GSoC 2019: Support For Reviewing and Rating More Entities (CritiqueBrainz)
Personal Information
Name: Shamroy Pellew
IRC: spellew
Email: spellew1298@gmail.com
Personal Website: https://shamroy.me/
GitHub: spellew · GitHub
LinkedIn: https://linkedin.com/in/shamroyp
Time Zone: UTC−05:00
Project Details
Overview
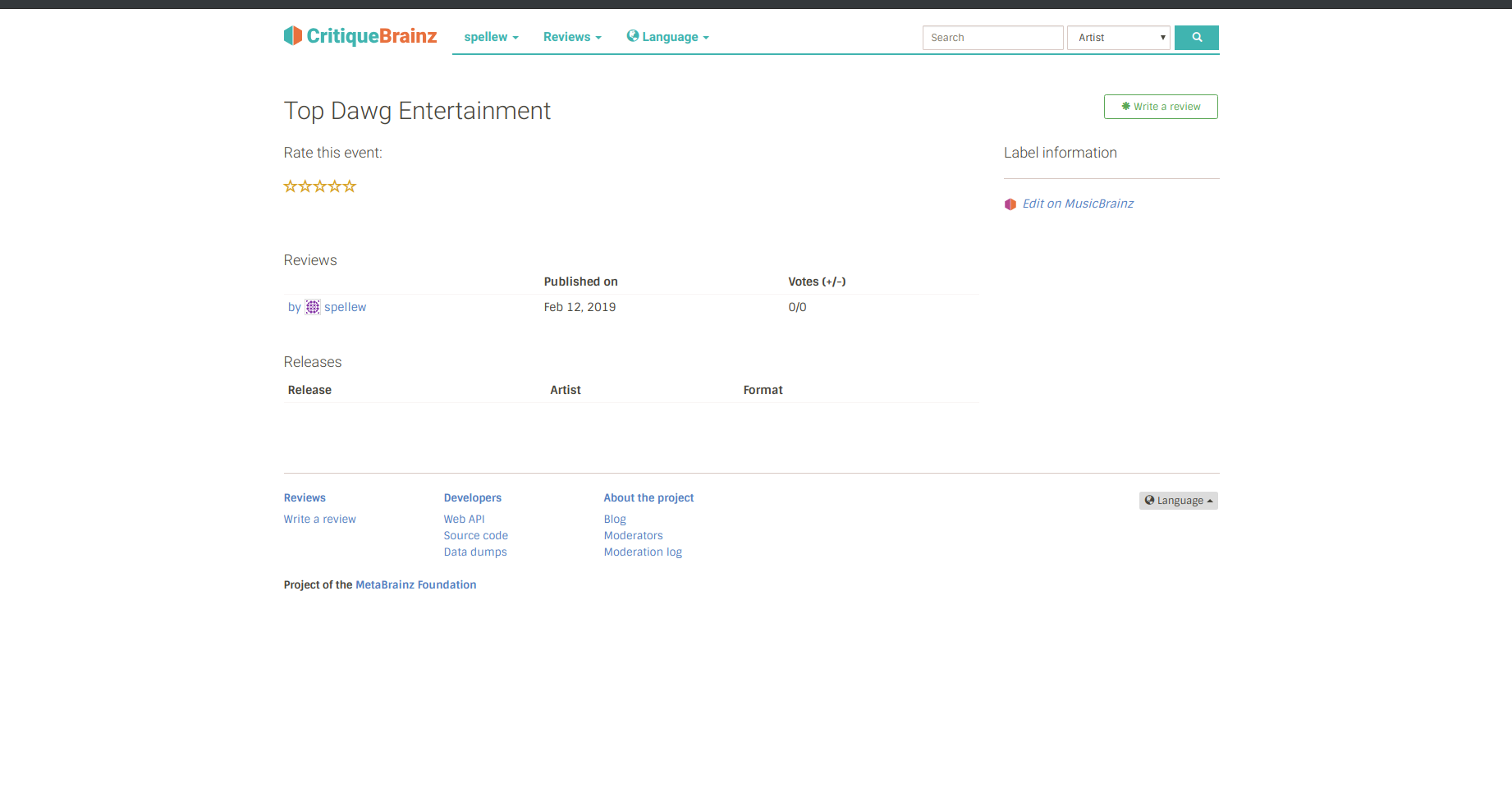
Currently CritiqueBrainz’ users can review release groups, events, and places. I plan on expanding this, by implementing reviews for other MusicBrainz entities. This metadata will be retrieved from MusicBrainz through the mbdata module, and I’ll be extending the CritiqueBrainz back-end and the front-end to support reviews for these entities. Here are a few mockups of the changes to the web interface:
I plan on adding new options to the entity selector in the top-right corner of the site.
