[GSoC 2024] Exporting and Importing Playlists Between SoundCloud and Apple Music
Personal Information
Name: Rimma Kubanova
Email Address: [redacted]
Github: kub.rimskii
Location: Kazakhstan, Astana
Time Zone: GMT+5
University: Nazarbayev University
Degree: Computer Science (Bachelor of Engineering)
Year of Study: 2
Introduction
Hi, I’m Rimma, also known as ‘kubrimskii’ on IRC! I’m a sophomore at Nazarbayev University in Astana, Kazakhstan, a Full-Stack Developer with keen love for design . Currently, I serve as the vice-president of the ACM Student Chapter, where I dedicate the majority of my time to organizing hackathons and coding competitions for 300+ participants. Recently, I’ve delved into the world of open-source, with MetaBrainz being the first organization where I’ve made significant contributions and honed my skills! I’ve discovered that I actually love it. On top of that, I’m a huge anime/film fan and enjoy drawing in my free time.
Why me?
I firmly believe that I possess the necessary skills to excel in this role. My experience as vice-president has allowed me to refine my teamwork abilities and take on significant responsibilities. Additionally, I have past experience working as a Back-end Developer for a startup, primarily using Django/Python. I’ve also worked with embedded systems for research in IoT labs and participated in the Google Solutions challenge.
When I began contributing to LB, I lacked strong experience in both back-end and front-end development. However, over the past three months, while working on contributing to LB,I’ve immersed myself in learning, gaining proficiency in Docker, databases, API endpoints, and even UI design aspects. I’ve already become familiar with the LB-server codebase, which enables me to navigate it efficiently. Moreover, I’ve tackled substantial features that align with my proposal.
Through consistent commits and the invaluable mentorship of Aerozol, Monkey, and Lucifer, I’ve learned a great deal about contributing to large organizations. I’ve integrated myself into this team of talented developers and am eager to continue working alongside them.
Why Metabrainz?
To be honest, I stumbled upon MetaBrainz, particularly ListenBrainz, while browsing through websites for ‘first-time contributors.’ Fortunately, I discovered that MetaBrainz also participates in GSoC. I chose ListenBrainz because I found that my skills align best with its projects, and since it’s related to music (which I love), it seemed like the perfect fit.
As I delved deeper, I grew fond of the idea behind ListenBrainz, which helps track listening history (I was surprised to find out I listen to around 150 songs per day—that’s a lot!). I’m particularly excited about Troi - a cool recommendation system. In fact, I’ve even developed my own app that can transfer YouTube songs to Spotify because, in my opinion, Spotify’s recommendation system leaves much to be desired.
Project Overview
Listenbrainz gives a perfect opportunity to build your own playlist using find suggesiton, recommendations systems. Wouldnt be it cool to tranfer these playlist to other music services too? Currently, LB support exporting playlists to Spotify, but wouldnt be it wonderful to enable the same for other servies like Apple Music and SoundCloud. Also, it could be even better if we could automatically import the playlists from these music services to LB. The aim of this project is to achieve it.
My PRs: Check it out!
(Note: The project idea contained only feature to export to Apple Music and SoundCloud, but it was my desire to add more features and also enable importing feature)
Goals
- Integrate playlist exporting functions with Apple Music.
- Integrate playlist exporting functions with SoundCloud.
- Implement playlist importing from popular music services such as Spotify, Apple Music, and SoundCloud.
- Integrate the export/import functions into Troi to enable usage for both ListenBrainz and Troi patching.
