PROPOSAL
Contact Information
- Name: Bhumika Bachchan
- Email: bhumikabachchan11315@gmail.com
- Nickname: Bachchan
- IRC nick: insane_22
- Github: insane-22 (Bhumika Bachchan) · GitHub
- Timezone: UTC +05:30
Project Overview
Main Goal:- A functional multi-entity search server with the same features as the existing search functionality
Other MetaBrainz projects use Solr search server, while BookBrainz was created using ElasticSearch and has not evolved since. This creates some extra overhead by running two separate search infrastructures and prevents us from optimizing resources.
For this project, you would entirely replace the search server infrastructure and adapt the existing search to work with Solr. This makes for a project relatively isolated from the rest of the website, the only surface of contact being this file handling most of the indexing and ElasticSearch-specific logic, and this file which adds the website routes that allows users and the website to interact with the search server.
One relevant point of detail is that we want to maintain multi-entity search (search for authors, works, edition, etc all in one go) compared to the MusicBrainz search for example which requires selecting an entity type before performing a search. This would need to be investigated.
Project Duration:- 300 Hours
Proposed Mentors:- monkey, lucifer
Languages/skills:- Javascript (Typescript), Solr
Terminology
Let’s start with the common terminologies which we come across when studying about search infrastructures. Most of these are common in Elasticsearch and Solr with differences talked about in coming sections:-
- Index- An index is a collection of documents that often have a similar structure and is used to store and read documents from it. It’s the equivalent of a database in RDBMS (relational database management system)
- Document- A document is a basic unit of information. Documents can be stored and indexed.
- Field- The field stores the data in a document holding a key-value pair, where key states the field name and value the actual field data. Each document is a collection of fields.
- Shard- Shards allow you to split and store your index into one or more pieces.
Existing Infrastructure
In the current scenario, Bookbrainz uses ElasticSearch as its search engine. ElasticSearch is a distributed, RESTful search and analytics engine built on the top of Apache Lucene.
We use nodejs client @elastic/elasticsearch to integrate Elasticsearch functionality.
Search Fundamentals and the way they are done in BB
Index generation:- Mapping is the process of defining how a document, and the fields it contains, are stored and indexed. When mapping your data, you create a mapping definition, which contains a list of fields relevant for our index.
We use explicit mapping to define data (as name suggests mappings are explicitly written)
