Personal Information:
IRC nick: meycroft
GitHub: meycroft (meycroft) · GitHub
Time Zone: UTC-4
Project Overview
LB has a number of music discovery features that use BrainzPlayer to facilitate track playback. BrainzPlayer (BP) is a custom React component in LB that uses multiple data sources to search and play a track. As of now, it supports Spotify, YouTube and Soundcloud as a music service. LB also supports linking a Spotify account to record listening history. We have looked into some other services and found that Deezer provides the music playback and recording listening history capability. This project involves integrating these services into LB.
My contributions:
PRs: Check out
Commits: Check out
Implementation
The project will have following major components:
Part 1 - Allow user to link to Deezer for recording history (Weeks 1-6):
Phase 1 - Adding OAuth support so that the user can connect to the service (Weeks 1-3):
Since the Deezer API will be called by the web-server, server-side flow will be used for oAuth 2.0 authentication. There are three different steps in the flow:- User Authentication
- App Authorization
- App Authentication
The first two steps redirect the user to a login window on deezer.com domain.
This phase will involve following tasks:
1.1. Setup Deezer API configuration and process for user authorization:
- Generate developer application ID (required by Deezer API
OAUTH_TOKEN_URL) - Add functions to save token in save access token in database:
def get_user(self, user_id: int) -> Optional[dict]:
# get the message of the user
return deezer.get_user(user_id)
def add_new_user(self, user_id: int, token: dict) -> bool:
external_service_oauth.save_token(user_id=user_id, service=self.service, access_token=access_token,
refresh_token=refresh_token, token_expires_ts=expires_at,
record_listens=active, scopes=scopes, external_user_id=external_user_id)
- Set an endpoint to accept setting from user and display permissions:
@profile_bp.route('/music-services/details/', methods=['GET'])
@login_required
def music_services_details():
deezer_service = DeezerService()
deezer_user = deezer_service.get_user(current_user.id)
// Implement the Deezer Permission here
return render_template(
'user/music_services.html',
deezer_user=deezer_user,
current_deezer_permissions=current_deezer_permissions,
)
1.2. Add functions to get authorization information:
def get_authorize_url(self, permissions: Sequence[str]):
def fetch_access_token(self, code: str):
- Also setup endpoint for music service callback to finish authorization process.
@profile_bp.route('/music-services/<service_name>/refresh/', methods=['POST'])
@api_login_required
def refresh_service_token(service_name: str):
""" Returns JS:
a dict with the following keys
{
'access_token'
}
1.3. Setup process for user revoking authorization:
- Add functions to delete user’s connection to Deezer:
def revoke_user(self, user_id: int):
- Also set an endpoint to disconnect the services:
@profile_bp.route('/music-services/<service_name>/disconnect/', methods=['POST'])
@api_login_required
def music_services_disconnect(service_name: str):
1.4. Add frontend components to allow users to select Deezer service
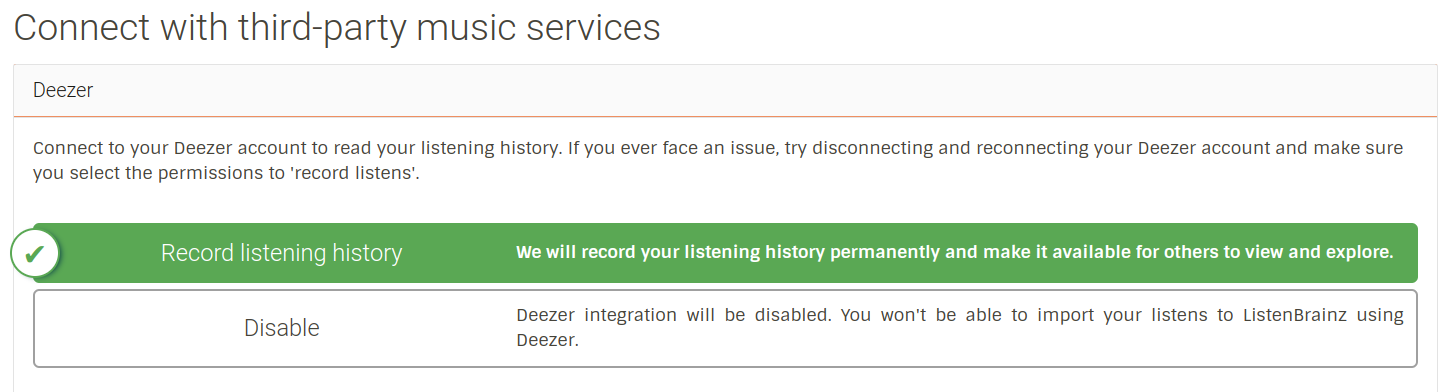