Implementation
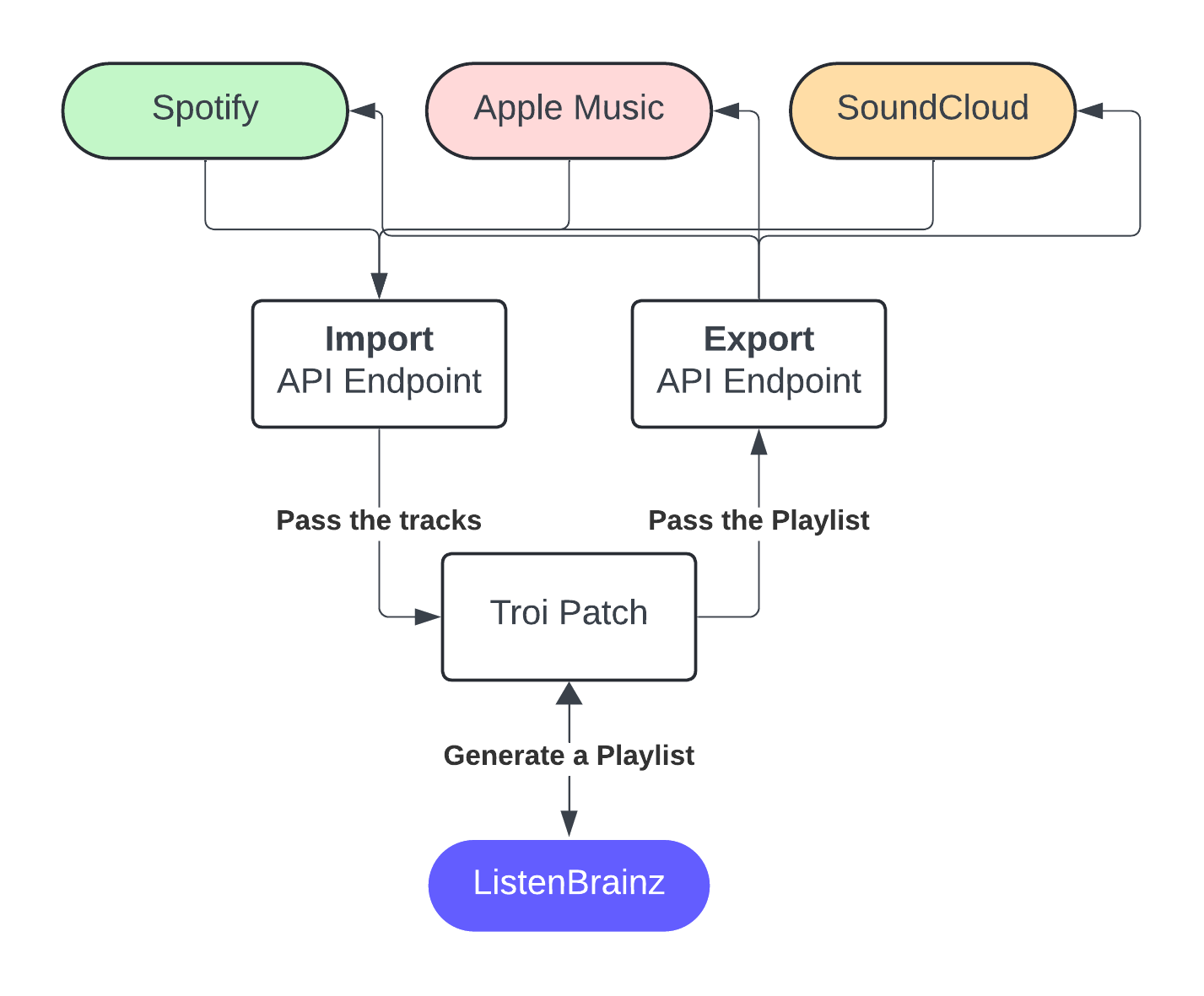
The Import/Export Functions will be implemented in the Troi patch folder (as suggested by @lucifer), as they can be further utilized for Troi functions. First, I plan to implement the main import feature directly in troi itself, so it can be used by troi patch in the future. For export feature, it is not needed, as it is already was implemented. Then, I will create two files: import.py and export.py, that will call this functions for all music services.
Here’s a quick diagram showing how the implementation would work. The import/export will use the APIs of Listenbrainz and external music services to send/get data and Troi Patch to generate a playlist.
Export - Backend
It is a good practice to implement export functions on the backend, since it is faster and provides a more clean code. The following implementation is based on already existing function that exports playlists to Spotify. My goal here is to modify it, and make more flexible for other music services too:
- Export a playlist to an external service using its playlist MBID.
a. Include parameters for exporting to Spotify (user_id, token, is_public, is_collaborative).
I intend to modify this function to accept various options for exporting (such as SoundCloud or Apple Music). The updated export_to_spotify function will be capable of handling different music service options and parsing parameters accordingly.
