Personal Information
Name: Ashutosh Aswal
IRC nick: yellowhatpro
Email: [redacted]
GitHub: yellowhatpro
Time Zone: UTC+05:30
Internet Archive integration: saving external URLs via Wayback Machine
Proposed mentors: bitmap , yvanzo
Estimated time: 350 hours
Tech Stack used: Rust
Project Overview
MusicBrainz database sees a lot of edits made on a daily basis. Tens of thousands of edits. That’s a large number. With each edit, there’s associated an edit note which provides additional information about the edit. Often, these edit notes, as well as some edits, contain external links, which we want to archive in Internet Archive.
This project idea aims at creating a rust application, that can archive the external URLs using Wayback Machine APIs.
My contributions up till now:
The task in hand requires rust bindings of the musicbrainz database. For this purpose, there’s a library sql-gen available, that can generate rust bindings for a given database schema. But the library was not compatible with the musicbrainz schema, so it required some fixes. With the library working, we are able to build a binary, which can generate all the rust types and important queries to work with the database.
The generated bindings are currently available in a GitHub repository, which we can use for the rust app we are going to build. At the moment, they have successfully compiled, but there might be runtime issues, so we can fix them as we proceed with the application development.
Implementation
Our main focus is to come up with an application that can take edits and edit notes from database, extract URLs from them, and save them using Wayback Machine APIs. This is the abstract idea, here’s how we are going to do them.
1. Making the sql-gen library working
The sql-gen library is a great tool to generate rust types for postgres databases schemas. It uses sqlx crate under the hood, which is a really nice tool for writing SQL queries. The problem with sql-gen is, it does not very well map with Postgres types, which caused a lot of errors in generating the rust entities. sql-gen also panicked on custom musicbrainz types, like edit_note_status, fluency, cover_art_presence, etc. As a fix, respective rust enums were added.
This is the mapping functions that maps Postgres types to sqlx compliant rust types:
pub fn convert_data_type(data_type: &str) -> &str {
match data_type {
"_int8" => "i64",
"_int4" => "i32",
"_int2" => "i16",
"_text" => "String",
"jsonb" => "serde_json::Value",
"time" => "chrono::NaiveTime",
"bool" => "bool",
"bpchar" => "String",
"char" => "String",
"character" => "String",
"edit_note_status" => "EditNoteStatus",
"fluency" => "Fluency",
"oauth_code_challenge_method" => "OauthCodeChallengeMethod",
"taggable_entity_type" => "TaggableEntityType",
"ratable_entity_type" => "RatableEntityType",
"event_art_presence" => "EventArtPresence",
"cover_art_presence" => "CoverArtPresence",
}
}
With these fixes, sql-gen can now read the database tables, and would not panic while generation process. The resultant code had some shortcomings too, which now have been fixed.
All these fixes and more can be seen here.
2. Generating rust types and functions for the database using sql-gen
With sql-gen working, one can generate bindings using this command:
sql-gen generate --database postgres://musicbrainz:musicbrainz@localhost:5432/musicbrainz_db --output ./schema --schema musicbrainz
sql-gen generates rust types for the database schema, and is capable of generating helper functions for various database queries, like: SELECT, SELECT by primary key, SELECT by foreign key, INSERT, UPDATE and DELETE statements.
For more complex queries, we can use the sqlx crate to write raw SQL queries.
3. Look for URL-containing data in the database
Ok, so till now we have with ourselves the rust generated bindings to interact with the tables. But where are the URLs located?
Let’s begin with the Edit Note.