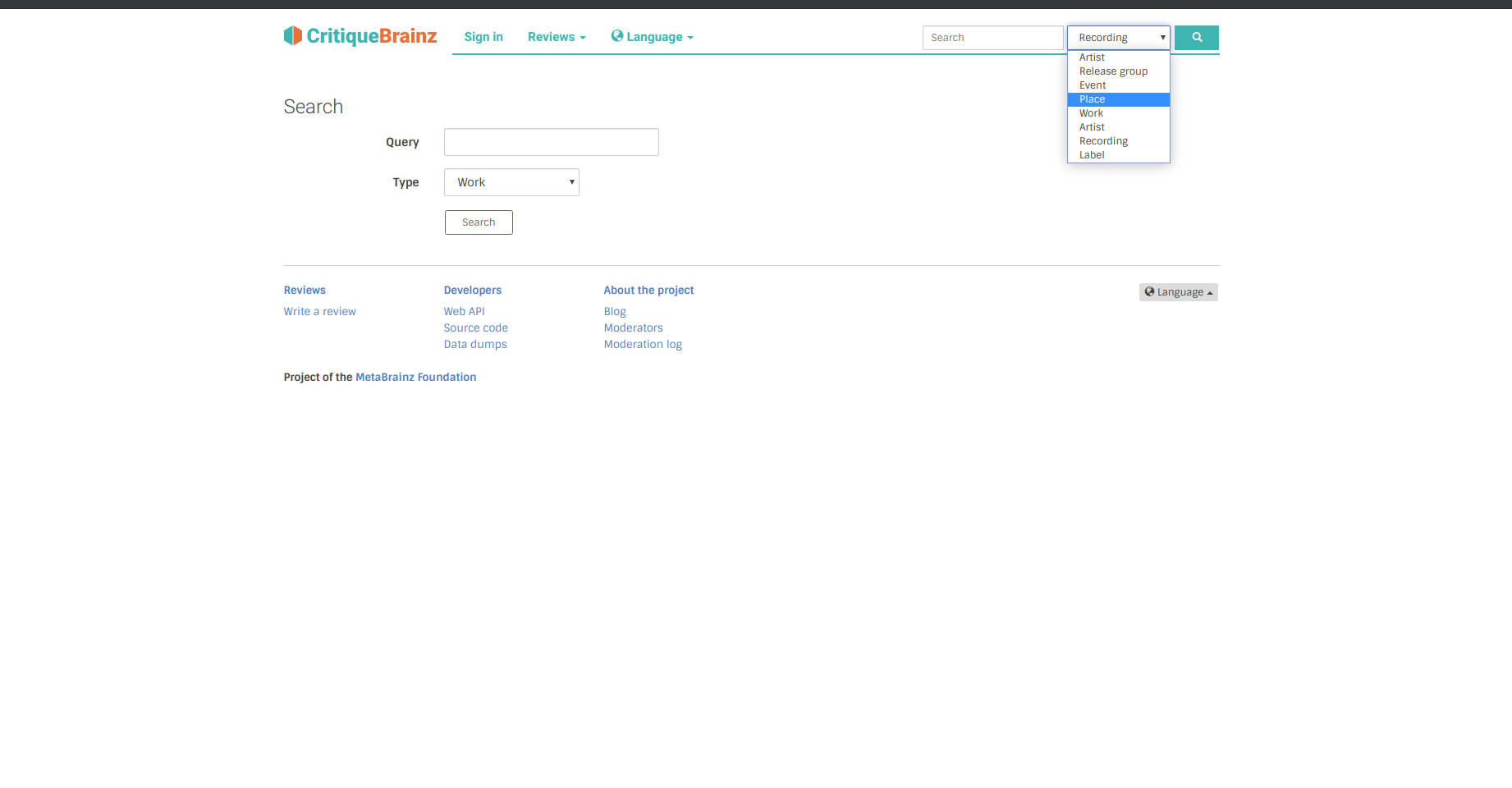
Then, when users search for one of these new entities, the backend functions I plan to write, will handle the query and returning the respective entities.