def export_to_spotify(spotify_token, is_public):
# check if user is authenticated using spotify
sp = spotipy.Spotify(auth=spotify_token)
spotify_user_id = sp.current_user()["id"]
args = {
"user_id": spotify_user_id,
"token": spotify_token,
"is_public": is_public,
"is_collaborative": False
}
return args
def export_to_apple_music(is_public):
#Apple Music JWT token needs to be generated to use Apple Music API
apple_token = generate_developer_token()
args = {
"token": apple_token,
"is_public": is_public,
}
return args
def export_to_soundcloud(is_public):
# get_current_coundcloud_user - returns the soundcloud access token for the current authenticated user. It also automatically checks if user is authenticated
soundcloud_token = get_current_soundcloud_user()
args = {
"token": soundcloud_token,
"sharing": is_public,
}
return args
def export_to_music_services(music_service, lb_token, access_token, is_public, playlist_mbid=None, jspf=None):
# when calling this function, it will be specified by music-service parameter which service to import to. Based on that parameters specific to these music services will be provided
if music_service == "spotify":
params = export_to_spotify(access_token, is_public)
elif music_service == "apple_music":
params = export_to_apple_music(is_public)
elif music_service == "soundcloud":
params = export_to_soundcloud(access_token, is_public)
else:
raise ValueError("Unsupported music service: {}".format(music_service))
args = {
"mbid": playlist_mbid,
"jspf": jspf,
"read_only_token": lb_token,
music_service: params,
"upload": True,
"echo": False,
"min_recordings": 1
}
playlist = generate_playlist(TransferPlaylistPatch(), args)
metadata = playlist.playlists[0].additional_metadata
return metadata["external_urls"][music_service]
-
Generate a playlist using a Troi patch playlist generator using TransferPlaylistPatch patch. It retrieves an existing playlist from LB.
-
Provide a Spotify user_id and auth token, upload the playlists generated in the current element to Spotify and return the URLs of the submitted playlists.
if result is not None and spotify and upload: for url, _ in playlist.submit_to_spotify( spotify["user_id"], spotify["token"], spotify["is_public"], spotify["is_collaborative"], spotify.get("existing_urls", []) ):- For a list of Recording elements,try to retrieve Spotify track_ids from the Labs API spotify-id-from-mbid, fix some tracks(if they were not found) and add them to the recordings.
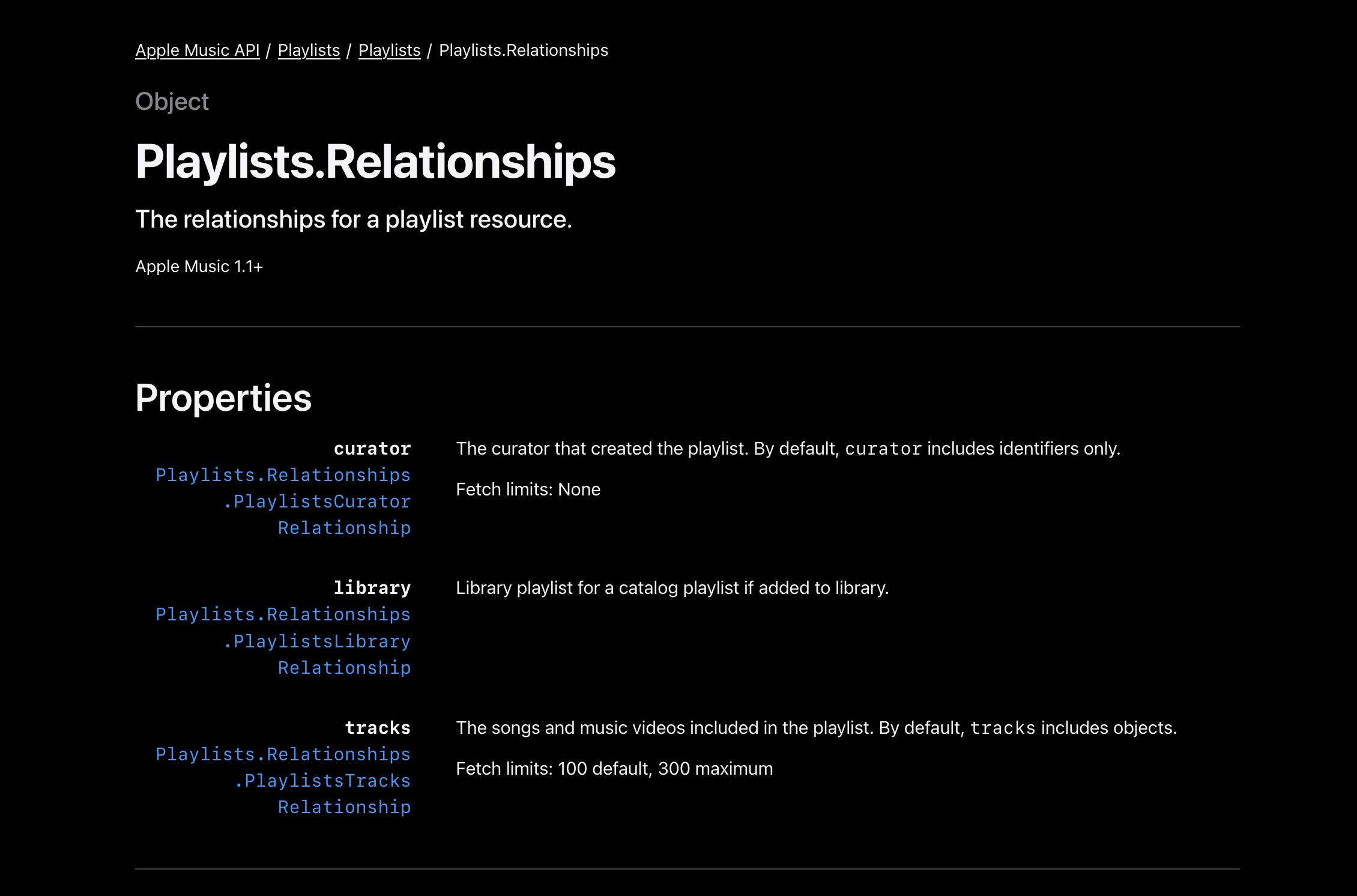
For Spotify, there exists a data set hoster API “https://labs.api.listenbrainz.org/spotify-id-from-mbid” that can be used to lookup for spotify track_ids by MBID. However, currently, it only supports Spotify. Therefore, we need to add more endpoints for other services. As suggested by @lucifer, there is data available for the Apple Music tracks that we can utilize for lookup. Here is the pseudocode for it:
The implementation would be located in “/labs_api/labs/api/” in a separate folder “apple”. I believe it is better to store in a separate folder as a class, instead of mixing with Spotify class (SpotifyIdFromMBIDQuery).
The endpoint: Dataset hoster: apple-music-id-from-mbid
def perform_lookup(column, metadata, generate_lookup): """ Given the lookup type and a function to generate to the lookup text, query database for spotify track ids """ if not metadata: return metadata, {} lookups = [] for idx, item in metadata.items(): text = generate_lookup(item) lookup = unidecode(re.sub(r'[^\w]+', '', text).lower()) lookups.append((idx, lookup)) index = query_combined_lookup(column, lookups) remaining_items = {} for idx, item in metadata.items(): apple_ids = index.get(idx) if apple_ids: metadata[idx]["apple_music_id"] = apple_ids else: remaining_items[idx] = item return metadata, remaining_itemsdef lookup_using_metadata(params: list[dict]): """ Given a list of dicts each having artist name, release name and track name, attempt to find apple music track id for each. """ all_metadata, metadata = {}, {} for idx, item in enumerate(params): all_metadata[idx] = item if "artist_name" in item and "track_name" in item: metadata[idx] = item # first attempt matching on artist, track and release followed by trying various detunings for unmatched recordings _, remaining_items = perform_lookup(LookupType.ALL, metadata, combined_all) _, remaining_items = perform_lookup(LookupType.ALL, remaining_items, combined_all_detuned) _, remaining_items = perform_lookup(LookupType.WITHOUT_ALBUM, remaining_items, combined_without_album) _, remaining_items = perform_lookup(LookupType.WITHOUT_ALBUM, remaining_items, combined_without_album_detuned) # to the still unmatched recordings, add null value so that each item has in the response has spotify_track_id key for item in all_metadata.values(): if "apple_track_ids" not in item: item["apple_track_ids"] = [] return list(all_metadata.values())Unfortunately, there isn’t enough data available to look up SoundCloud track IDs. Therefore, I am considering two approaches to solve this issue:
- Utilize the SoundCloud API search endpoint: https://api.soundcloud.com/tracks?q=hello&ids=1,2,3&genres=Pop,House&access=playable&limit=3&linked_partitioning=true. This endpoint not only accepts track names but also genres and tags, which can help fetch more accurate tracks. However, it may not be the most optimal solution and might still fetch incorrect tracks.
- Generate SoundCloud data to work with: This approach requires more effort but is highly rewarding. The generated data can be used for other operations as well and is highly optimal.
If the first option chosen, it does not require an additional functions for lookups and can be done separately. Unfortunately, it restricts troi patch from using SoundCloud data for its functions.
-
If playlist already exists, update, if not, create a new playlist.
