dark about what’s happening behind the scenes. Having participated in the Web3 project developments, I have a deep admiration for projects that are open and inclusive. I’m particularly impressed by the intricacy of ListenBrainz’s statistics and recommendation system, and I can’t wait to be a part of it.
Have you ever used MusicBrainz Picard to tag your files or used any of our projects in the past?
I often collect music on my hard drive and transfer them to mobile devices. However, the music files often have inconsistent naming and missing metadata. Picard’s Lookup and Scan feature have been powerful and easy-to-use to assist with annotation, saving me lots of time!
On the other hand, I’ve discovered that MusicBrainz’s database is an excellent resource to find music that is otherwise hard to come by (such as game OSTs). I truly appreciate the hard work you all have put into this project.
Have you contributed to other Open Source projects? If so, which projects and can we see some of your code?
I am one of the core contributors to OpenZen, an open-source C++ sensor library for sensors from LP Research. I worked on feature implementation, bug fixes, and binding releases. Additionally, I upgraded the Sphinx documentation into Confluence pages, reorganizing the content to improve the onboarding experience for new users.
On my personal page, there are also links to my personal projects and code repositories.
What sorts of programming projects have you done on your own time?
I participated in blockchain hackathons such as ETHNYC and ETHOnline in 2022, and ETHTokyo in 2023. At ETHOnline, I collaborated with a team of 5 to develop a decentralized chat application at ETHOnline which secured the first prize from XMTP. I led the solution design efforts in the other two competitions, contributing to projects such as an efficient lending protocol, and an on-chain gated BBS.
Additionally, I worked on several smaller personal projects, including real-time arbitrage automation scripts, a performant real-time scatter plotter, and a pipeline to decode satellite signals. These diverse projects have sharpened my practical skills and deepened my understanding across various domains.
How much time do you have available, and how would you plan to use it?
Currently, I allocate 1-2 hours/day for contributions. In the Summer, I anticipate having more time available since I do not plan to work or study, allowing me to dedicate up to 6-7 hours/day.