GSoC 2024: Add Syndication Feeds to ListenBrainz
About Me
-
General Info
Nickname/Discord/IRC: ericd
Email: [redacted]
Github: ericd23
Timezone: CST UTC+8
My name is Eric Deng. I graduated from UESTC last year and will be attending McMaster University this fall, both majoring computer science. From now though this summer, I will have time dedicated to my family and open source software.
-
Music
I find myself mostly listening to Electronic/Jazz/RnB, here’s a few examples:
- At the Blue Note: The Complete Recordings - Keith Jarrett
- Random Access Memories - Daft Punk
- Subject - Dwele
I knew MetaBrainz from beets, which uses it to get metadata. I use beets to collect albums I like (downloaded using spotdl), to build a future-proof library. It works perfectly well, especially the metadata fetching part!
The thought of recording my listening history has been lingering around my mind for some time, and ListenBrain seems a good fit since it offers Spotify and Youtube integration. And I would really like to help improve it.
-
Tech
I’m interested Linux, system software, as well as full stack development. I’ve been a Linux user for 5 years. For the last 3 month I’m been learning distributed systems and having fun implementing Raft-related systems in Go. Last year, I interned at a SaaS startup doing LLM-related backend service, using both Nodejs and Python (Flask).
I used Python and Flask to quickly roll out a demo of a RAG application during my internship. Though I now don’t have access to the code repo, I could find some code snippets on my personal laptop to demonstrate its basic idea.
My recent effort on distributed system could be found here. You can also find some of my previous code here (I will try to add any other old projects I still have a local copy).
My OSS contribution is not large at this time, that’w why I thought this GSoC project could help kick start my OSS journey

Project Proposal
Synopsis
Project Length: 175 hours
Goals:
- Add feed endpoints for user events, fresh releases, stats and stats art
- Implement authentication mechanism for private feed
- Add documentation for feeds
Deliverables
Feed generation (required)
We use Atom as the feed syndication format. It is simple and precisely defined XML. With Python’s built-in XML support, we first introduce a util class to work with Atom:
feed = AtomFeed(
title = "Eric's Feed - ListenBrainz",
link = "https://listenbrainz.org/feed/",
updated = datetime.datetime.now(),
id = gen_id(),
author = listenbrainz_contacts(),
entries = [
AtomEntry(
title = "Eric Listened to Part I - Keith Jarrett",
id = gen_id(),
link = "https://musicbrainz.org/recording/a82bc5dd-c72c-4a7f-90f1-ef12b2b48bc6",
content = "Eric listened to Part I - Keith Jarrett. Click to the MB recording page.",
updated = datetime.datetime.now(),
])
return feed.to_xml()
We can then subclass AtomFeed to add more abstraction. For example, with a class called UserEventsFeed, we can create a specific feed by simply filling a few fields:
feed = UserEventsFeed(user_name = "Eric", type = "listen")
return feed.to_xml()
Likewise, we can subclass AtomEntry to add convenience.
Authentication (required)
We introduce a new token to authenticate reads on feed endpoints. We don’s the user token because its privilege scope is too large and has write access.
We use a new table to store the feed token and add foreign key constraint:
CREATE TABLE user_syndication_feed (
id SERIAL,
user_id INTEGER NOT NULL, -- FK to "user".id
feed_token VARCHAR,
);
ALTER TABLE user_syndication_feed
ADD CONSTRAINT user_syndication_feed_user_id_foreign_key
FOREIGN KEY (user_id)
REFERENCES "user" (id)
ON DELETE CASCADE;
When a user tries to read on a private user-specific feed endpoints, we require the request to include a query string called code, with value md5(feed_endpoint_route + feed_token). For example, user timeline event is private to the user, so the request should look like this: /user/ericd/feed/events?code=0f820530128805ffc10351f22b5fd121.
We will provide an API to get the token so that frontend can construct a feed URL with correct code for users. Upon each request, backend does the hashing again and compare the result with code. If match, authentication succeeds.