-
For Spotify, creating playlist and adding items to it were done using a spotipy library. However, for Apple Music and SoundCloud it should be done manually. Here is the Pseudocode:
data = { "attributes": { "name": playlist.name, "public": is_public, "description": playlist.description } } # Make the POST request to create the MusicKit playlist url = "https://api.music.apple.com/v1/me/library/playlists" response = requests.post(url, headers=headers, data=json.dumps(data)) add_items_url = " https://api.music.apple.com/v1/me/library/playlists/{playlist_id}/tracks" # if there is tracks, add them to the playlist (track_id, track_type) if len(apple_track_ids != 0): for track in apple_track_ids: data["track"].append({ identifier: track.id, type: track.type, }) response = requests.post(url, headers=headers, data=json.dumps(data) -
For SoundCloud:
import requests headers = { "Authorization": "OAuth " + access_token, "Content-Type": "application/json" } tracks = [] for track_id in soundcloud_track_ids: tracks.append({ "id": track.id }) playlist_data = { "playlist": { "title": playlist.name, "description": playlist.description "sharing": is_public? "public" : "private" "tracks": tracks } } # Make the POST request to create the playlist with tracks url = "https://api.soundcloud.com/playlists/" response = requests.post(url, headers={ "Authorization": "OAuth " + access_token, "Content-Type": "application/json" } ,json=playlist_data)
-
-
As it was done, notify User about successfull export of a playlist using a Toast Message and provide a link to it.
Export - Frontend
There will be no significant changes on the frontend. I plan to modify “Export to Spotify” button, so it will open a new modal, where user can select a music service they want to export to. Then,
a modified exportToSpotify function will call APIService. exportPlaylistToSpotify and provide an another parameter - music_service (Music Service Name). Depending on that, the backend will handle the rest as it was discussed earlier. The UI Mockups for these functions will be provided below.
// exportToMusicServices instead of exportToSpotify
const exportToMusicServices = async (music_service: string) => {
if (!auth_token) {
alertMustBeLoggedIn();
return;
}
let result;
if (playlistID) {
//APIService handles all API requests. exportPlaylistToMusicServices will call export function executed on the backend
result = await APIService.exportPlaylistToMusicServices(auth_token, playlistID);
} else {
result = await APIService.exportJSPFPlaylistToMusicServices(
auth_token,
playlist
);
}
const { external_url } = result;
toast.success(
<ToastMsg
title="Playlist exported to {music_service}"
message={
<>
Successfully exported playlist:{" "}
<a href={external_url} target="_blank" rel="noopener noreferrer">
{playlistTitle}
</a>
Heads up: the new playlist is public on {music_service}.
</>
}
/>,
{ toastId: "export-playlist" }
);
};
Import - Backend
Since I have been working on the feature of importing playlists to Spotify (you can find more information in this PR and Ticket), and I believe this feature is beneficial, I would like to propose adding support for importing playlists from other music services as well. Additionally, it would be convenient to store these functions alongside the export function.
Currently, I have only implemented this feature for Spotify. With guidance from @lucifer, I was able to implement this feature for Troi Patch, so now it can be both used for LB and Troi. Here is how it works:
- Fetch Users Playlists from the Music Services using GET playlists API
try: if service == "spotify": user_playlists = get_spotify_playlists(token["access_token"]) else if service == "soundcloud": user_platlists = get_soundcloud_playlists(token["access_token"]) else if service == "apple_music": user_playlists = get_apple_music_playlists() else: raise ValueError("Unsupported music service: {}".format(music_service)) return jsonify(user_playlists["items"]) except requests.exceptions.HTTPError as exc: error = exc.response.json() raise APIError(error.get("error") or exc.response.reason, exc.response.status_code) - The get_spotify_playlists, get_soundcloud_playlists, get_apple_music_playlists will be implemented as shown below:
def get_spotify_playlists(spotify_token):
""" Get the user's playlists from Spotify.
"""
sp = spotipy.Spotify(auth=spotify_token)
playlists = sp.current_user_playlists()
return playlists
def get_soundcloud_playlists(spotify_token):
""" Get the user's playlists from SoundCloud.
"""
url = "https://api.soundcloud.com/me/playlists/"
response = requests.get(url, headers={
"Authorization": "OAuth " + access_token,
"Content-Type": "application/json"
}
,json={
"show_tracks": false,
"linked_partitioning": true,
"limit": 100
})
return response["data"]
def get_apple_music_playlists(spotify_token):
""" Get the user's playlists from Apple Music.
"""
url = "https://api.music.apple.com/v1/me/library/playlists"
response = requests.get(url, headers=headers, data=json.dumps(data))
return response["data"]
- Create a ListenBrainz Playlist with tracks from the selected external Playlist.
a. Get tracks from the selected playlist. This can be achieved by calling this API and then retrieving the tracks using the external API of the specified music service.