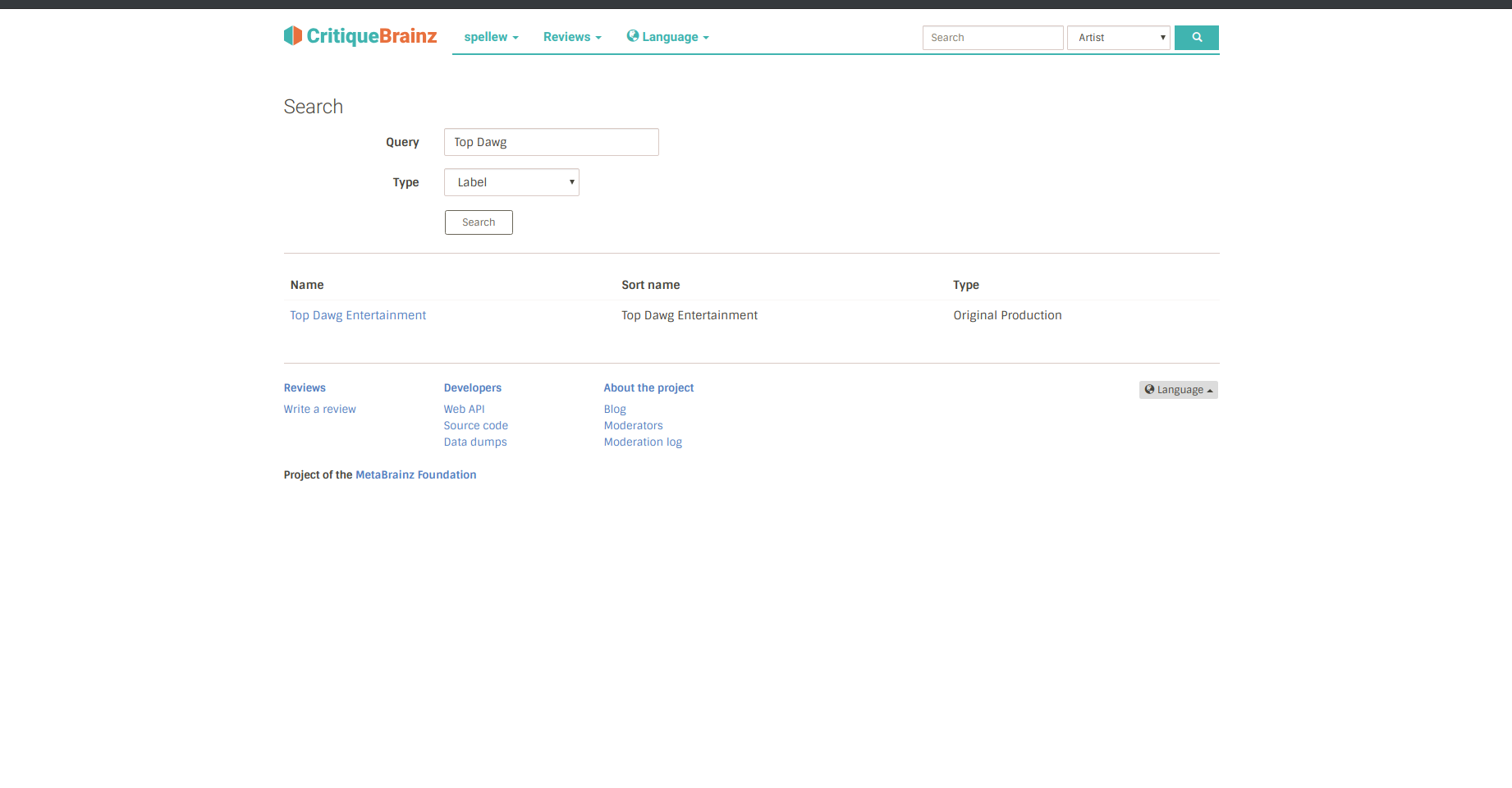
These entities will be given their own pages, crafted from Jinja templates, and displaying information from database queries.