This is how edit note looks like in the website:
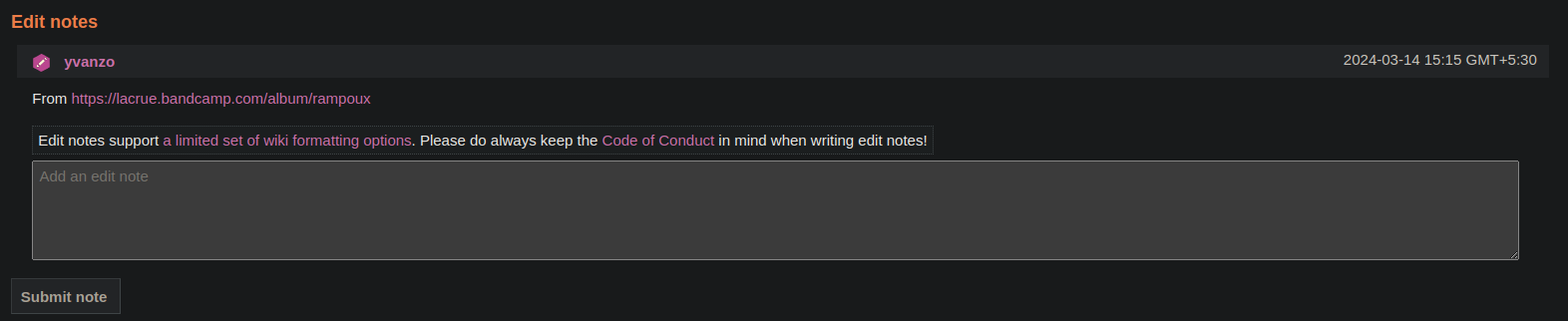
This is how URL is stored in the edit_note table:

As we can see, the edit note has a column text, where we can find the URL.
For edits, there are multiple type of edits, but there are only few we want for our use case. For example: Add Relationship:
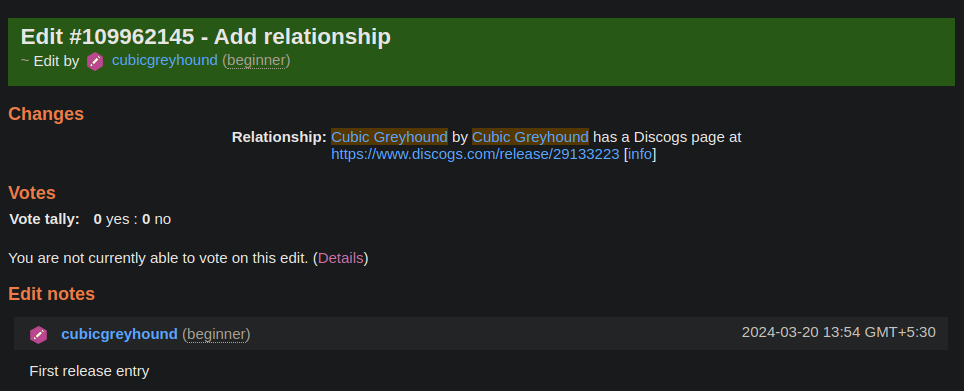
And the representation in edit_data table :

For edits, The data column stores the JSON formatted data. For Edit Type 90 (Add relationship), we can see there’s a type0 → type1 mapping of release → url, and the entity1 key gives us the object, which contains the URL we want to archive.