@playlist_api_bp.route("/<service>/<playlist_id>/tracks", methods=["GET", "OPTIONS"])
@crossdomain
@ratelimit()
@api_listenstore_needed
def import_tracks_from_spotify_to_playlist(service, playlist_id)
b. Get artist_name, track_name and release_name using mbid_mapping endpoint by passing the track_name and artist_name for each track.
def mbid_mapping(track_name, artist_name):
url = "https://api.listenbrainz.org/1/metadata/lookup/"
params = {
"artist_name": artist_name,
"recording_name": track_name,
}
response = requests.get(url, params=params)
if response.status_code == 200:
data = response.json()
return data
else:
print("Error occurred:", response.status_code)
c. Create a Recording class entity of tracks, pass them to RecordingListElement
recordings=[]
if mbid_mapped_tracks:
for track in mbid_mapped_tracks:
if track is not None and "recording_mbid" in track:
recordings.append(Recording(mbid=track["recording_mbid"]))
else:
return None
recording_list = RecordingListElement(recordings)
d. Generate a playlist using Troi Patch function and pass a RecordingListElement as a parameter.
try:
playlist = troi.playlist.PlaylistElement()
playlist.set_sources(recording_list)
result = playlist.generate()
playlist.playlists[0].name = title
playlist.playlists[0].descripton = description
print("done.")
except troi.PipelineError as err:
print("Failed to generate playlist: %s" % err, file=sys.stderr)
return None
if result is not None and user:
for url, _ in playlist.submit("68fd28b9-37c2-41e1-97b2-31eda342c8c2", None):
print("Submitted playlist: %s" % url)
Import - Frontend