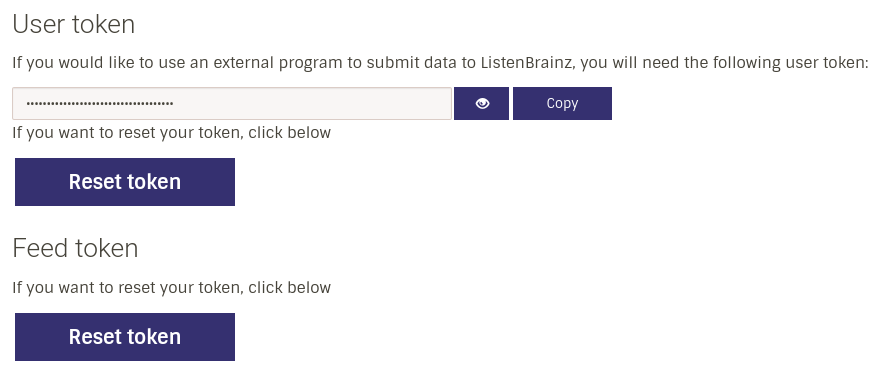
At the setting page, we could let user reset the feed token:
Feed endpoints (required)
We can put feed endpoints in a separate blueprint:
atom_bp = Blueprint("atom", __name__)
and register it like a normal page under /atom :
app.register_blueprint(atom_bp, url_prefix='/atom')
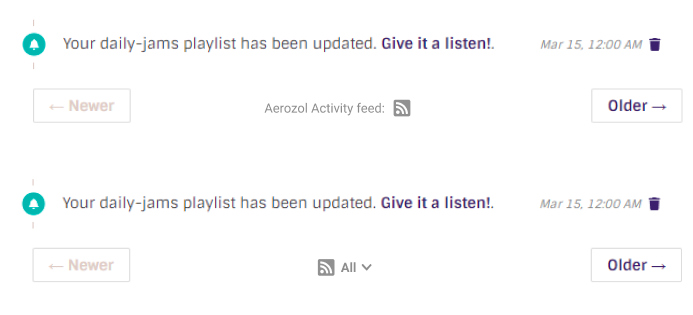
Here’s a list of endpoints I’d like to add.
-
my feed
It will be served at
/user/<user_name>/feed/events.There are several event types:
class UserTimelineEventType(Enum): RECORDING_RECOMMENDATION = 'recording_recommendation' FOLLOW = 'follow' LISTEN = 'listen' NOTIFICATION = 'notification' RECORDING_PIN = 'recording_pin' CRITIQUEBRAINZ_REVIEW = 'critiquebrainz_review' PERSONAL_RECORDING_RECOMMENDATION = 'personal_recording_recommendation'We can provide a query string called
typeto let users choose what types of event to show. It could be specified multiple times, like thislistenbrainz.org/atom/user/ericd/feed/events?type=listen&type=recording_pin. By default, we enable all types.And like API
/1/user/(user_name)/feed/events, we will also supportmax_ts,min_tsandcountparameters.Here’s a pseudo Python code to demonstrate the idea and it will check
codequery string described in the authentication section:@atom_bp.route('/user/<user_name>/feed/events', methods=['OPTIONS', 'GET']) def events_feed(user_name: str): validate_code() _validate_get_endpoint_params() types = request.args.getlist("type") get_following_for_user() if "listen" in types: get_listen_events() if "follow" in types: get_follow_events() ... handle_hidden_events() sort_events_by_time() all_events = all_events[:count] ...Then we can use
all_eventsto construct the feed response.for event in all_events: entry = UserEventEntry(type = event.type, ...) entries.append(entry) feed = UserEventsFeed(user_name = "Eric", items = items)Finally we use Flask’s