There are other types as well, which we can use, like Edit Type 101 (Edit URL):
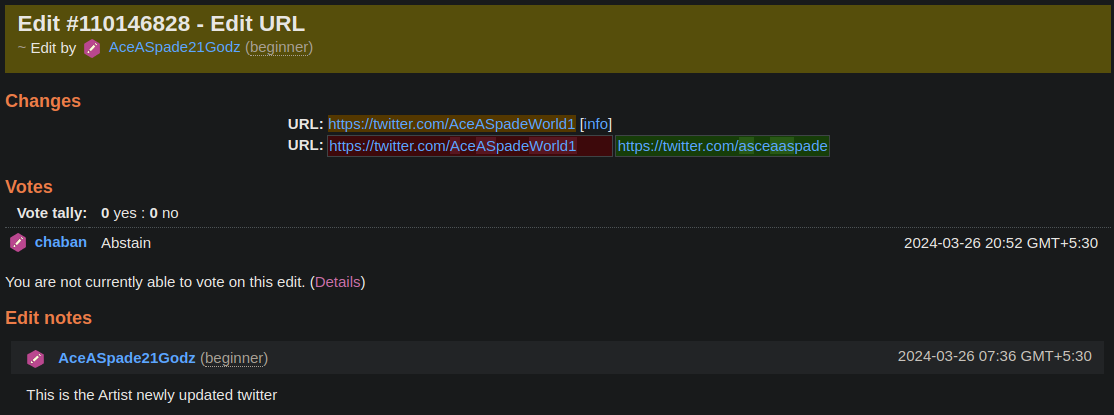
The JSON representation is:
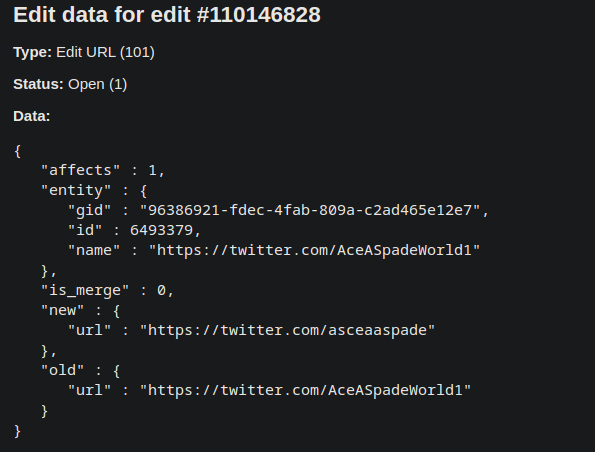
Other Edit Types which may contain external URLs are Add Artist Annotation, Edit Relationship .
Now that we know “where” to look for the URLs, we have to figure out “how” we will extract them.
4. Poll database tables to fetch URL-containing rows
To be able to make queries from the tables, we would have to interact with the database first. Having multiple ways to interact the database, the preferred and easier solution, which I found on discussion in IRC is polling, because of its simplicity and chances of idle polling being low because of number of edits made every day. On each poll, we can call a Postgres function from our rust app, which will DECLARE a cursor, OPEN it, FETCH the rows, and CLOSE the cursor. We can keep the track of the last processed row, and pass its id to the cursor query, so we can skip the previously processed rows.
Polling code will look something like this:
#[tokio::main]
async fn main() {
let db_url = "postgres://musicbrainz:musicbrainz@localhost:5432";
let pool = PgPoolOptions::new()
.max_connections(5)
.connect(&db_url)
.await
.unwrap();
tokio::spawn(async move {
poll(pool.clone()).await;
});
}
async fn poll(pool: sqlx::PgPool) {
// Duration can be configurable
let mut interval = interval(Duration::from_secs(10));
loop {
interval.tick().await;
if let Err(e) = poll_task(&pool).await {
eprintln!("Error polling database: {}", e);
//Do something about the task
}
}
}
async fn poll_task(pool: &sqlx::PgPool) -> Result<(), sqlx::Error> {
let urls = run_sql_queries_and_transform(pool);
store_urls(urls);
Ok(())
}
5. Transformations(URL Containing rows) → List of URLs
The data that we get from SQL queries is different for different tables. We can’t just store them right away.
For example, here is edit_note.rs:
use crate::schema::types::*;
#[derive(sqlx::FromRow, Debug)]
pub struct EditNote {
pub id: i32,
pub editor: i32,
pub edit: i32,
pub text: String,
pub post_time: Option<chrono::DateTime<chrono::Utc>>,
}
and edit_data.rs:
use crate::schema::types::*;
#[derive(sqlx::FromRow, Debug)]
pub struct EditData {
pub edit: i32,
pub data: serde_json::Value,
}
Once we have our results stored in the rust structs, we can start our operations to extract URLs from them. As we have seen earlier, the edit note can contain text other than URL, or there can be multiple URLs, and the URL in edit_data is also nested inside the JSON somewhere. We will have to perform operations in order to get the desired outcomes, that is, a list of URLs.