1.5. Add functions to get user’s listen data from external service
- Function to return a list of users whose listens should be imported from Deezer:
def get_active_users_to_process() -> List[dict]:
- Function which can return user’s Deezer linking details to display on connect services page;
def get_user_import_details(user_id: int) -> Optional[dict]:
- Function to get the recently listened list of user from Deezer
def get_user(user_id: int) -> Optional[dict]:
- Adding test suite for all new tasks till this point
Deezer allows setting offline_access permission (it sends expires=0 in its response) to get an access token that never expires. Thus processes for refreshing access tokens are not required.
Phase 2 - Adding a background process that collects the user’s listens from the service(Weeks 4-6):
Let the background process be called Deezer updater. The recently played list is dynamic due to the user continuously using the Deezer service. Thus this updated list needs to be polled into the LB system from the Deezer API. This involves:
- Setup update interval
Update_Interval = _some_value_
- Setup function to make requests to Deezer API for particular users at specified endpoints. Request URL for this will be -
http://api.deezer.com/user/USER_ID/history.
def make_api_request(user: dict, endpoint: str):
The API documentation does not give information about this endpoint. This post mentions on how to get a user’s recent listen history. Due to this I have tested the endpoint and received response (which indicates that it is working as of now), part of which is:
play = {
"id": "2076096427",
"readable": True,
"title": "Guddi Riddim",
"title_short": "Guddi Riddim",
"title_version": "",
"link": "https://www.deezer.com/track/2076096427",
"duration": "210",
"rank": "754755",
"explicit_lyrics": False,
"explicit_content_lyrics": 0,
"explicit_content_cover": 0,
"preview": "https://cdns-preview-b.dzcdn.net/stream/c-bdb8a25cae73d590b97178ac663f6b5f-6.mp3",
"md5_image": "382888a05c0fe58f3554ef9baecd11ce",
"timestamp": 1679857252,
"artist": {
"id": "482758",
"name": "DJ Snake",
"link": "https://www.deezer.com/artist/482758",
"tracklist": "https://api.deezer.com/artist/482758/top?limit=50",
"type": "artist"
},
"album": {
"id": "388135097",
"title": "Guddi Riddim",
"link": "https://www.deezer.com/album/388135097",
"cover": "https://api.deezer.com/album/388135097/image",
"cover_small": "https://e-cdns-images.dzcdn.net/images/cover/382888a05c0fe58f3554ef9baecd11ce/56x56-000000-80-0-0.jpg",
"cover_medium": "https://e-cdns-images.dzcdn.net/images/cover/382888a05c0fe58f3554ef9baecd11ce/250x250-000000-80-0-0.jpg",
"cover_big": "https://e-cdns-images.dzcdn.net/images/cover/382888a05c0fe58f3554ef9baecd11ce/500x500-000000-80-0-0.jpg",
"cover_xl": "https://e-cdns-images.dzcdn.net/images/cover/382888a05c0fe58f3554ef9baecd11ce/1000x1000-000000-80-0-0.jpg",
"md5_image": "382888a05c0fe58f3554ef9baecd11ce",
"tracklist": "https://api.deezer.com/album/388135097/tracks",
"type": "album"
},
"type": "track"
}
Required data can be obtained from this JSON response. A lot of other data like cover, rank, etc. is also available. I am currently unable to finds its usage, and so I am leaving function implementations that use that data for now.