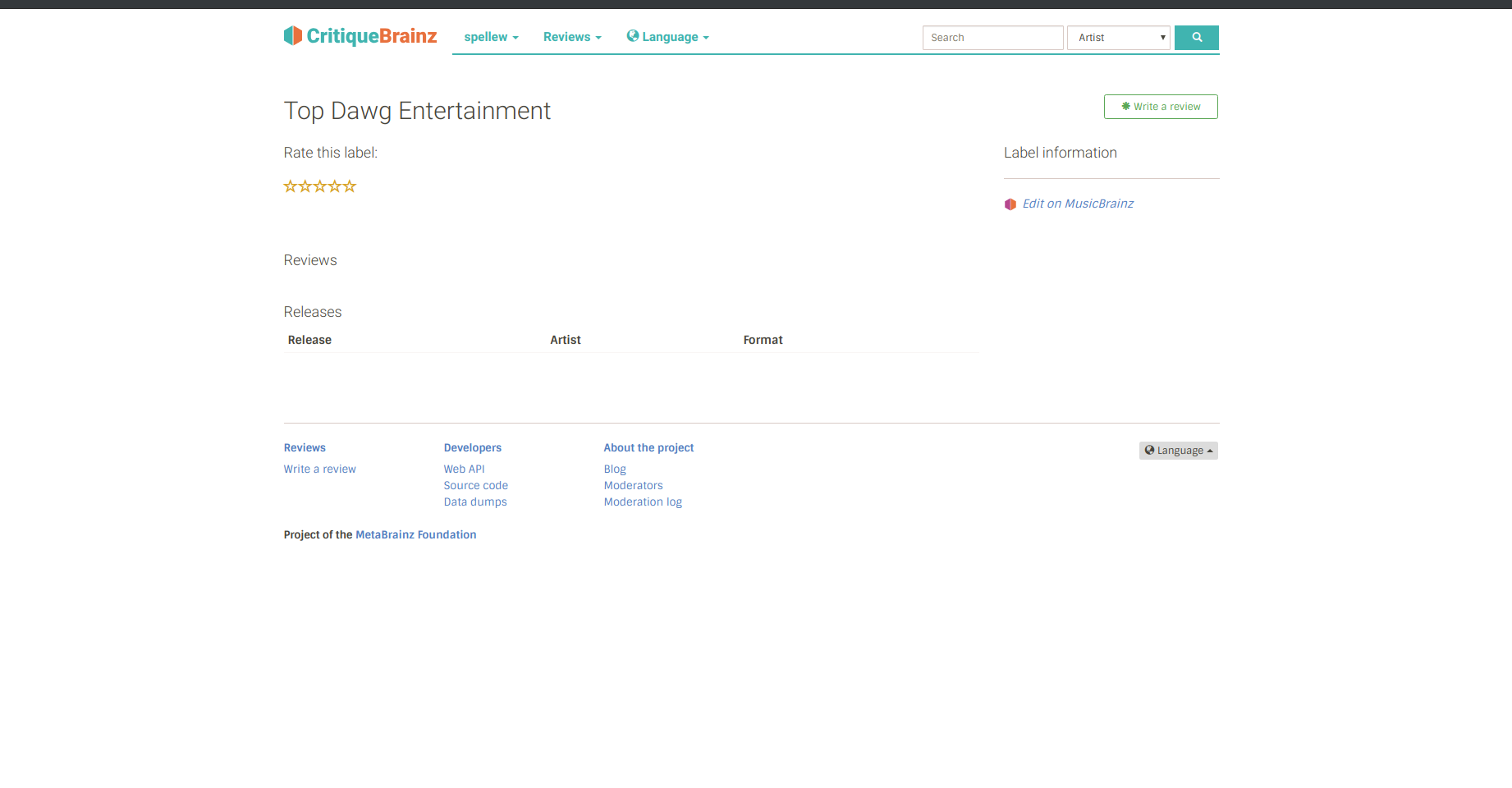
Users will be able to write reviews for these entities using the WYSIWYG editor, and it’ll look the same as if they were writing reviews for any other entity.