Mappings: aliases, authors, disambiguation
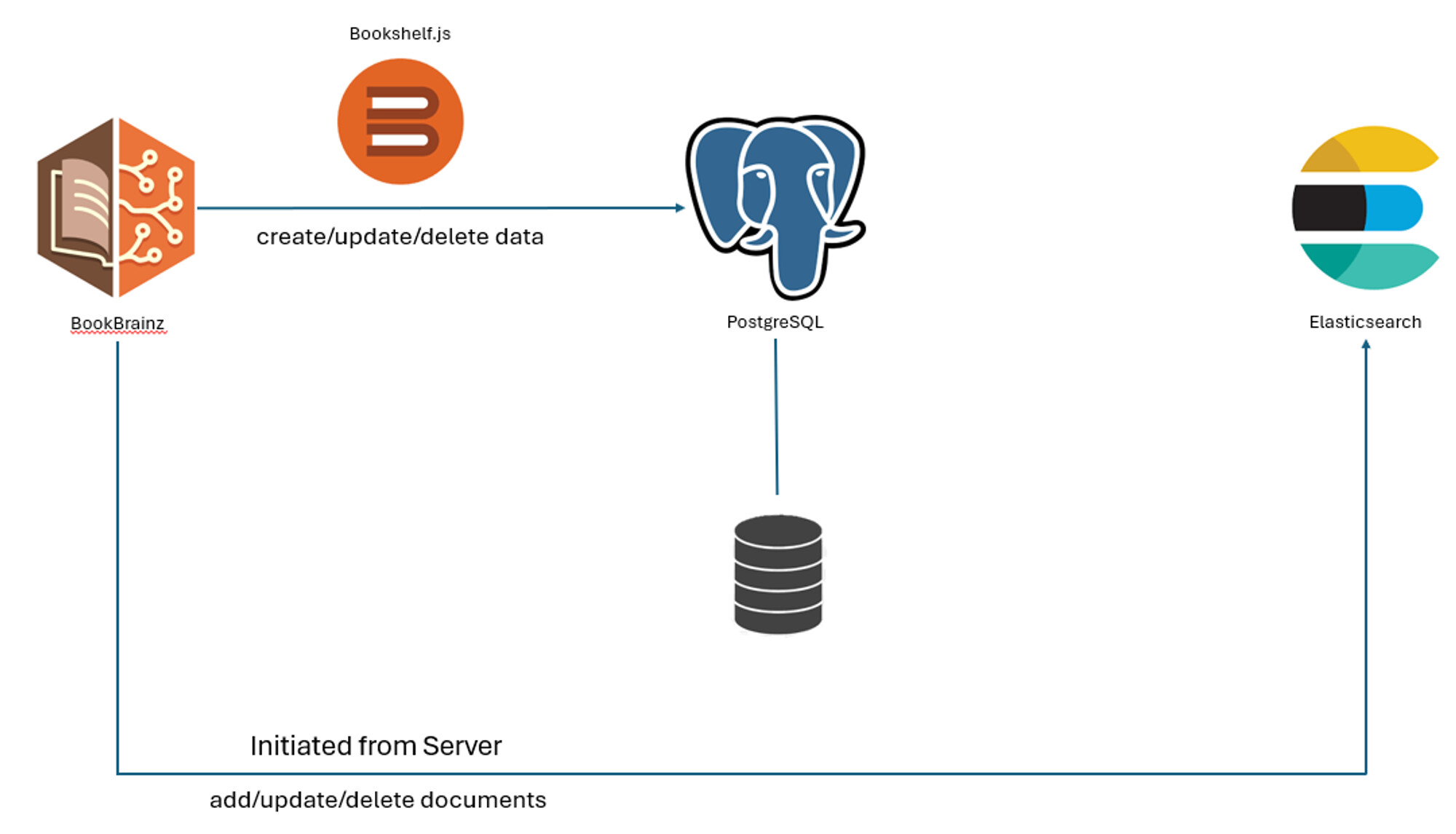
When a person enters data on the BookBrainz website, it is first saved into the PostgreSQL database using BookshelfJS transactions. when this transaction is completed server initiates the indexing of this data into elasticsearch:
Text analysis:- is the process of converting unstructured text, like the body of an email or a product description, into a structured format that’s optimized for search. It is performed by an analyzer, a set of rules that govern the entire process. It is package which contains three lower-level building blocks: character filters, tokenizers, and token filters.
- A character filter receives the original text as a stream of characters and can transform the stream by adding, removing, or changing characters.
- A tokenizer receives a stream of characters, breaks it up into individual tokens (usually individual words), and outputs a stream of tokens.
- A token filter receives the token stream and may add, remove, or change tokens.
In BookBrainz,
Tokenizers used are:-
→ The edge_ngram tokenizer first breaks text down into words whenever it encounters one of a list of specified characters, then it emits N-grams of each word where the start of the N-gram is anchored to the beginning of the word. **min_gram**Minimum length of characters in a gram (1) **max_gram**Maximum length (2) Character classes that should be included in a token. Elasticsearch will split on characters that don’t belong to the classes specified. Defaults to [] (keep all characters).
→ The ngram tokenizer first breaks text down into words whenever it encounters one of a list of specified characters, then it emits N-grams of each word of the specified length.
Token filters used are:-
→ asciifolding- Converts alphabetic, numeric, and symbolic characters that are not in the Basic Latin Unicode block (first 127 ASCII characters) to their ASCII equivalent, if one exists.
→ lowercase- Changes token text to lowercase
→ edge_ngram- Forms an n-gram of a specified length from the beginning of a token.
→ ngram- Forms n-grams of specified lengths from a token.
The ignore_malformed parameter has been set to true which allows the exception to be ignored which is thrown when we try to index the wrong data type into a field. The malformed field is not indexed, but other fields in the document are processed normally.
Searching:- A search query, or query, is a request for information about data in Elasticsearch data streams or indices. A search consists of one or more queries that are combined and sent to Elasticsearch. Documents that match a search’s queries are returned in the hits, or search results, of the response. Elasticsearch provides a full Query DSL (Domain Specific Language) based on JSON to define queries.