make_responseto fill the response content and setContent-Typetoapplication/atom+xml.response = make_response(atom.to_xml()) response.headers['Content-Type'] = 'application/atom+xml' return responseOn feed readers, each event will be shown as a feed item:
-
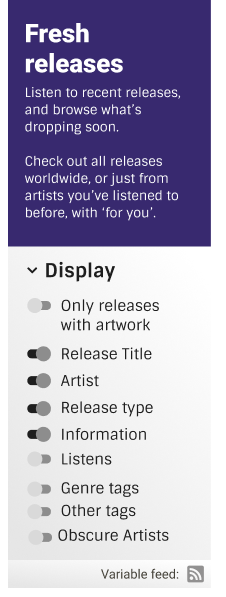
fresh releases
There are two fresh releases feeds, one for user and one for the whole site. The endpoints for them will be
/user/<user_name>/fresh_releasesand/explore/fresh_releases.We only sort the release by
release_date. We also allow users to choose if we should includepastandfuturerelease through query string.On feed readers, each release will be a feed item:
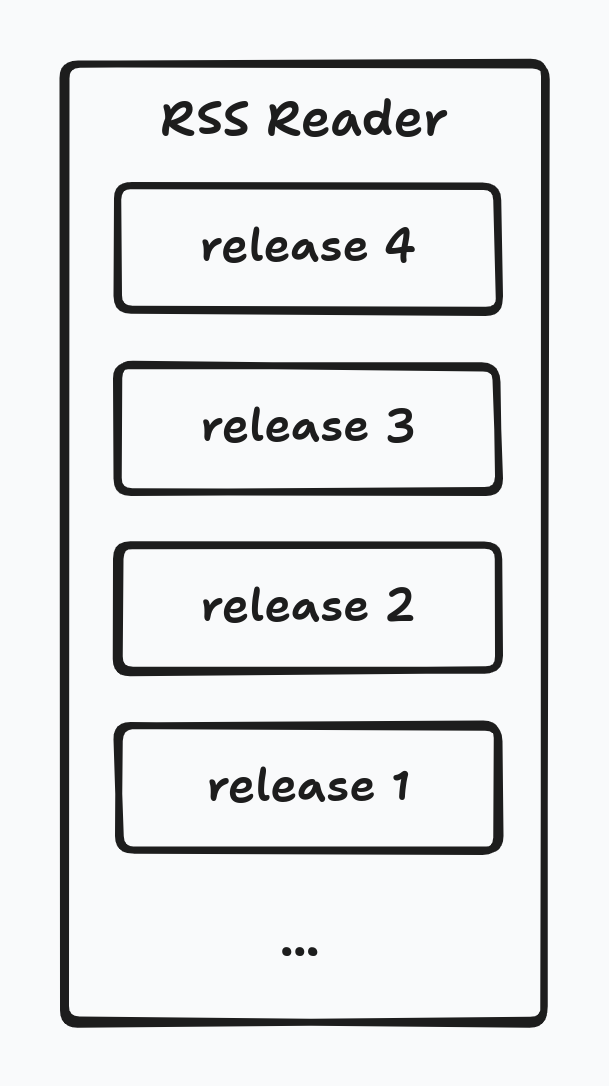
-
stats
There are various of statistical data on user’s stats page. I think it makes sense to include top artists, top release groups and top recording in our feed.
Their endpoint will be:
/stats/user/<user_name>/artists/stats/user/<user_name>/release-groups/stats/user/<user_name>/recordings
The shares the same internal logic for the JSON API counterparts. All 3 lets users to specify range, offset and count. So a typical endpoint would be like this:
/stats/user/ericd/artists?offset=0&range=this_week&count=10.For range
this_*, the stats are updated every day since the range hasn’t ended. So the feed should update once a day, each update aggregates more stats as we listen to music through time.On feed readers, it looks like this:
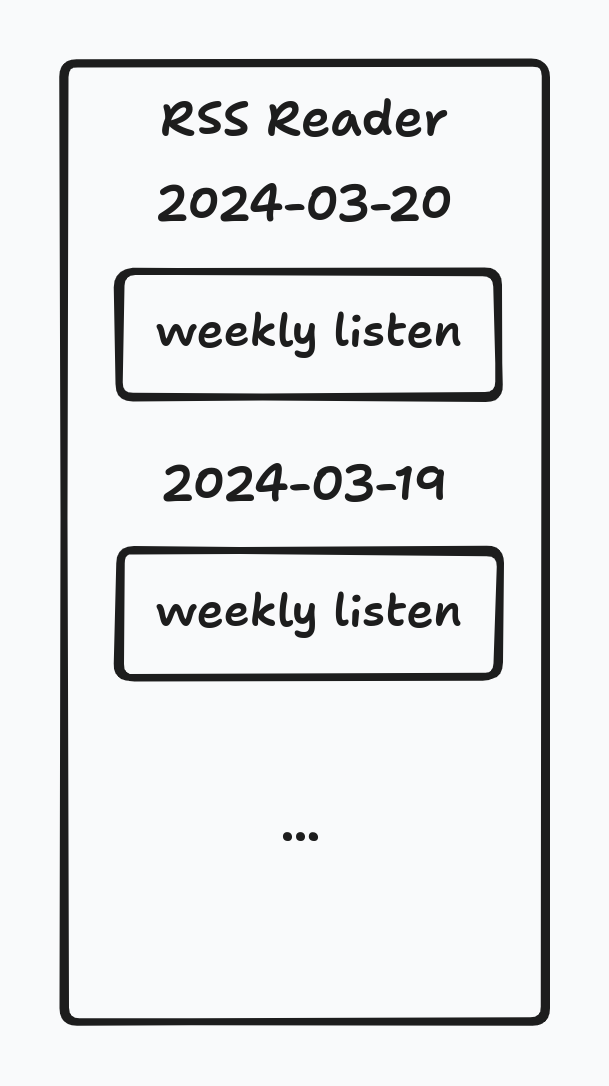
If the range is not this_* , but week , month or year , we will make sure the stats only update when the specified time range has ended. week, month and year update once a week, once a month and once a year, respectively.