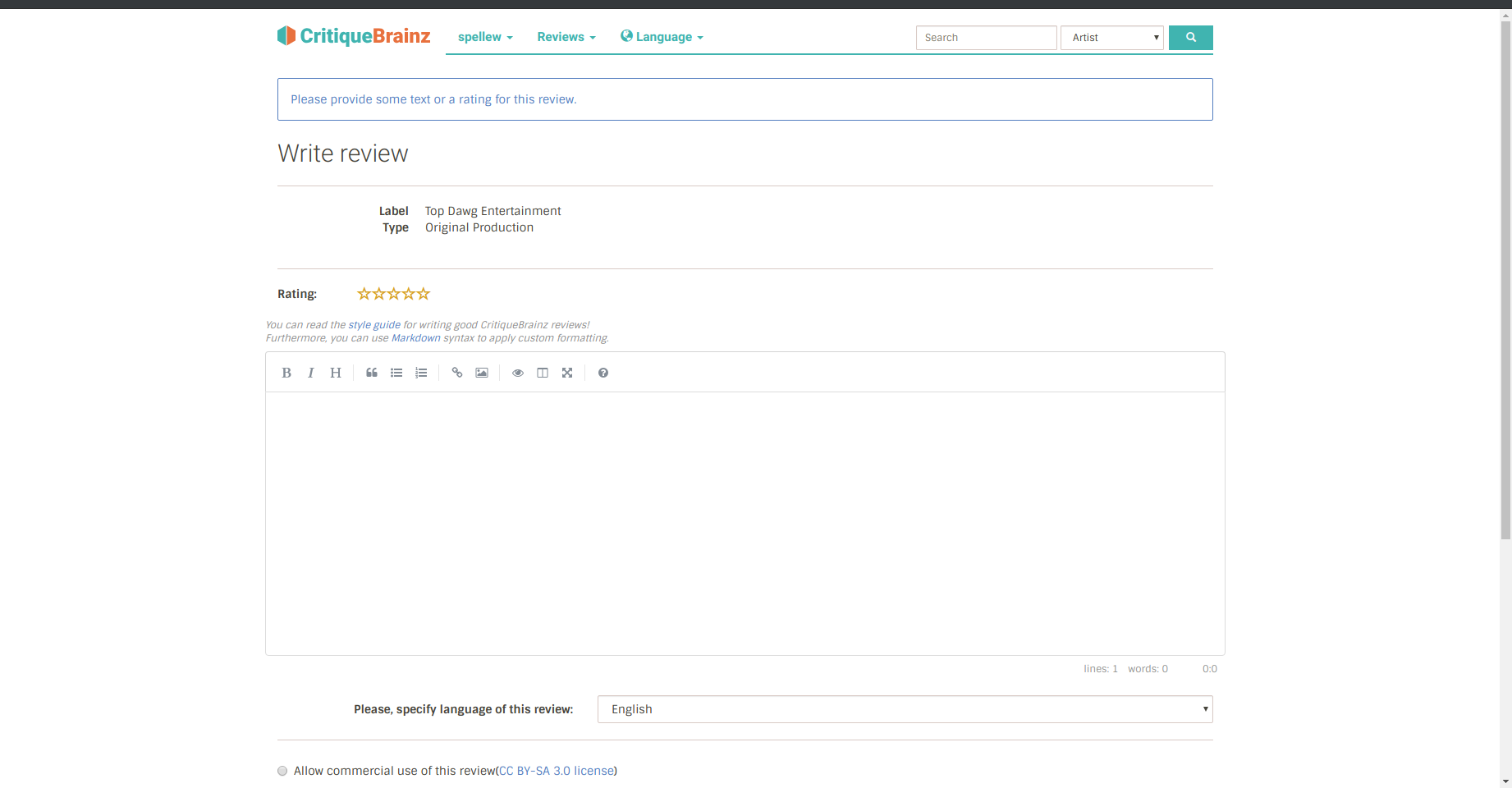
After the review is posted, anybody can navigate to the entity page and click on the review to see it.
