Continuing the discussion from Create a 'Release Radar' plugin for the Troi toolkit - GSoC 2022:
GSoC 2022 Proposal For ListenBrainz - Create a ‘Release Radar’ plugin for the Troi toolkit
Project Logistics
Project Name
Create a ‘Release Radar’ plugin for the Troi toolkit
Project Description
Development/Summer of Code/2022/ListenBrainz
Proposed mentors: mayhem
Languages/skills: Python, Postgres possibly
Estimated Project Length: 175 hours
Expected outcomes: One or more finished, debugged, and tested plugins for Troi.
Our troi recommendation toolkit is our playground for developing recommendation algorithms. The toolkit already knows how to fetch data from ListenBrainz for stats, collaborative filtered recommended tracks, similar artists, and similar recordings. From MusicBrainz, it can fetch needed metadata such as genres and tags. This project should generate a playlist every Friday that is a collection of selected tracks that have been recently released (last 2 weeks or so) by artists that are in a given user’s top artists list. We will have an API endpoint that will list recent releases for a given user, which will be implemented by a MetaBrainz team member, and your Troi plugin should select tracks from these releases and make an exploration playlist from these tracks.
Outline
-
Background
-
What is Troi and what is it for
The Troi recommendation playground is a music recommendation engine sandbox for developers based on music data in ListenBrainz and MusicBrainz. The toolkit takes advantage of the listening history records in ListenBrainz and the comprehensive music information database in MusicBrainz, allowing various ways to implement cutting-edge recommendation algorithms. This project aims to provide better music playlist services for users of ListenBrainz.
-
Current features
-
Datasets and available APIs
-
Patches
