Personal Information
- Name: Vishal Singh
- IRC nick: pixelpenguin
- Email: cvishalftw@gmail.com
- Github: VishalFTW · GitHub
- Location: Toronto, Canda
- Time zone: Eastern Daylight Time (GMT-4)
Project Details
MetaBrainz Dataset Hoster
Dataset Hoster provides a simple way to convert data into Hosted API. Using a simple template class such as

Dataset Hoster provide functionalities such as -
- Flask App
- Sentry for performance monitoring and error tracking
- Lookup datasets and return a query object
- Web page to easily discover datasets
- Error Handling
- Crossdomain access for APIs
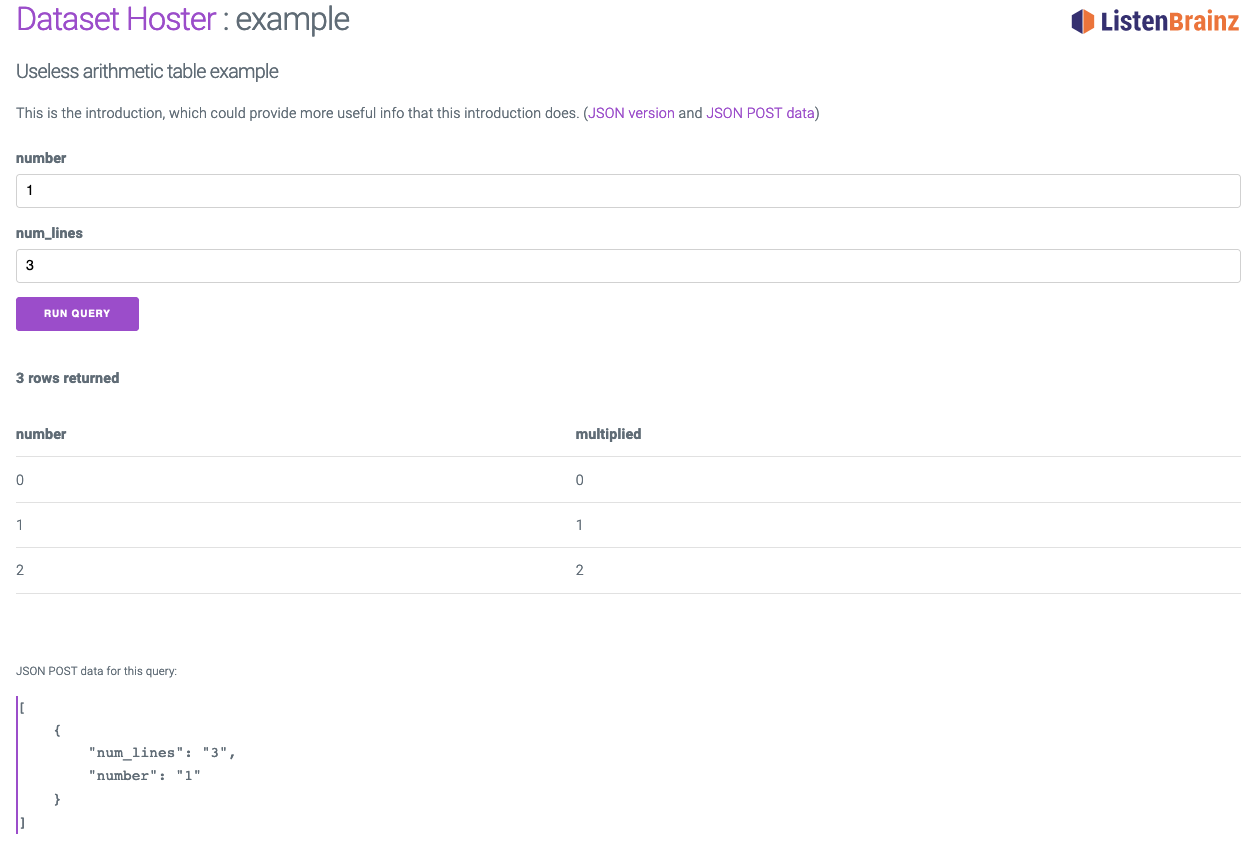
Implementation Details
Dataset Hostler Improvement will follow three types of changes:
- Simplification and improvement of result returned from query to help better understand dataset
- New features to make querying dataset easy and robust
- Code Improvement involving: Bug Fixes, Documentation, Tests (Unit + Functional)
In these categories following improvements will be made:
Type support for query parameters and Error handling (LB-1243)
Current Implementation: For defining a query only input names are taken in and information about input type is not used.
Issue: User can pass in any string value in the input for any input type, When these parameters are parsed in fetch it is expected from the developer of the query to handle the case, which is repetitive to implement and when not handled throws users errors as shown

Solution:
- Each query defines a Pydantic Model for its inputs. This gives dataset hoster the flexibility and power of pydantic types.