"As I have already worked on this feature, I believe that there will be no significant modifications for the frontend. So far, I have added a new file named “ImportPlaylistModal” in the /user/playlists/ folder. Similar to the export function, it opens a new modal where users can select a playlist from a given music service (in this case: Spotify) to import. Here is the full code.
For this project regarding frontend, I will work on these minor fixes/modifications:
- Update button style (so I have tried to make it dropdown just like “Add Listen” button, however I had some difficulties with alligning it properly and I gave up. So will try to update it later)
- Add a error toast message if user is not authenticated within Spotify
- Add loading screen. So importing playlists from Spotify takes a quite time (~5-20 sec). So I think to add a load screen so users wouldnt get confused.
- Feedback from Monkey, Aerozol: “need a good way to point users that aren’t connected to Spotify to the relevant page.”
UI Mockup
Export
After getting some Feedback from Aerozol and UltimateRiff, I have developed these UI mockups for export feature. Here I plan to expand “Export” button to open a new modal: so user can select to which music service they want to export to. Following UltimateRiff’s suggestion, I decided to add a ScrollBar in case when we will add more services.
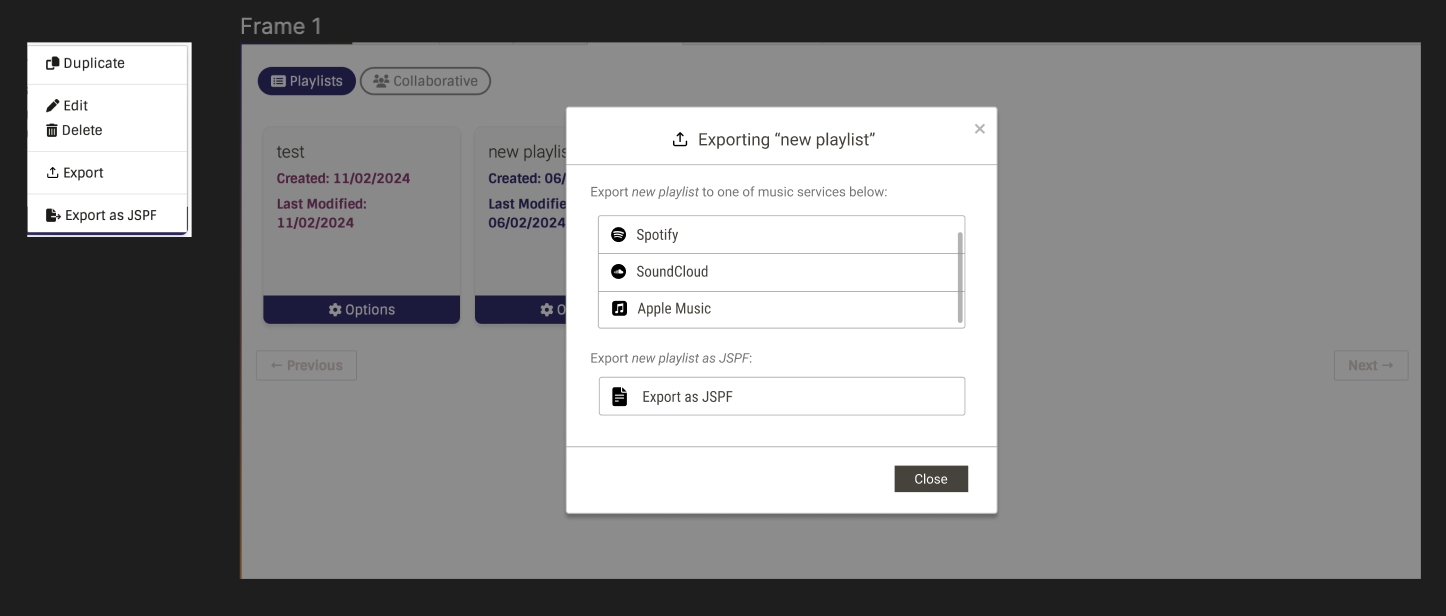
UI for Toast message for successful export:

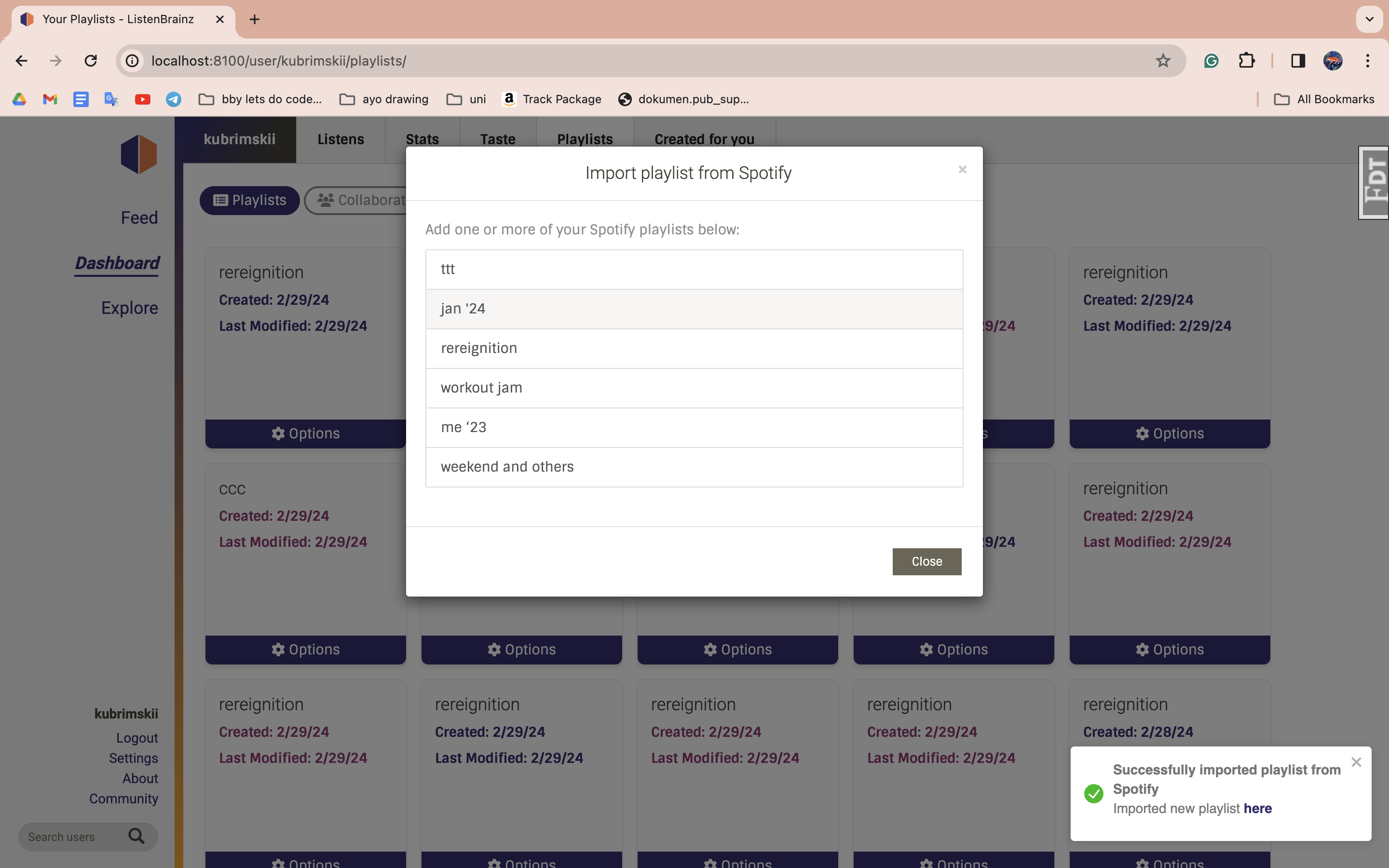
Import
I have came up with the following UI for import function as well. I tried to make the designs for export/import similar for preserve the Listenbrianz design choice and sinse both features re almost similar.