- Region-based recommendations: Area-random-recordings and World-trip, which return playlists based on songs mostly using the “area-random-recordings” API from the wolf dataset hoster.
- Artist-based (collaborative filtering) recommendations: Daily-jams and Weekly-flashback-jams, which return playlists based on top or similar artists of a given user, mostly using ListenBrainz recommendation API.
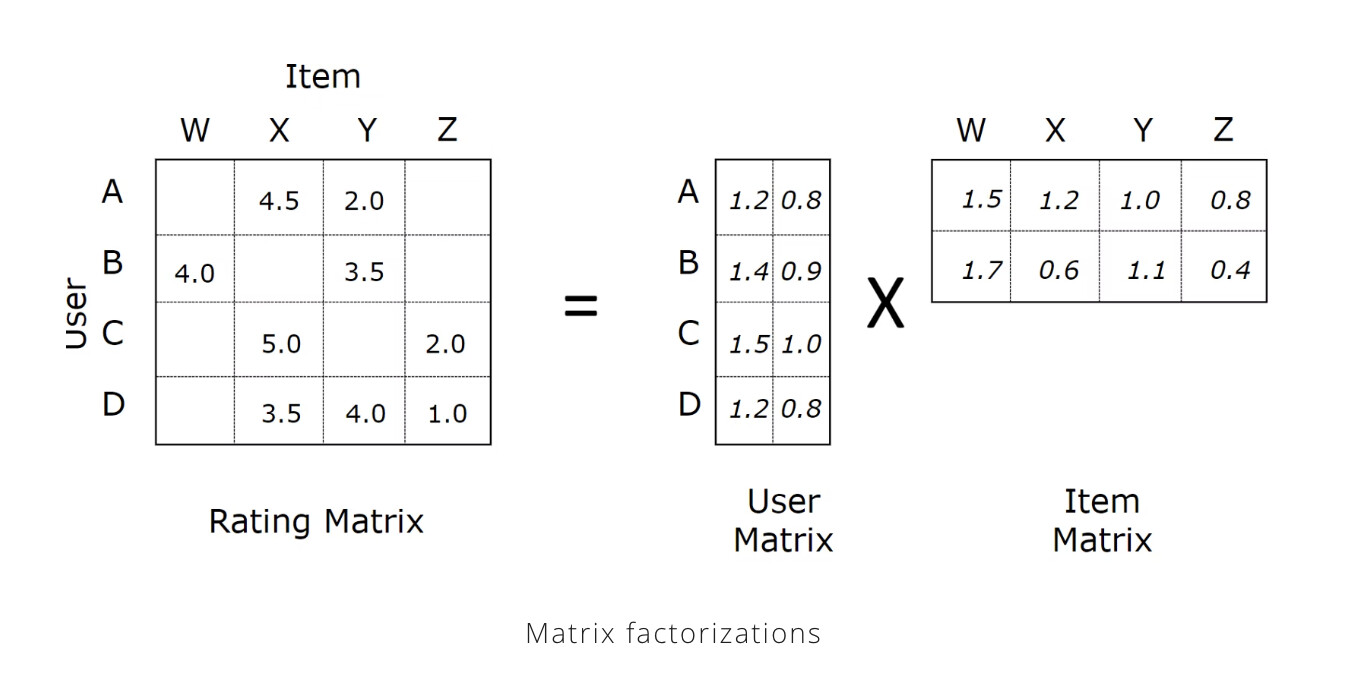
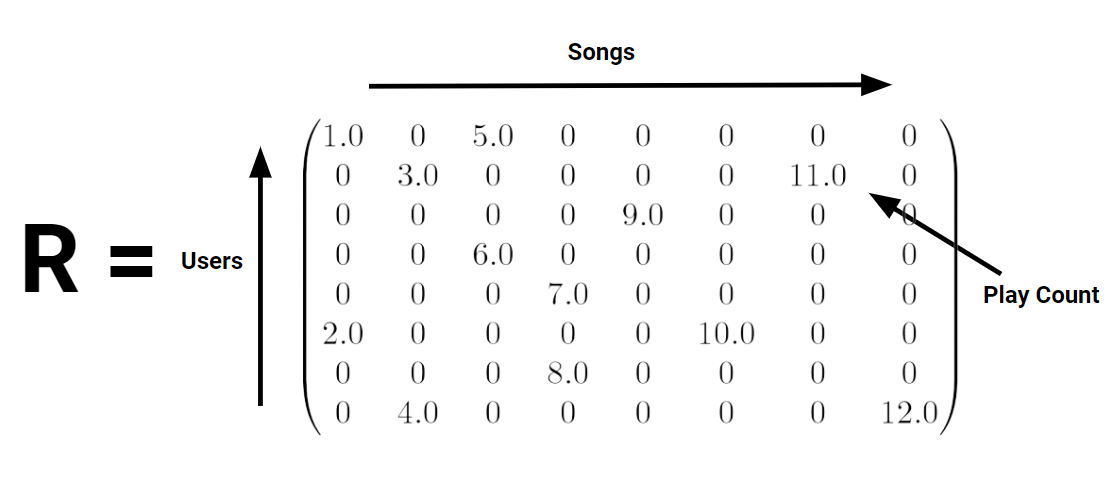
- Collaborative filtering: First represent the relationship between different users and songs using the weighted matrix factorization (WMF) algorithm. Second, generate recommendations for each user by finding the ‘K’ closest song vectors for every user vector, using the approximate nearest neighbor algorithm. The process can be simply shown in the figure below.
-
-
Why release radar
Nowadays, surrounded by music stream services, there’s no need to say how much playlists matter to us. In the tutorial on playlist, we can get a general idea that the methods and evaluations of automatic playlist generation are important.
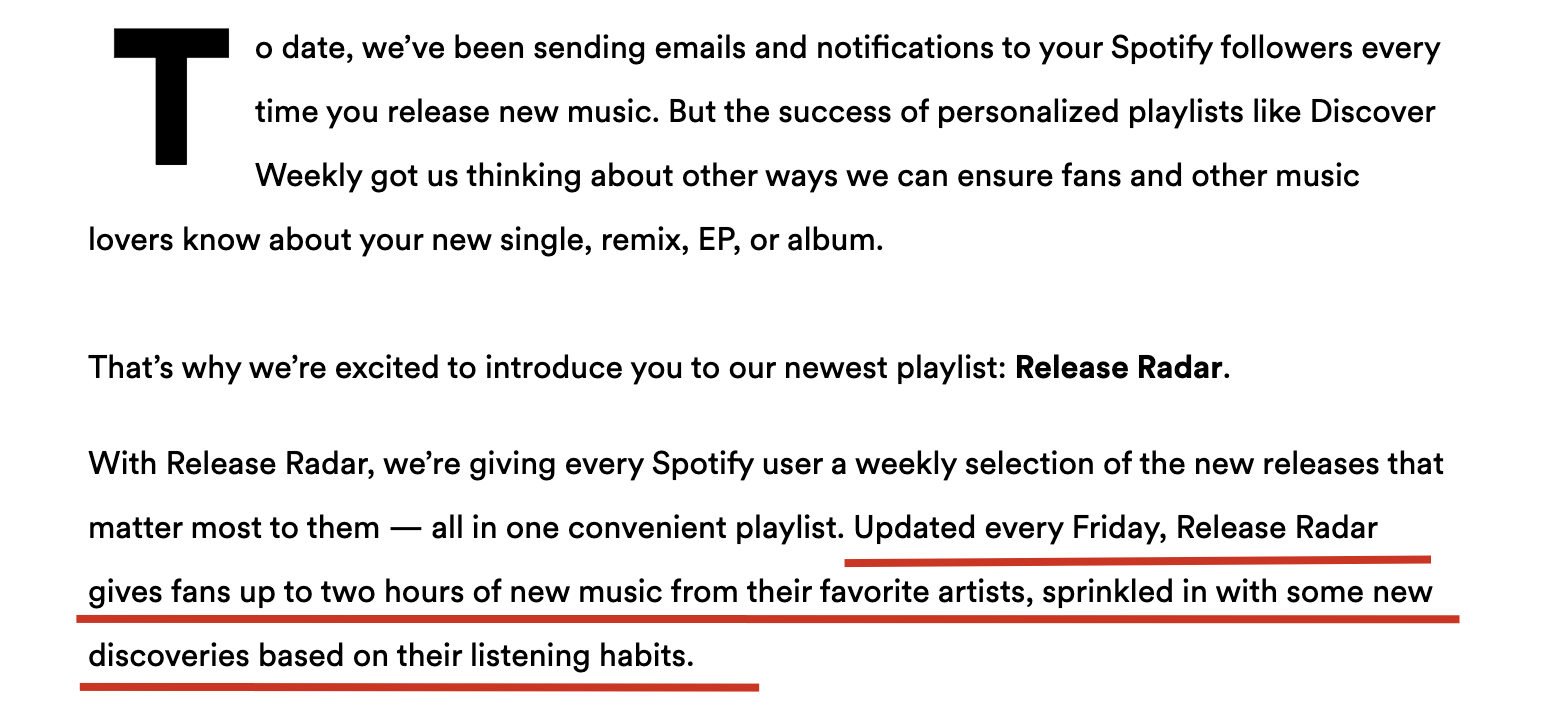
Ultimately, the playlists are meant to serve for a smooth and innovative listening experience. And as for release radar, my understanding of it comes from Spotify’s automatic playlist with the exact name: it should tailor to the user’s listening habits, including the latest music from use’s following artists, and add new blood to the user’s listening experience. This playlist can not only save users’ time to explore new songs through trial and error but also brings hidden gems or rising stars in different music styles to the public.
-
What is a good release radar
-
Factors for the goodness of a playlist
- The songs in the playlist - including the listener’s familiarity with and preference for the songs
- The level of variety and coherence in a playlist
- The order of the songs
- The song transitions
- Overall playlist structure
- Other factors: serendipity, freshness, ‘coolness’