Here are some nonfinal, sample scripts I plan to run on the database:
-
admin/schema_changes/16.sql
ALTER TYPE entity_types ADD VALUE 'label' AFTER 'place'; -
admin/sql/create_types.sql
CREATE TYPE entity_types AS ENUM ( ... 'label' ... );
Here is some sample code, the final code I write during the summer will of course support more entities:
-
critiquebrainz/frontend/external/musicbrainz_db/includes.py
RELATABLE_TYPES = [ ... 'label', ... ] VALID_INCLUDES = { ... 'label': ["aliases", "annotation"] + RELATION_INCLUDES + TAG_INCLUDES, ... } -
critiquebrainz/frontend/external/musicbrainz_db/serialize.py
def to_dict_labels(label, includes=None): if includes is None: includes = {} data = { 'id': label.gid, 'name': label.name, } if 'type' in includes and includes['type']: data['type'] = includes['type'].name if 'area' in includes and includes['area']: data['area'] = to_dict_areas(includes['area']) if 'relationship_objs' in includes: to_dict_relationships(data, label, includes['relationship_objs']) return data -
critiquebrainz/frontend/external/musicbrainz_db/utils.py
ENTITY_MODELS = { ... 'label': models.Label, ... } REDIRECT_MODELS = { ... 'label': models.LabelGIDRedirect, ... }
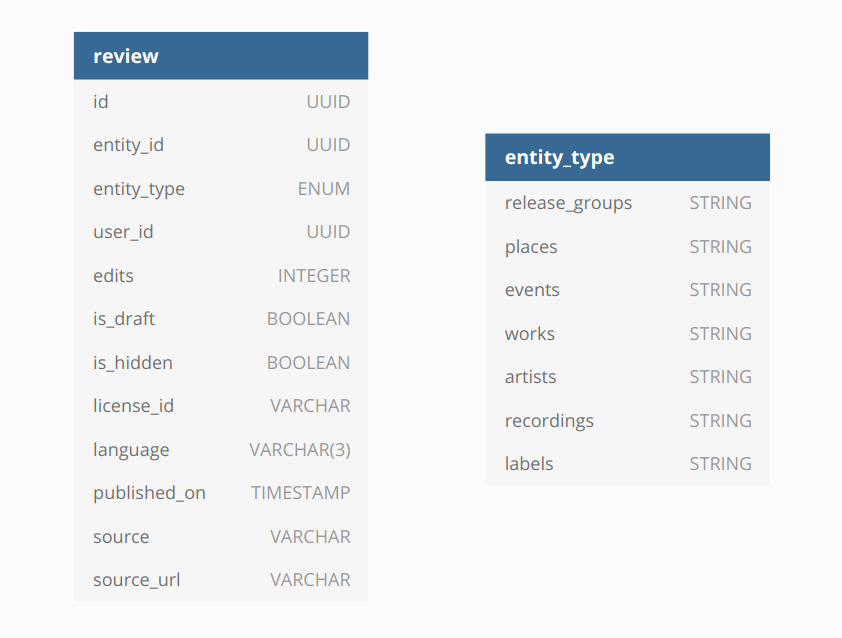
I also plan on importing entity ratings using the MusicBrainz database, and incorporating this data into the CritiqueBrainz entity pages. I would accomplish this by adding the corresponding entity meta models, like LabelMeta, and joining it to the queries to the database. This data would then be serialized, and retrievable from the frontend.
Proposed Timeline
Community Bonding: I’ll sit in on weekly meetings, and familiarize myself with the community, my mentor, and CritiqueBrainz, as I work on bug fixes/features related to my proposal.
Phase 1
Week 1 (May 27): Continue familiarizing myself with the source code and documentation. Make adjustments to the SQL scripts in order to support reviews for the new entities.
Week 2 (June 3): Implement the searching of the new entities by making relevant changes to search.py and the corresponding Jinja template.
Week 3 (June 10) : Produce code using mbdata models to retrieve data from the database for queries regarding works.
Week 3.75 (June 14) : Produce code using mbdata models to retrieve data from the database for queries regarding artists.
Week 4.5 (June 20) : Produce code using mbdata models to retrieve data from the database for queries regarding recordings.
Week 5.25 (June 26) : Produce code using mbdata models to retrieve data from the database for queries regarding labels.