- Add functions to update recent listens for this user and submit them to LB.
def process_user(user: dict, service: DeezerService) -> int:
def submit_listens_to_listenbrainz(user: Dict, listens: List, listen_type=LISTEN_TYPE_IMPORT):
- Add functions to convert music received from Deezer API to valid listens to submit to LB
def parse_and_validate_deezer_plays(plays):
""" Converts and validates the listens received from the Deezer API.
Args:
plays: a list of items received from Deezer
Returns:
tuple of (a list of valid listens to submit to ListenBrainz, timestamp of latest listen)
"""
listens = []
latest_listen_ts = None
for play in plays:
listen = _convert_spotify_play_to_listen(play)
if (latest_listen_ts is None or listen['listened_at'] > latest_listen_ts):
latest_listen_ts = listen['listened_at']
try:
listens.append(validate_listen(listen))
except ListenValidationError:
pass
return listens, latest_listen_ts
def _convert_deezer_play_to_listen(play):
""" Converts data retrieved from the Deezer API into a listen.
Args:
play (dict): a dict that represents a listen retrieved from Deezer
, this should be an "tracks" from the deezer response.
Returns:
listen (dict): dict that can be submitted to ListenBrainz
"""
return {
"listened_at": play["timestamp"],
"track_metadata": {
"artist_name": play["artist"]["name"],
"track_name": play["title"],
"release_name": play["album"]["title"],
"additional_metadata": {
"duration": play["duration"],
"submission_client": "listenbrainz",
"music_service": "spotify.com",
"origin_url": play["link"],
"deezer_id": play["id"],
"deezer_artist_id": play["artist"]["id"],
"deezer_album_id": play["album"]["id"],
}
}
}
In the 6th week, I’ll focus on completing the test scripts and documentation (if any required) for all work that has been done from Week 1-6.
Part 2 - Create a content resolver for exporting playlists to Deezer to deliver recommendations among other things (Weeks 6-11):
Phase 3 - Create a content resolver for exporting playlists to Deezer to deliver recommendations among other things (Weeks 6-11):
3.1 Retrieve Album Data
- Use artist endpoint to get albums:
https://api.deezer.com/artist/<artist_id>/albums
This endpoint sends a JSON response, which is limited in number of items and contains a next url to get the remaining data by pagination.
{
"data": [
{
"id": "294609352",
"title": "Homework (25th Anniversary Edition)",
"link": "https://www.deezer.com/album/294609352",
...
"explicit_lyrics": false,
"type": "album"
},
{
"id": "8244118",
"title": "Human After All (Remixes)",
"link": "https://www.deezer.com/album/8244118",
...
"explicit_lyrics": false,
"type": "album"
},
"total": 34,
"next": "https://api.deezer.com/artist/27/albums?index=25"
}
- Following this, below endpoint can be used to get tracks in an album:
https://api.deezer.com/album/<album_id>/tracks
The above endpoints allow us to obtain important data fields required to be stored in the database. These fields include:
Album:
Name
Release Date
Album Artist
Type (of album)
Artist:
Name
Albums
- Add function to discover and fetch album data:
def discover_albums(self, artist_id):
def fetch_albums(self, album_ids):
- This data will be inserted into tables (created in 3.2.).
3.2. Storing album data in database
-
Tables which will store Deezer data will be similar to those existing for Spotify which can be found here.
-
Add functions to store data into the tables:
def insert_album(curs, data, last_refresh, expires_at):
def insert_album_artists(curs, album_id, data):
def insert_tracks(curs, album_id, data):
def insert_track_artists(curs, data):
def insert_normalized(curs, album, last_refresh, expires_at):
""" Main function to insert data in normalized deezer tables """
...
insert_album(curs, album, last_refresh, expires_at)
insert_artists(curs, album_artists)
insert_album_artists(curs, album["id"], album_artists)
....
def insert_raw(curs, album, last_refresh, expires_at):
""" Insert data in the raw data table. This table only exists as a stop gap till we are satisfied that the
normalized tables are working correctly and well. """
....