It sorts matching search results by relevance score, which measures how well each document matches a query. The relevance score is a positive floating point number, returned in the _score metadata field of the search API. While each query type can calculate relevance scores differently, score calculation also depends on whether the query clause is run in a query or filter context.
Query context- Besides deciding whether or not the document matches, the query clause also calculates a relevance score in the _score metadata field.
In BB, full text queries are done. The full text queries enable you to search analysed text fields such as the body of an email. The query string is processed using the same analyzer that was applied to the field during indexing.
→ Match query- Returns documents that match a provided text, number, date or boolean value. The provided text is analyzed before matching.
→ Multi-Match query- builds on the [match query](Match query | Elasticsearch Guide [8.12] | Elastic) to allow multi-field queries.
The way the multi_match query is executed internally depends on the type parameter. In BookBrainz cross-fields type is used. It is a term-centric approach which first analyzes the query string into individual terms, then looks for each term in any of the fields, as though they were one big field.
In the Elasticsearch query DSL, individual fields can be boosted using the caret (^) notation. The boost factor is a floating-point number that determines the significance of the field in the relevance scoring. When Elasticsearch calculates the relevance score for a document, it considers the boost factor assigned to each field. Documents containing matches in fields with higher boost factors will be scored more favorably and are likely to appear higher in the search results.
Queries have a minimum_should_match parameter which indicates that this percent of the total number of optional clauses are necessary. The number computed from the percentage is rounded down and used as the minimum.
Complete Process
Majority of the code for searching is same for the website and BookBrainz api:
- Initialization:- On app startup, the
initfunction is called. This function initializes the Elasticsearch client with provided options and checks if the main index exists. If the index doesn’t exist, it generates the index using thegenerateIndexfunction - Index Generation:- The
generateIndexfunction fetches data from the ORM of the database (initialised during app setup from bookbrainz-data (const app = express();
app.locals.orm = BookBrainzData(config.database); ) It processes this data. For entities, it prepares documents for indexing, and bulk indexes them into Elasticsearch. It also handles special cases like Areas, Editors, and UserCollections, separately due to differences in their data structures. It then refreshes the index to make the changes visible. - Bulk Indexing and Retry Logic:- It indexes 10000 entities at a time. The
bulkAPI makes it possible to perform many index/delete operations in a single API call. The code handles the scenario where indexing may fail due to too many requests, and it retries failed indexing operations after a small delay to ensure that all entities are eventually indexed. - Indexing single entity:- Function
indexEntityis responsible for indexing a single entity into Elasticsearch. It prepares document for the required entity and then indexes it. - Searching entities:- Search operations are handled by functions like autocomplete and searchByName. These functions construct Elasticsearch DSL queries based on the search parameters provided (e.g., query string, entity type) and execute the queries using the Elasticsearch client. The search results are then processed and returned in a format suitable for the application.
Project Goals:
- Set up and configure Solr Search Server within BookBrainz infrastructure.
- Implement efficient data indexing mechanisms in Solr to ensure timely updates and synchronization with the BookBrainz database (Search Index Rebuilder)
- Configuring Solr to optimize query performance with the support of Solr’s buillt-in features like caching, query-parsing and warming
- Multi-entity search support (explained in implementation part)
- Configure Solr to give optimal responses for search queries, implementing features like caching, query warming and parsing (Search Server Schema)
- Ensure that multi-entity search functionality is working fine , enabling users to search for authors, works, editions, and other entities.
- Implement custom tokenizers, and filters in Solr to accommodate the specific requirements of BookBrainz search functionality, including language-specific analysis and stemming. (As is done in MusicBrainz Query Parser) This again needs to be discussed well about particular needs, current working etc qnd a comparison with standard ones provided by lucene
- Integrate search server with the existing BookBrainz codebase, ensure things are working properly with the new setup. This would need to change files
- Conduct rigorous testing of Solr implementation, including unit tests, integration tests, and end-to-end tests, to validate functionality and performance
- Setup and configuration of Solr Zookeeper (”Although Solr comes bundled with Apache ZooKeeper, you are strongly encouraged to use an external ZooKeeper setup in production”)
- Configure SolrCloud and extend all the working functions from standalone Solr instance to SolrCloud. It includes indexing, querying and sending results. (Major task)
- Manage Solr Cloud distribute routes for multi-entity search
- Understanding monitoring Solr using metrics API
- Using Prometheus and Grafana for metrics storage and data visualization
- Dockerize the whole search infrastructure
My goal throughout would be to ensure that all the goals are completed but the priority would be to setup a complete Solr server which would be comparable to present search infrastructure and I am confident that with the support of community and the guidance of my mentors I would be able to complete the project well in time with the desired results.