- The Context
-
Factors for user preference
- Musical taste - long term slowly evolving commitment to a genre
- Recent listening history
- Mood or state of mind
- The context: listening, driving, studying, working, exercising, etc.
- The Familiarity
- People sometimes prefer to listen to the familiar songs that they like less than non-familiar songs
- Familiarity significantly predicts choice when controlling for the effects of liking, regret, and ‘coolness’
-
-
-
Goals and Non-goals
- A new bug-free patch that generates a weekly release radar playlist in at least one approach
- Incorporate the new release API endpoint from MusicBrainz
- Automatically deliver the playlist each Friday
- Incorporate user feedback to improve the “goodness” of the playlist generation process
-
Plugin Framework
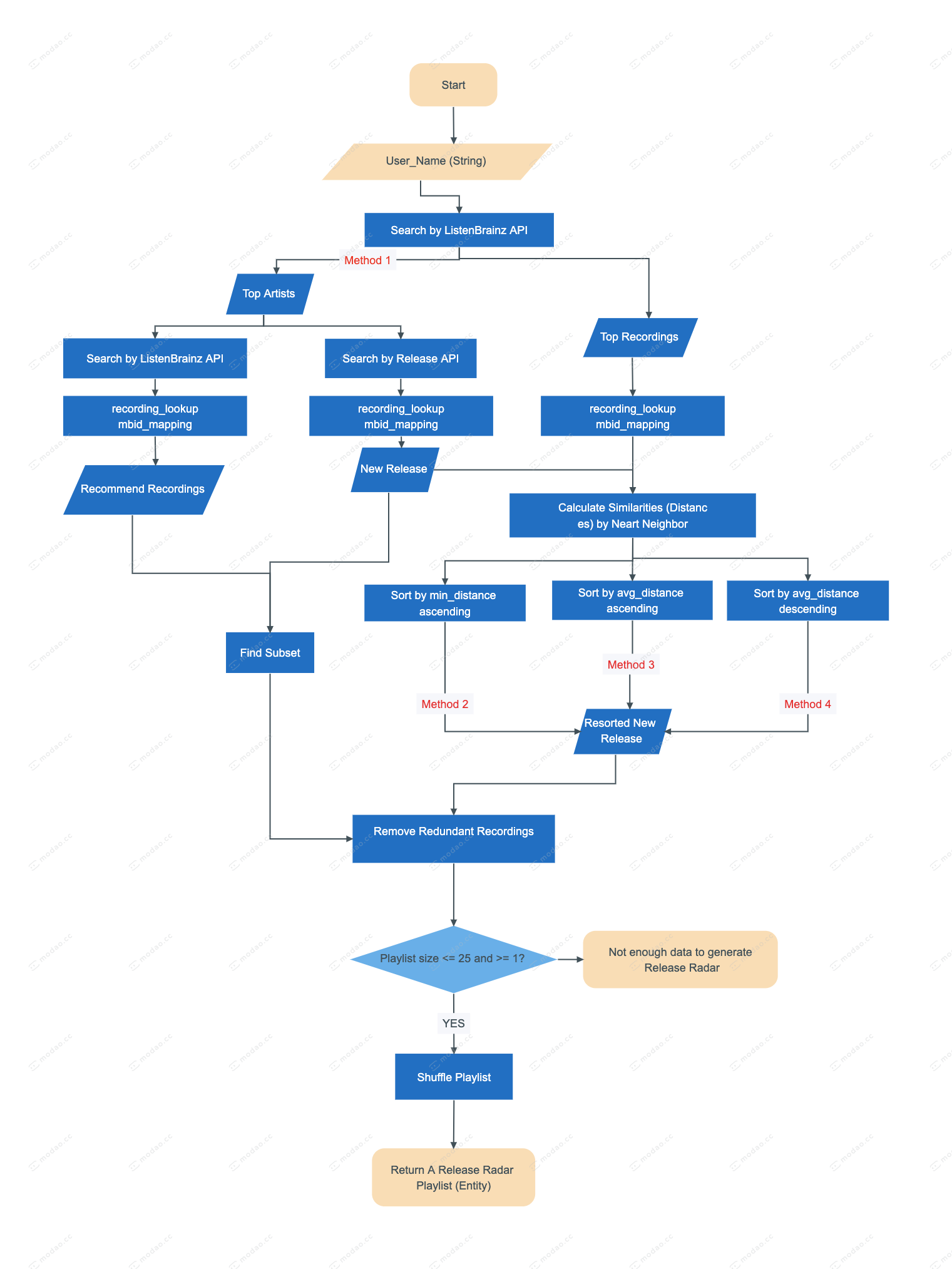
Patch description: The release radar is a patch in the Troi toolkit that takes in a MusicBrainz/ListenBrainz
user_idstring, then spits out aPlaylistentity including newly released songs by the user’s top artists. I use existent patch structures as references.- Obtain top artists and top recordings for a certain user
- Obtain top artists’ new releases within the last 2 weeks
- Transform the mbids from previous searches into lists of recordings
- sort and modify the release playlist by predicting user preferences
- remove redundant recordings in the release playlist
- Make sure the size of the release radar is between 1 to 25 recordings
- loop this patch to update the release radar list only on Friday
-
Plugin Design and Implementation
-
Release API usage
-
Input: User_Name string
-
Output: a JSON file that contains MBIDs
-
Output structure samples:
{ "payload": { "count": 25, "from_ts": 1649030400, "last_updated": 1650160844, "offset": 0, "range": "week", "releases": [ { "artist_mbids": [ "b2029169-2574-4305-820f-252a5fde3697" ], "artist_msid": null, "artist_name": "Meghan Trainor", "listen_count": 7, "release_mbid": "0d529701-f09a-431e-b088-97b4df737e37", "release_msid": null, "release_name": "Title" }, "to_ts": 1649635200, "total_release_count": 124, "user_id": "lucifer" } }
-
-
Catering to user preferences
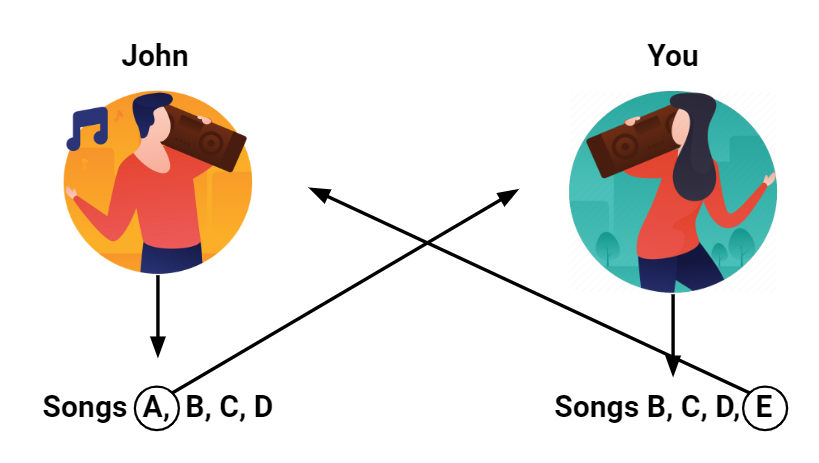
As we can see, in the WMF algorithm, the matrices are made by play count. If the song has never been played, the confidence variable will have a low value.In this case, we can’t only rely on collaborative filtering since the newly released recordings are not likely to exist in most users’ listening histories. We need to combine the collaborative filtering algorithm with the release recordings fetched by our new API. The relationships between my proposed methods for predicting preferences can be drawn as below:
-
User-similarity-driven
method 1:Simply looking for the subset of new release playlist and recommendation recordings both based on top artist of the user.
-
Recording-similarity-driven
method 2&3:This is to assume that people love to hear songs that are similar to their previous loved songs.
Use a distance-based similarity algorithm such as spotify annoy to get scores between recordings in the release playlist and the top listening (ranked by play count) recordings. Then get the distance between each recording in the release playlist and all the recordings in the user’s top listening playlist.
Method 2Catch your favorite tastes: Sort the release playlist by the minimum distance ascendingly to any recording in the top listening playlist, so that the new songs are very likely to be the user’s new favorite regardless of the user’s listening habits.Method 3Play in the safe zone: Sort the release playlist by the average distance ascendingly to the whole top listening playlist, so that the new songs are relatively close to the user’s current listening habits. -
Novelty-driven method