Part 3 (Week 12) - Buffer Period
Buffer week for testing, bug fixes and improving code quality in whatever has been implemented in the previous weeks. Adding any required documentation will also be done this week.Timeline
Following is a detailed outline of the time expenditure for this project:
Pre-Community Bonding (April)
- I will work on implementing the second part of LB-1158.
- And I’ll try to engage more with the MetaBrainz community on the IRC channels. I am hoping that I’ll be able to answer technical queries related to the ListenBrainz project as my level of familiarity with the project codebase increases. I’ll also try to get additional inputs from other community members (in my proposal post on the forum and on IRC) for this project.
Community Bonding Period (May)
- I’ll work on some extra tickets (which I’ll identify along with my mentor) which will introduce some features or bug fixes that might be better to implement before integrating Deezer as an external service.
- I’ll also discuss, with my mentor, about the feasibility and implementation of all the inputs received from other members in the previous month.
If there is not much work related to the above, then I’ll begin the actual project a bit ahead of time.
Part 1 - Link Deezer external service (Weeks 1-6 | June - Mid July):
- Week 1-3: Phase 1
- Week 3-6: Phase 2
Midterm Evaluation (Mid July):
GSoC timeline stipulates midterm evaluation at the end of 6th week.
Deliverables for Midterm Evaluation: Add support for linking Deezer account for recording listen history in ListenBrainz.
Part 2 - Create content resolver (Weeks 7-11 | Mid July - 3rd Week August):
- Week 7-11: Phase 3
Part 3 - Buffer period (Week 12 | Last Week August):
- Week 12: Buffer week
Stretch Goals
- placeholder
Detailed Information about Myself
I am currently a college student, waiting for the results of the final semester examinations of my college. When I am not spending time on my laptop, I enjoy reading novels (while listening to music).
Tell us about the computer(s) you have available for working on your SoC project!
I have a Lenovo Legion Y540 with 8 GB RAM (i7-9th gen.) and 4 GB GPU (NVIDIA GeForce GTX 1650).
When did you first start programming?
I started programming with Python in June 2022. I picked up JS only 3 months back, and I am still not very good at it (I am working on that).
What type of music do you listen to? (Please list a series of MBIDs as examples.)
I mostly listen to Hindi and English music.
What aspects of the project you're applying for (e.g., MusicBrainz, AcousticBrainz, etc.) interest you the most?
I listen to music 8-12 hours for 7 days a week and that increases the need for a way to maintain many and majorly different lists. MusicBrainz has helped me a lot in that. I am also interested in backend development using Python, so by contributing to the project, I am hitting two birds with one stone.
Have you ever used MusicBrainz to tag your files?
Not much but yes. Mostly for background tracks of games I have played (latest for which I did this was Witcher 3)
Have you contributed to other Open Source projects? If so, which projects and can we see some of your code?
ListenBrainz is the first Open Source project I am contributing to.
If you have not contributed to open source projects, do you have other code we can look at?
Unfortunately, my company doesn’t allow me to do that. I have college projects also, but they are not good enough to be showcased so I’ll plead for a pass.
What sorts of programming projects have you done on your own time?
I have quite some time left after my employment related work. During that I am working on some research projects focused on improving efficiency of Graph Neural Networks models on high noise, disassortative graphs. Rest is spent on fiddling with personal forks of JS related open source projects (for learning).
How much time do you have available, and how would you plan to use it?
I’ll be giving more time in the initial 4 weeks, somewhere around 35-40 hours. Post that it will be 28-30 hours for the remaining weeks (that’s 35 x 4 + 28 x 8 = 364 hrs even in the worst case).
The less time in the later weeks is not due to other commitments, it’s just that I think work speed will increase once I have a certain level of familiarity with the project code. That said, I’ll be able to increase that any time if required.