Implementation:
Solr
Apache Solr (stands for Searching On Lucene w/ Replication) is a free, open-source search engine based on the Apache Lucene library. Lucene is a scalable and high-performance Java-based library used to index and search virtually any kind of text. Lucene library provides the core operations which are required by any search application. In comparison to Elasticsearch setup the process of setup is similar yet different (oxymorons <3)
Configuration and setting up
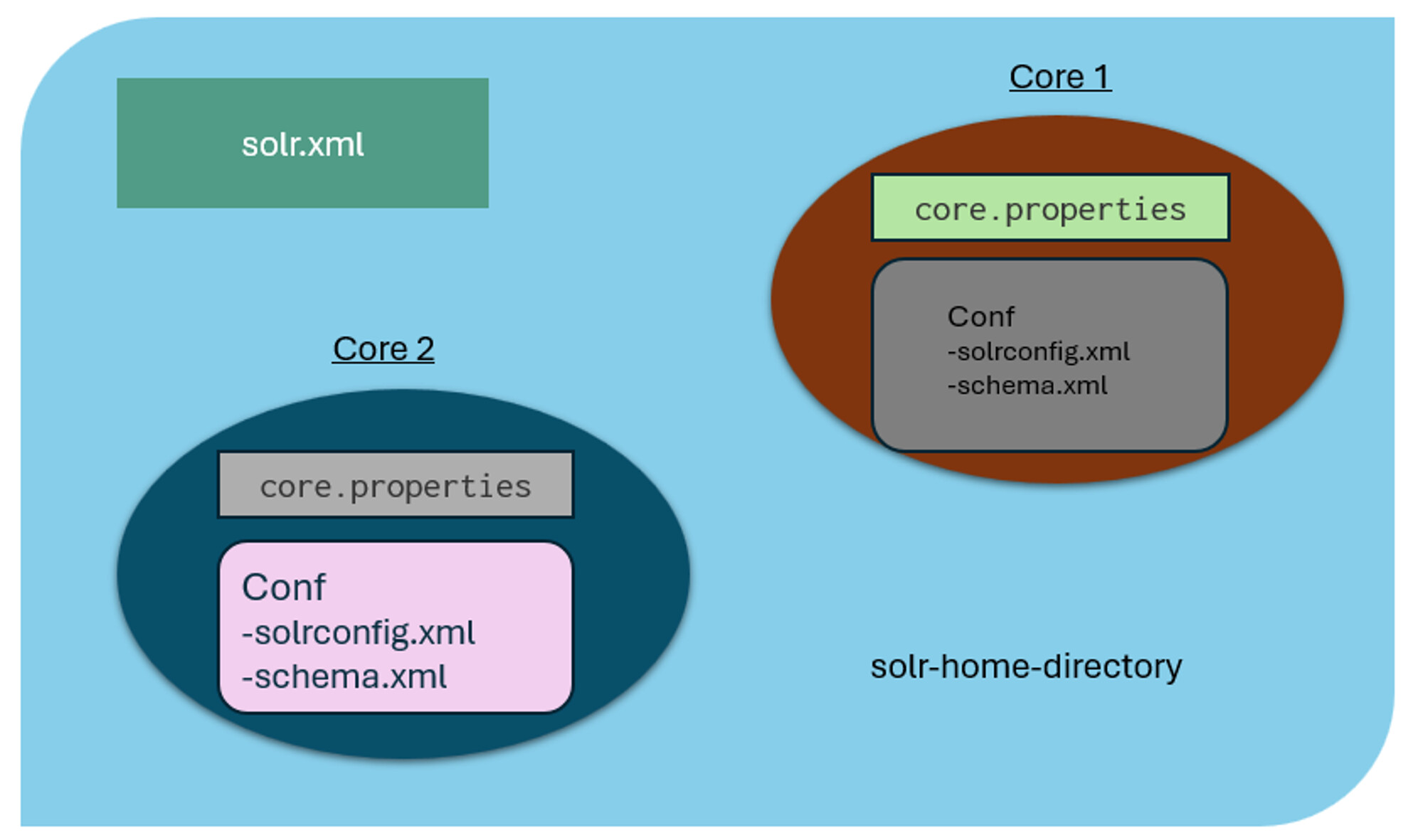
Solr has several configuration files, majorly written in XML. Overall structure:-
-
solr.xml:- specifies configuration options for your Solr server instance.