Method 4New blood: Sort the release by the average distance descendingly to the whole top listening playlist, so that the new songs are totally opposite to the user’s current listening habit. It may be helpful for the user to discover a new continent in the music world.
-
-

Expected Timeline for Deliverables

Extra Information
Working Time
I will be based in New York, NY during the summer, which is in Eastern Daylight Time (EDT, GMT -5) timezone. I will not take any classes during the summer but will work on a research project besides this project. I will be able to continuously spend about 12 weeks on this project, each week spending about flexible 10-30 hours depending on the progress of each period. I can also start early to prepare for the project prior to the official start of the coding period.
References
- B. Fields, “Contextualize Your Listening: The Playlist as Recommendation Engine”, PhD Thesis, Goldsmiths, University of London, April 2011.
- Tutorial: “Finding a Path Through the Juke Box: The Playlist Tutorial,” given at ISMIR 2010, 9 August 2010 in Utrecht, The Netherlands. Co-presented with Paul Lamere. Slides as slideshare, pdf.
- Aparna, R., Chandana, C.L., Jayashree, H.N., Hegde, S.G., Vijetha, N. (2022). Emotion and Collaborative-Based Music Recommendation System. In: Hemanth, D.J., Pelusi, D., Vuppalapati, C. (eds) Intelligent Data Communication Technologies and Internet of Things. Lecture Notes on Data Engineering and Communications Technologies, vol 101. Springer, Singapore. https://doi.org/10.1007/978-981-16-7610-9_59
- Schedl, M., Knees, P., McFee, B., Bogdanov, D., Kaminskas, M. (2015). Music Recommender Systems. In: Ricci, F., Rokach, L., Shapira, B. (eds) Recommender Systems Handbook. Springer, Boston, MA. https://doi.org/10.1007/978-1-4899-7637-6_13
- How does Spotify’s recommendation system work? - Arya Mohan
- Personalization of Spotify Home and TensorFlow - Tony Jebara
- Introduction to Recommender Systems