- Support optional and array types with this approach. Easily.
- Simple to add cross input validations. For instance, the listen sessions viewer query accepts from_ts and to_ts inputs. The query’s model can define a validator mandating from_ts <= to_ts to get better error checking without any added complexity or redundant code.
- Before validating the inputs, some manipulation will also be required on those because the dataset hoster accepts data from HTML forms, HTTP GET and HTTP POST.
Array support in dataset hoster (LB-1245)
Current Implementation: Currently for accepting multiple values for an input, multiple parameters are used.
Issue: But that doesn’t work well if there are multiple inputs and the queries want to accept multiple values for only 1 input and a single value for other inputs. For instance the similar recordings query allows bulk lookup of similar recordings for a given algorithm. The implementation requires the algorithm to be submitted in each param but ignores its values in all params except the first. This is not ideal.
Solution:
- Allow input values to accept array values.
- The pydantic support for this is simple but some work needs to be done to support it in HTTP GET and forms.
Datetime field support in dataset hoster (LB-1246)
Current Implementation: Asks user manually input unix timestamp for time field
For example, In session viewer query:

Issue: Some users might not be aware of the concept of unix time and it isn’t user friendly either to input a string of exact numbers.
Solution:
- For the backend, the support for datetime field can be added easily to the pydantic model.
- The dataset hoster detects such fields and renders those as the appropriate HTML input element in the form displayed to the user.
- Use the datetime field in inputs available in html for datetime inputs.
Add select input to dataset hoster (LB-1244)
Current Implementation: All the inputs are of type text.
Issue: In inputs like selecting algorithms for similar artists and recordings, users have to enter long strings and might not be aware of all the algorithms as well.
Solution:
- Add dropdown select options with input name and value to be returned while from the dataset hostler.
- Pydantic supports dynamic enums which can be used to load the select options for at app start time.
- I intend to figure out a more dynamic approach (allowing the options to be updated with each query execution) during the community bonding period.
Improving response format for dataset hoster (LB-1247)
Current Implementation: API returns data along with html markup text which is easy to display on the web.
For example,
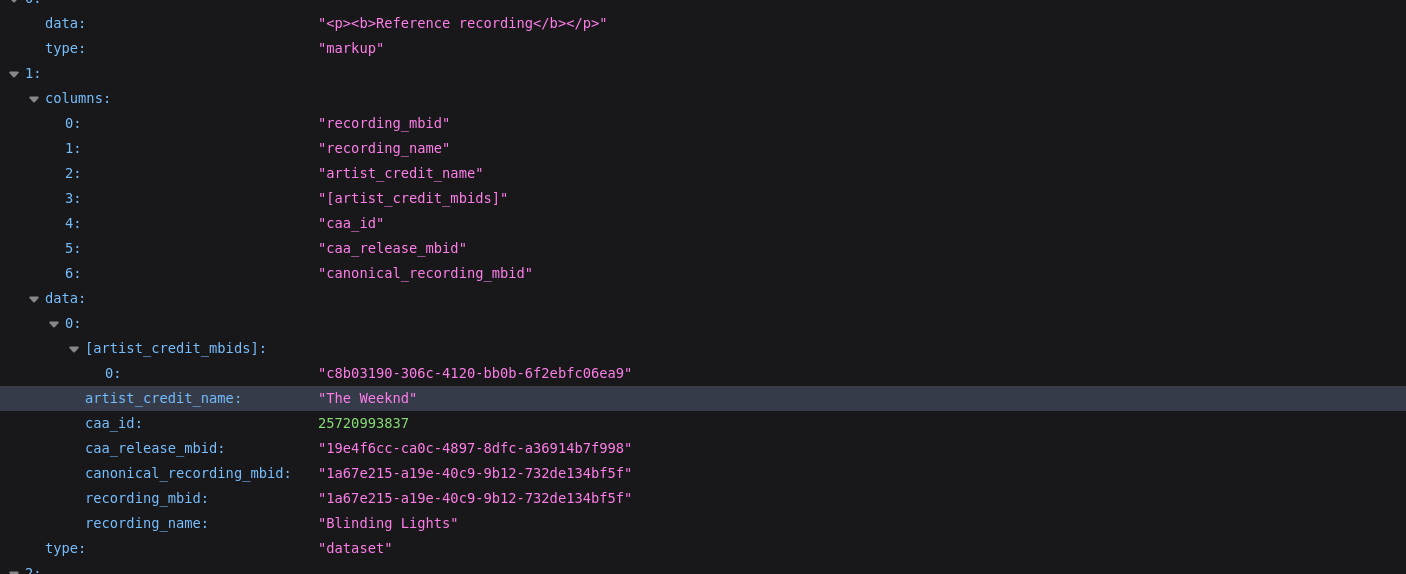
Issue: When directly calling api markup format is not required and extra data processing will be required to extract data in raw format.