<solr> <solrcloud> <!--explained later--> </solrcloud> <str name="sharedLib">lib</str> <metrics> <!--explained later--> </metrics> </solr>It sets lib folder as sharedLib which would be used to store and configure Query Response writer (if written separately).
Cores to be created would be ‘Author’, ‘Edition’, ‘EditionGroup’, ‘Publisher’, ‘Series’, ‘Work’, ‘Editor’, ‘Collection’ and 'Area’ from which the first six are BB entities. -
core.properties- defines specific properties for each core such as its name, the collection the core belongs to, the location of the schema, and other parameters.
It is a simple Java Properties file where each line is just a key-value pair, e.g.,name=core1.
The minimalcore.propertiesfile is an empty file, in which case all of the properties are defaulted appropriately like the folder name is defaulted as the core name and so on.
To create a new core, simply add acore.propertiesfile in the directory. -
solrconfig.xml- controls high-level behavior of solr core it is present in.
<luceneMatchVersion>9.0.0</luceneMatchVersion> <directoryFactory name="DirectoryFactory" class="${solr.directoryFactory:solr.NRTCachingDirectoryFactory}" /> <dataDir>${solr.home}/data/${solr.core.name:}</dataDir> <codecFactory name="CodecFactory" class="solr.SchemaCodecFactory" /> <schemaFactory class="ClassicIndexSchemaFactory" /> <updateHandler class="solr.DirectUpdateHandler2"> <!-- to be discussed --> </updateHandler> <query> <queryResultCache class="solr.CaffeineCache" size="32768" initialSize="8192" autowarmCount="512" maxRamMB="200" /> <documentCache class="solr.CaffeineCache" size="32768" initialSize="8192" autowarmCount="4096" /> </query>dataDir and directoryFactory indicate the storage location of index and other data files. The
[solr.NRTCachingDirectoryFactory]is filesystem based, and tries to pick the best implementation for the current JVM and platform.
schemaFactory tells how the schema file would be configured. It can either be a managed one or manual. For the later part of project, we’d need to shift from classic to managed. -
schema.xml- stores details about types and fields which are essential for the given core. uniqueKey specifies field element which is unique for the document. Including it is necessary for updating the documents. UUIDUpdateProcessorFactory can be directly used for this.
Similarity is a Lucene class used to score a document in searching. SchemaSimilarityFactory allows individual field types to be configured with a “per-type” specific Similarity and implicitly uses BM25Similarity for any field type which does not have an explicit Similarity.
FieldType defines the analysis that will occur on a field when documents are indexed or queries are sent to the index. Fields are then defined based on the defined FieldTypes.
There are certain Solr concepts which need to be discussed prior to setup:-
Commits:- It is configured in updateHandler settings, which affect how updates are done internally.
After data has been fetched, it must be committed first before search would work on these. These commits can be either sent manually or we have an autocommit option too, which we would consider for the project as it offers much more control over commit strategy.
There are 2 types- hard commit and soft commit. Determining the best autoCommit settings is a tradeoff between performance and accuracy. Settings that cause frequent updates will improve the accuracy of searches because new content will be searchable more quickly, but performance may suffer because of the frequent updates. Less frequent updates may improve performance but it will take longer for updates to show up in queries. The realtime get feature allows retrieval (by unique-key) of the latest version of any documents without the associated cost of reopening a searcher. These requests can be handled using an implicit /get request handler:-
<requestHandler name="/get" class="solr.RealTimeGetHandler">
<lst name="defaults">
<str name="omitHeader">true</str>
</lst>
</requestHandler>
updateHandler settings:-
<updateHandler class="solr.DirectUpdateHandler2">
<updateLog>
<str name="dir">${solr.solr.home}/data/${solr.core.name:}</str>
</updateLog>
<autoCommit>
<maxTime>${solr.autoCommit.maxTime:60000}</maxTime>
</autoCommit>
<autoSoftCommit>
<maxTime>${solr.autoSoftCommit.maxTime:10000}</maxTime>
</autoSoftCommit>
</updateHandler>
Caches:- Cache management is critical to a successful Solr implementation. By default cached Solr objects do not expire after a time interval; instead, they remain valid for the lifetime of the Index Searcher (this can be changed using maxIdleTime).