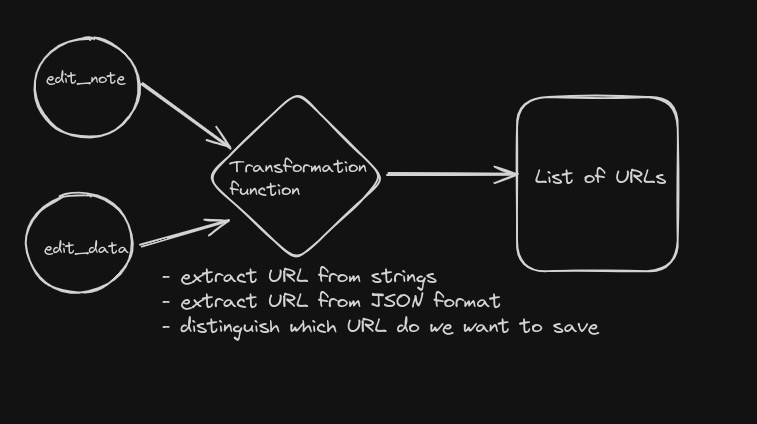
Once we have the list of URLs with us, we will save them in a new table.
6. Storing URLs in a new table
Now we have data to use, but we can’t use that yet. With the rate at which edits and edit notes are made, and the limitations of the rate limited API endpoint, it makes sense to use a buffer storage, where we can keep the URLs.
create table internet_archive_urls(
id serial,
url text,
job_id text, -- response returned when we make the URL save request
from_table varchar, -- table from where URL is taken
from_table_id integer, -- id of the row from where the URL is taken
created_at timestamp with time zone default now(),
retry_count integer, -- keeps track of number of retries made for the URL
is_saved boolean);
This can be a good schema for the table to start with.
One thing that we want to make sure is that we don’t save a URL again the same day, so, before saving any URL to the table, we can check if there exists any row with same URL, but with created_at timestamp difference of less than 24 hours, and discard any duplicate .
Whenever we confirm a URL has been saved by the API, we will also mark the is_saved value to true. The is_saved value can be helpful for cases when for any reason, the URL did not save, and we want to retry saving it.
7. NOTIFY listeners periodically
Now comes the interesting part, sending data to the URL-archiving code. For this purpose, we will employ a NOTIFY command. The NOTIFY command will periodically run after a duration of x seconds, since the task we want to do at the LISTENER’s end is rate limited.
...
let notify_pool = pool.clone();
//another async task
let _t = tokio::spawn(async move {
// The duration can be configurable
let mut interval = tokio::time::interval(Duration::from_secs(10));
while !notify_pool.is_closed() {
interval.tick().await;
notify(¬ify_pool).await;
}
});
...
async fn notify(pool: &sqlx::PgPool){
batch_rows_from_table_and_send_through_a_channel(pool);
}
We will use the pg_notify(channel, payload) method to send the batched URLs to the listener, where we can make our final API calls.
The pg_notify function in Postgres generates a notification event. The function takes two arguments: the channel name as the first argument and the payload as the second.
The idea to use an asynchronous message passing approach here is so that the URL-saving/archiving task does not have to know about the concurrent tasks that will execute it, and thus decoupling them.
In our case, there are 2 concurrent tasks that would need to save the URLs (The main task polling batches of URLs, and the check_and_retry task which will check the is_saved and job_id status of URLs, and will try to retry saving any unsaved ones). Since both these tasks run concurrently, and are important for the execution of the app, we need a mechanism for them to communicate with the URL-saving task.
For these types of cases, we either have shared memory, or message passing solutions, but I think for our case, the message passing solution, which requires a channel to be created, sounds a better option. We can also do message passing using rust’s
std::sync::mpsc module, which uses send/recv methods, but since we are dealing with postgres, I think using sqlx-postgres module for this is a better option, although they both do the same job, and are more secure than creating Mutexes or Arcs.