Solution:
- Define a pydantic output class for outputs to receive outputs from queries in Dataset Hoster.
- Dataset Hoster renders the html or serializes the data after removing the markup and html texts in an api friendly format. Example: [{“query”: …, “response”: …}, …]
Ensure mbid links for various entities work properly in dataset hoster (LB-1248)
Current Implementation: Returns mbid in raw format and links are done at a couple of places in ad-hoc manner.
Issue: The mbid is not really helpful for users to properly go through data in the dataset and the links are missing at some places.
Solution:
- Ensure links to various types of mbids in results work properly. Add unit and functional tests to ensure this.
Allow users to invoke new dataset hoster queries from results (LB-1249)
Current Implementation: Users have to manually take the data from the result and copy it in a new dataset hoster tab to run the query.
Issue: Manually entering data to run new query slows down user to analyze dataset and also isn’t feasible for multiple queries
Solution:
- Add additional column in the result which adds a button with unique url for each row
- Clicking on the button takes the user to a new tab which will have query data pre filled.
- New results to be already populated as well if all the query parameters can be extracted from the old result.
- Add a query param to signal that the query form has been prefilled. This is important if the input is incomplete instead of failing the query should simply not be executed. The Dataset Hoster backend can check for the presence of this param and just render a filled form.
Rate limiting (LINK)
Current Implementation: A particular API can be called any number of times in any time frame.
Issue: By not rate limiting it makes API’s suspected to DoS attacks and web scraping thus data theft.
Solution:
- Allow developers to set up rate limits for API’s.
- BrainzPython has a rate limit module to apply rate limit on token and ip address.
Documentation Improvement (LINK)
- The README file doesn’t contain all the steps to set up the repository and example locally.
- Add more examples if possible to demonstrate abilities of the repository.
- Combine HACKING.md, README.md and TODO.md file.
- Example folder doesn’t contain config.json file required for docker setup.
Existing Queries Fixes
Changes in format of query class will lead to breakage in existing developed queries. Goal will be add the changes required in ListenBrainz queries and change log documentation mentioning steps to port to newer version of dataset hostler.
Tests
Although the repository contains tests in test_functions and test_views but some functions and use cases are still not covered. New changes will also require tests to be added as well.
Timeline
Following is a detailed outline of the time expenditure for this project:
Pre-Community Bonding (April)
- Discuss about the repositories, ideas to be implemented and future work.
- Engage with the MetaBrainz community on the IRC channels.
- Increase familiarity with the project codebase and query implementations of it.
Community Bonding Period (May)
- I’ll work on some existing tickets which could (not necessarily) help in the coding phase.
- Attend each dev meeting to get to know community members and its goal more.
Phase 1 (Weeks 1-6 | June - Mid July):
- Type support for query parameters and Error handling
- Bulk lookup in dataset hoster
- Datetime field support in dataset hoster
- Add select input to dataset holster
- Improving response format for dataset hoster
- Existing queries fix
- Tests
Phase 2 (Weeks 7-11 | Mid July - 3rd Week August):
- Ensure mbid links for various entities work properly in dataset hoster
- Allow users to invoke new dataset hoster queries from results
- Rate limiting
- Existing queries fix
- Tests
Phase 3 - Buffer period (Week 12 | Last Week August):
- Week 12: Buffer week
- Documentation
Detailed Information about Myself
I am Vishal, a final year computer science graduate. When I am not spending time building something, I enjoy going on drives (while listening to music).
Tell us about the computer(s) you have available for working on your SoC project!
HP Z2 Tower G4 Workstation with 16 GB RAM and Intel® Xeon(R) E-2224G CPU.
When did you first start programming?
I started programming when I was 15, I started with html and slowly moved on to development projects. Although, the amount of coding time majorly increased during university.
What type of music do you listen to? (Please list a series of MBIDs as examples.)
I mostly listen to English and Punjabi music.
What aspects of the project you’re applying for (e.g., MusicBrainz, AcousticBrainz, etc.) interest you the most?
Recently, I was deploying my assignment using flask and while working on an api for it I came to know about the dataset hostler through a friend. It was interesting to see practical examples of implementation of backend as a service and concepts involved in it. It interests me that a simple class creation allows the repository to create a whole web which can query the dataset. It should also be interesting to see how this project can be used other than MusicBrainz.
Have you ever used MusicBrainz to tag your files?
No.
Have you contributed to other Open Source projects? If so, which projects and can we see some of your code?
My major code contribution was in the internship last year but most of it is private, I haven’t really documented my work right now to show.
How much time do you have available, and how would you plan to use it?
I will be available full time during the summer for 30 hrs a week.