Solr comes with a default SolrCache implementation that is used for different types of caches
- The
queryResultCacheholds the results of previous searches: ordered lists of document IDs (DocList) based on a query, a sort, and the range of documents requested. - The
documentCacheholds Lucene Document objects (the stored fields for each document). This cache is not autowarmed.
Request Handlers:- A request handler processes requests coming to Solr. These might be query requests, index update requests or specialized interactions. If a request handler is not expected to be used very often, it can be marked with startup="lazy" to avoid loading until needed.
Defaults:- The parameters there are used unless they are overridden by any other method.
Appends:- you can define parameters that are added those already defined elsewhere
Invariants:- you can define parameters that cannot be overridden by a client
initParams:- allows you to define request handler parameters outside of the handler configuration. This helps you keep only a single definition of few properties that are used across multiple handlers. The properties and configuration mirror those of a request handler. It can include sections for defaults, appends, and invariants, the same as any request handler. We can write these in a file to be stored in each core (like request-params.xml in MusicBrainz, which would be discussed later, along with search handlers while discussing about searching).
Request dispatcher:- controls the way the Solr HTTP RequestDispatcher implementation responds to requests. The requestParsers sub-element controls values related to parsing requests.
Update Request Processors:- All the update requests sent to Solr are passed through a series of plug-ins known as URPs. It consists of several Update Processor Factories (UPF I call them), which can be configured based on our use case. There are 3 default UPF which should be remembered not to remove in case we define our own URP:-
LogUpdateProcessorFactory - Tracks the commands processed during this request and logs them
DistributedUpdateProcessorFactory - Responsible for distributing update requests to the right node e.g., routing requests to the leader of the right shard and distributing updates from the leader to each replica. This processor is activated only in SolrCloud mode.
RunUpdateProcessorFactory - Executes the update using internal Solr APIs.
ScriptUpdateProcessorFactory:- allows Java scripting engines to be used during Solr document update processing. It is implemented as an UpdateProcessor to be placed in an UpdateChain.
<updateRequestProcessorChain name="ignore-commit-from-client" default="true">
<processor class="solr.IgnoreCommitOptimizeUpdateProcessorFactory">
<int name="statusCode">200</int>
</processor>
<processor class="solr.LogUpdateProcessorFactory" />
<processor class="solr.DistributedUpdateProcessorFactory" />
<processor class="solr.RunUpdateProcessorFactory" />
</updateRequestProcessorChain>;
Document Analysis:- The process is quite similar to how it happens in ElasticSearch.
An analyzer examines the text of fields and generates a token stream. Tokenizers break field data into lexical units, or tokens. Filters examine a stream of tokens and keep them, transform or discard them, or create new ones.
Analyzers:- child of the <fieldType> element in schema.xml file. In normal usage, only fields of type solr.TextField or solr.SortableTextField will specify an analyzer.
Analysis takes place at two instances: at index time, when a field is being created, the token stream that results from analysis is added to an index and defines the set of terms (including positions, sizes, and so on) for the field. At query time, the values being searched for are analyzed and the terms that result are matched against those that are stored in the field’s index. There could be the same analysis rules in both the cases as well as different. The first case is desirable when you want to query for exact string matches, possibly with case-insensitivity, for example. In other cases, you may want to apply slightly different analysis steps during indexing than those used at query time.
For our use case, it would be better to have separate analyzers.
Tokenizers- read from a character stream (a Reader) and produce a sequence of token objects (a TokenStream). Filter looks at each token in the stream sequentially and decides whether to pass it along, replace it, or discard it. The order in which the filters are specified is significant. Typically, the most general filtering is done first, and later filtering stages are more specialized. Configured with a element in the schema file as a child of , following the element.
CharFilter- is a component that pre-processes input characters. They can be chained like Token Filters and placed in front of a Tokenizer.