8. Catching the payload at LISTENER’s end
The moment the NOTIFY command runs, if the listener is on the same channel, will get the payload from the channel.
For this purpose, we can use sqlx-postgres PgListener struct.
This listener will be listening the channel, and with the help of recv() method, we can get the payload sent by the notifier.
let mut listener = PgListener::connect_with(&pool).await?;
println!("Start listen loop");
listener.listen("channel_name").await?;
loop {
let notification = listener.recv().await.unwrap();
println!("{}", notification.payload());
}
Now, we have a continuous supply of URLs, coming at us every x seconds (x here is the notify delay we introduced). Now, finally, we can make the API calls.
9. Saving the URLs using the Wayback Machine APIs
Now we can begin saving our URLs, but we have to be careful, we can’t cross the rate limit.
This is the API we will be interacting with:

Since there is rate limiting associated, we need to self rate limit our requests.
![]()
The rate limit of the API is of the type M requests per N seconds (12 req / 60 seconds), therefore we can have an M cyclic queue based approach, where a queue holds M queues, and ensures M queues can fire AT MOST M request during the time window N. This is the proposed idea, but we will have to play around with the rate limiting parameters, as it’s challenging to know at an early stage what configuration will work.
Anyway, this particular IA interacting logic can also be decoupled from the rest of the code, as we can extend its use case for more tasks, such as re-archiving links which can be changed later by artists, like Spotify, iTunes, which also need to be rate-limited.
After we make the API call, we get a response containing a job_id, which we can store in our internet_archive_urls table, and whose status can be checked using the following API:

This too is rate limited. So we will have to be careful with this as well, or we do have an option to use this API, which checks the archival status using the URL:
curl -X GET "https://archive.org/wayback/available?url=<url>".
10. Check_and_retry and Cleanup Task
There are fair chances that the URL we wanted to save, could not get saved, which could be due to errors like internal-server-error, browsing-timeout, bandwidth-limit-exceeded. To retry saving such URLs, and checking the saved ones, we can run another async task periodically, which will check if the URL got saved or not.
We have a job_id associated with each URL we tried saving, we will use this job_id to check the status of the URL being saved or not in the check_and_retry task.
Once we know our URL is saved, we can mark its is_saved value true in the internet_archive_urls table. If it still does not get saved, we will increase the retry_count. Retry count is necessary to limit the number of attempts.
There will also be an independently running cleanup task, which will check for the rows that we can delete. We can consider created_at and is_saved fields to delete the rows. Since we don’t want our internet_archive_urls to grow indefinitely, we will have to do this cleanup task at some time intervals.
Timeline
Following is the timeline for the 350 hours of GSoC coding period I’ll be devoted to:
Community Bonding Period (May 01 - May 26)
- Discuss various engineering aspects with the mentors, including listen/notify mechanism, polling, rate limiting, error handling in different corner cases.
- Study and understand Postgres functions, and the engineering tasks I’d be dealing with.
Week 1 (May 27 - June 2)
- Set up the project environment by writing
Dockerfile, the compose file, and set up the rust app, which can make the APIreqwestcalls, poll database, listen/notify the new table asynchronously, retry saving unsaved URLs, and cleanup theinternet_archive_urlstable. - This week’s objective would be to come up with a small, workable app, which can perform the above-mentioned tasks.
- The polling and listen/notify mechanisms will be tested individually, with some example queries, which need not be final queries.
Week 2 (June 3 - June 9)
- Discuss and implement database queries and constraints, like creating the query to poll the
edit_note, andedit_datatables, batch the results, and make sure the next poll starts after the last accessed row. - Write query that’ll run on retry saving URLs and on cleanup of
internet_archive_urlstable. - Also write the query to run when we
NOTIFYtheinternet_archive_urlstable. - The objective of this week would be to come up with SQL queries that are needed across the application.
Week 3 (June 10 - June 16)
- Work on the transformation logic to convert
EditDataandEditNoteto plain URL. - Transformations will include checking the right URL, domain ignoring for certain URLs, removing any not required text, reading URL from the JSON.