On feed readers, “top artists for last week” should look like this:

-
stats art creator
We will serve all art creator types that are available on Web UI and include the generated svg element in the feed content:
/art/<custom_name>/<user_name>/<time_range>/<image_size>/art/grid-stats/<user_name>/<time_range>/<dimension>/<layout>/<image_size>
UI (required)
Basically we will have 2 types of feed button (thanks, aerozol!). One for page which has an extensive customization UI component and we place the button there:
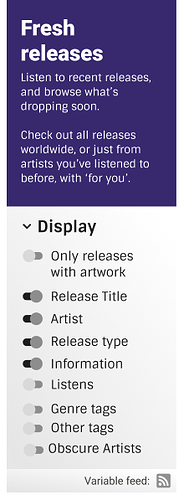
and one for regular page where we put the button right at the corresponding component for the feed:
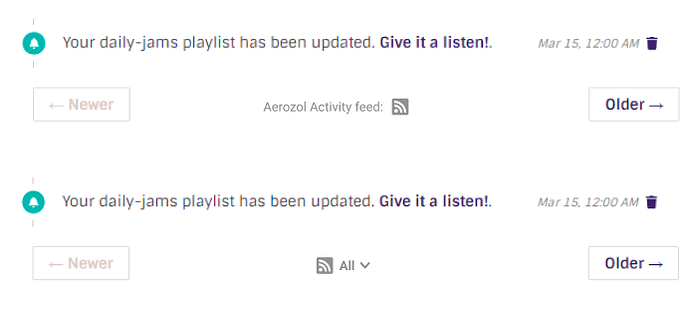
When user hover on the button, we could display tool tips to provide more information and helps on how to use our feed endpoints.
Documentation (required)
Feed endpoints are kind of like APIs in terms of how we handle them. Thus we will document them with in-code docstrings and also dedicated documentation pages.
Practical requirements
Hardware: ThinkPad X1 Carbon 6th, Intel Core i5-8350U, 16G RAM
Software: Arch Linux, VSCode
Timing
-
Before May 27 (official beginning of coding), I would like to discuss this project with possible people and contribute to other parts of ListenBrainz. I will also attend dev meeting on Monday to communicate progress and feedback.
-
July through August: I will be spending 20 to 30 hours a week on the project.
time frame plan week 1-2 (May 27 - June 9) Implement Atom feed utility class. Make sure we can generate generic Atom feed which can be correctly rendered by-2 feed readers. (Milestone: feed generation) week 3-4 (June 10 - June 23) Add feed for user fresh releases and related UI work. End user tests. week 5 (June 24 - 30) Implement authentication for feed endpoint private to user. (Milestone: authentication) week 6 (July 1 - 7) Add feed for user timeline events, which should use previously implemented authentication scheme. End user tests. week 7-8 (July 8 - 21) Add feed for stats and art creator. End user tests. (Milestone: feed endpoints) week 9-10 (July 22 - Aug 4) Collect final community feedback and make improvements. Write documentation page. week 11 (Aug 5 - 11) Wrap up the project and prepare the final deliverable. Write the GSoC blog post.
edits(20240327): add project length; prefer Atom to RSS; use separate feed token; update UI mockup; add doc consideration.