Stemming- set of mapping rules that maps the various forms of a word back to the base, or stem, word from which they derive. For example, in English the words “hugs”, “hugging” and “hugged” are all forms of the stem word “hug”. The stemmer will replace all of these terms with “hug”, which is what will be indexed. This means that a query for “hug” will match the term “hugged”, but not "huge”. Snowball Porter Stemmer Filter. KeywordRepeatFilterFactory
Emits each token twice, one with the KEYWORD attribute and once without. If placed before a
stemmer, the result will be that you will get the unstemmed token preserved on the same position as the stemmed one. Queries matching the original exact term will get a better score while still maintaining the recall benefit of stemming. Another advantage of keeping the original token is that wildcard truncation will work as expected. To configure, add the KeywordRepeatFilterFactory early in the analysis chain. It is recommended to also include RemoveDuplicatesTokenFilterFactory to avoid duplicates when tokens are not stemmed.
Phonetic Matching- algorithms may be used to encode tokens so that two different spellings that are pronounced similarly will match. There are a few predefined filters for phonetic matching. This would need to be discussed well and test on results before implying.
Language Analysis:- Currently, BookBrainz is currently only in english language. Thus there won’t be any need to setup ICU filter. But since it’s a planned project for this summer, I would be more than happy to update the files accordingly in future.
We can modify the rules and re-build our own tokenizer with JFlex. But based on our use case and the current Text-analysis strategy implemented in ElasticSearch (which works quite well), I feel we can simply map some of the characters before tokenization with a CharFilter.This again needs to be discussed and then implemented. The code I’ve written here uses the standard ones only and we would need to improve upon this
<types>
<!-- general types used almost everywhere -->
<fieldtype name="string" class="solr.StrField" sortMissingLast="false" />
<fieldType name="long" class="solr.LongPointField" positionIncrementGap="0" />
<fieldType name="bbid" class="solr.UUIDField" omitNorms="true" />
<fieldType name="storefield" class="solr.StrField" />
<fieldType name="bool" class="solr.BoolField" />
<fieldType name="date" class="solr.DateRangeField" sortMissingLast="false" />
<fieldType name="int" class="solr.IntPointField" sortMissingLast="false" />
<fieldType name="float" class="solr.FloatPointField" />
<!-- sample fieldType for an edge N-gram analyser -->
<fieldType name="autocomplete" class="solr.EdgeNGramTokenizerFactory" />
<analyser type="index">
<tokenizer class="solr.EdgeNGramTokenizerFactory" />
<filter class="solr.ASCIIFoldingFilterFactory" preserveOriginal="false" />
<filter class="solr.WordDelimiterGraphFilterFactory" generateWordParts="1"
generateNumberParts="0" catenateWords="0" catenateNumbers="0" catenateAll="0"
splitOnCaseChange="0" preserveOriginal="0" splitOnNumerics="0" stemEnglishPossessive="0"/>
<filter class="solr.LowerCaseFilterFactory" />
</analyser>
<analyser type="query">
<tokenizer class="solr.EdgeNGramTokenizerFactory" />
<filter class="solr.ASCIIFoldingFilterFactory" preserveOriginal="false" />
<filter class="solr.WordDelimiterGraphFilterFactory" generateWordParts="1"
generateNumberParts="0" catenateWords="0" catenateNumbers="0" catenateAll="0"
splitOnCaseChange="0" preserveOriginal="0" splitOnNumerics="0" stemEnglishPossessive="0"/>
<filter class="solr.LowerCaseFilterFactory" />
<filter class="solr.NGramFilterFactory" minGramSize="2" maxGramSize="10" />
</analyser>
</types>
Indexing:-
After having setup the solr server, the next step would be to setup a system for indexing the data.
Solr uses Lucene to create an “inverted index”. it inverts a page-centric data structure (documents ⇒ words) to a keyword-centric structure (word ⇒ documents). We can visualise this as the index present at the end of the book where the occurence page number of certain important words is listed. Solr, therefore, achieves faster responses because it searches for keywords in the index instead of scanning the text directly. For other features that we now commonly associate with search, such as sorting, faceting, and highlighting, this approach is not very efficient. To cater to this, DocValue fields are now column-oriented fields with a document-to-value mapping built at index time.
Before indexing the data, it would need to be imported and organized in the way we want to so that searches could be performed in the way we want and on fields we want. The current code present in src/common/helpers/search.ts can be used for this specific purpose unless we want to change the fields to search on, which could be done in course if required.