Week 4 (June 17 - June 23)
- Work on polling logic.
- Integrate the SQL query to the polling logic, ensure it’s working correctly, and check if we are able to get the list of URLs after the transformation function.
- Any error handling, and testing for this, will also be done in this week.
Week 5 (June 24 - June 30)
- Once we get the results in the form of URLs, we will save the URLs to the
internet_archive_urlstable usingsqlx. - Work on the
NOTIFYmethod, and integrate the SQL query we will run on each notify. - Test and ensure batches of URLs are being sent through
NOTIFYin the channel.
Week 6 (July 1 - July 7)
- Work on the
LISTENlogic usingPgListener. - On each
LISTEN, we will get URLs, which we want to archive, therefore start the work on the rate limiting queue implementation, that enqueues URLs, and makes API call with necessary delay.
Week 7 (July 8 - July 14)
- Continue my work on the rate limited queue, and test locally if it’s working, and look for any optimizations that can be made.
- Work on the retry/fallback logic, if the API response is not OK.
Week 8 (July 15 - July 21)
- Work on analytics and monitoring of the app.
- This will include integrating analytics tools, like sentry for issues tracking, and Prometheus for monitoring.
- Add their crates to the project, and write their configs, and ensure the metrics are being collected alright.
Week 9 (July 22 - July 28)
- This week is kept as a buffer.
- Any notorious issue/shortcoming will be fixed in this week, and will make sure if the app is working correctly.
Week 10 (July 29 - August 4)
- This week will involve deploying the container to the appropriate registry, and automating the process of deploying the container app.
- Write workflows for CI CD.
- Fix any post-deployment bugs.
Week 11/12 (August 5 - August 18)
- Monitor the app in production, and fix production errors.
- Publishing the rust binding crate to crates.io .
- Start working on other IE integration aspects.
Stretch goals (August 19 onwards )
- If we don’t run into unexpected error, my task in hand will be to work on 2 more IA integrations:
- Re-archiving links which can be changed later by artists, like Spotify, iTunes.
- MusicBrainz DB Dumps automation.
Detailed Information About Yourself
My name is Ashutosh Aswal. I am a senior pursuing Bachelors in CSE from Punjab Engineering College, Chandigarh, India. Having contributed to android projects before in MetaBrainz, now I want to explore new domains of tech and gain hands-on experience.
Tell us about the computer(s) you have available for working on your SoC project!
I have my HP Pavilion ec0101ax running Arch Linux, with Ryzen 5 3550H and 24 gigs of RAM.
When did you first start programming?
I began my programming journey with C++ in 11th grade.
What type of music do you listen to? (Please list a series of MBIDs as examples.)
I mostly listen to Indie music artists like The Local Train, Nikhil D’Souza, Anuj Jain etc.
What aspects of the project you’re applying for interest you the most?
I like exploring new tools and languages in my free time. In recent times, I started exploring rust, and wanted to build some stuff with it. Other than that, I like how this particular project is introducing different software engineering concepts which I have only read about, and would get a change to implement them.
Have you ever used MusicBrainz to tag your files?
Yes, I have.
Have you contributed to other Open Source projects? If so, which projects and can we see some of your code?
I have earlier contributed to the Metabrainz android projects, musicbrainz-android, and listenbrainz-android.
Here are my contributions to musicbrainz-android and listenbrainz-android.
What sorts of programming projects have you done on your own time?
I have prior experience in android development, and in my free time, I love to explore different tech stacks and frameworks.
- i-remember: A CLI tool in rust to save shell commands, batch them, and reuse them. (WIP)
- codes-practice : A React app to show my code solutions to various algorithmic problems, and competitive programming problems.
- Apart from them, I have many undeployed, half-baked, good-for-nothing projects I cook in free time, that you can see on my GitHub or Portfolio.

How much time do you have available, and how would you plan to use it?
I will be working ~30 hours per week on the project.