Timeline
Pre-Community Bonding (April-May)
I plan to discuss with Lucifer and Mayhem about the SoundCloud lookup function and the best ways to implement it for this project. I want to address the issue of the lack of necessary data and brainstorm potential solutions. Additionally, I plan to discuss with Mayhem on implementing import/export functions in Troi patches as classes. More precisely, the required functions and other related aspects. I am also keen to learn more about how these features can be utilized within Troi.
Moving forward, I intend to continue contributing, especially to tickets related to database work and Troi. Gaining hands-on experience in these areas will be immensely beneficial for the project.
Community Bonding Period(May)
I plan to continue working on pull requests (PRs) and addressing some tickets. Additionally, I aim to fully finalize my PR involving the importing of playlists, making it easier to integrate into Troi.
For this period, my main goal would be to finalize all ascepts, such as: UI, where to locate these functions, way to execute SoundCloud track lookup and etc.
Week 1
Familiarise myself with the functionalities of troi, connecting with SoundCloud and Apple Music API’s for development and implementing basic functionalities of export functions on the backend.
Gather feedback for UI Mockups
Week 2
Testing the functions I have implemented on the first week, such as, checking SoundCloud/Apple Music API functionalities, Troi Patch playlist generating. Get some UX feedback and reviews, execute the changes.
Week 3-4
Implementing Labs API lookup functionality for Apple Music and SoundCloud. Implementating function to pass the tracks to external urls. Checking for accuracy, how many tracks gets exported and how many not.
Week 5-6
Testing the export function for edge cases and for each of the music services (when user is not authorized, when playlist is empty and etc.) Finalizing the frontend part. Testing the UI/UX part. Also, I plan to use this week to catch up with some tasks that are not yet done.
Week 7-8
Working on integrating import function, implementing it inside Troi patch functions
Implementing the frontend part, including integrating modals to be responsive (for mobile, tablet versions)
Week 9-10
Testing the import functions for edge cases as well
Writing Documentation for additional APIs on Listenbrainz and Labs API
Week 11-12
Finalizing the project and submit the code for review
Discussing with mentors the final stages of the project
I also plan to participate in the weekly Monday meetings in IRC to discuss the progress I’ve made
About Yourself
-
Tell us about the computer(s) you have available for working on your SoC project!
I mainly work on MacBook Pro (13-inch, M1, 2020) with 8 GB RAM. The Operating System - MacOS Sonoma 14.2.1.
-
When did you first start programming?
Back in 7th grade, my first serious project was a Flappy Bird game, and I’m still proud of it to this day. My journey into coding took a more serious turn during university, where I became involved with the ACM Student Chapter. There, I honed my skills in various areas, including working with Figma, coding landing pages, participating in hackathons, and much more!
-
What type of music do you listen to?
I mostly love to listen to chill music! Also as a huge gaming fun, I love some cool songs from games! Here is my top songs that reflects my taste most:
Jungle, Channel Tres - I’ve Been in Love: 92410bbc-4f81-4611-aa78-3f08bc7b9a3e
Saint Model - My Type: b73f17bf-463a-418b-90e6-7f4436097b2f
K/DA - THE BADDEST: e0a4f3b0-3a68-4644-b88f-e4c3e2e16d82
Childish Gambino - L.E.S: aab4c449-63d6-4509-a3a8-06727091d866
Come and follow me on LB!
-
What aspects of the project you’re applying for (e.g., MusicBrainz, AcousticBrainz, etc.) interest you the most?
What I like most about ListenBrainz is its recommendation system. Fun fact: In just two months of using ListenBrainz, I’ve expanded my music playlist by over 40 songs! I appreciate being able to view detailed statistics about my listening habits and recognize patterns. These insights prove incredibly useful when I’m on the hunt for new songs
-
Have you ever used MusicBrainz to tag your files?
Yes! For my friend, actually. It is a super useful feature when your friend is DJ!
-
Have you contributed to other Open Source projects? If so, which projects and can we see some of your code?
ListenBrainz is my first Open Source project where I started to contribute. Here is my PRs I have done for LB
-
What sorts of programming projects have you done on your own time?
Projects like Youtube-To-Spotify converter (it is interesting that it matches with the idea of this project), personal blog, sudoku-solver using image processing, Android App to help quit smoking, tic-tac-toe with AI and many more!
-
How much time do you have available, and how would you plan to use it?
Currently, I am allocating 3-4 hours/day for contributions. In Summer, I believe I will have more time, since I am not planning to work or study, so it will be up to 6-7 hours/day.