Week 6 (July 1): Implement the creation of these entities by making relevant changes to review.py and the corresponding Jinja template.
Phase 2
Week 7 (July 8): Produce blueprints for works and create the Jinja templates corresponding to this new entity.
Week 7.75 (July 12): Produce blueprints for artists and create the Jinja templates corresponding to this new entity.
Week 8.5 (July 18): Produce blueprints for recordings and create the Jinja templates corresponding to this new entity.
Week 9.25 (July 24): Produce blueprints for labels and create the Jinja templates corresponding to this new entity.
Week 10 (July 30): Write tests checking if the creation and retrieval of mock works succeeds and if the corresponding entity page is updated.
Week 10.75 (August 5): Write tests checking if the creation and retrieval of mock artists succeeds and if the corresponding entity page is updated.
Week 11.5 (August 9): Write tests checking if the creation and retrieval of mock recordings succeeds and if the corresponding entity page is updated.
Week 12.25 (August 15): Write tests checking if the creation and retrieval of mock labels succeeds and if the corresponding entity page is updated.
Week 13 (August 19): Buffer period — ensure goals were reached.
Other Information
My name is Shamroy Pellew, and I am a current undergraduate student at the University of Buffalo, located in Buffalo, New York, USA. I participated in Google Code-in 2017, and that was my first real introduction to MetaBrainz. I’m looking forward to sticking around contributing.
Q: Tell us about the computer(s) you have available for working on your SoC project!
A: I’ll be using my laptop while working on my SoC project, it’s a ASUS ZenBook UX330UA (Core i5 Processor, 8GB RAM) running Ubuntu 18.04 LTS.
Q: When did you first start programming?
A: I started programming my the summer between my sophomore and junior year of highschool — it’s been almost three years since then. The first languages I learned were Python and JavaScript.
Q: What type of books do you read? (Please list a series of BBIDs as examples. (And feel free to also list music you listen to!))
A: I mainly read fiction books. Here’s the BBIDs of books I’ve previously read and enjoyed: Great Expectations [c7023278-b25c-419e-9061-33bd55cca45e], A Thousand Splendid Suns [ad011741-edb6-45c8-b2e7-55af23fe1cc9], and The World According To Garp [21ae8ac6-0b05-49bd-b76a-28a1d075dc9e]. And here’s my favorite song at the moment, Ace [ad2365e7-a6ba-4c97-b304-d166d58a87c3].
Q: What aspects of the project you’re applying for (e.g., MusicBrainz, AcousticBrainz, etc.) interest you the most?
A: I’m interested in the languages and frameworks that the project will be coded in, gaining experience in them would be a great aid. I also support the openness of CritqueBrainz, and it’s availability to anyone with internet access. I can see myself and some of my colleagues using the API sometime in the future, and as such I’d like to continue work on the project after SoC ends.
Q: Have you contributed to other Open Source projects? If so, which projects and can we see some of your code? If you have not contributed to open source projects, do you have other code we can look at?
A: I participated in Google Code-in 2017, here’s some pull requests from that: MBS-9590: Rewrite the instrument list in React/JSX by spellew · Pull Request #595 · metabrainz/musicbrainz-server · GitHub,
Also, here’s some of my public GitHub repositories:
GitHub - spellew/ambrosia: An all in one, meal planner, recipe book, and virtual assistant, determined to get you living a healthy lifestyle. · GitHub (hackathon project)
GitHub - spellew/logs-analysis-project · GitHub (udacity)
GitHub - spellew/OAuth2.0: Starter Code for Auth&Auth course · GitHub (udacity)
GitHub - spellew/itemize · GitHub (udacity)
GitHub - spellew/frontend-nanodegree-feedreader · GitHub (udacity)
https://github.com/spellew/cse-115-project-2 (class project)
https://github.com/spellew/cse-116-project-1 (class project)
Q: What sorts of programming projects have you done on your own time?
A: In my own time, I’ve mostly done web development projects involving JavaScript and Python. Some technologies I’ve used include React, Node.JS, Flask, Bottle, React Native, SQL, VueJS, Express etc.
Q: How much time do you have available, and how would you plan to use it?
A: I believe I’ll have most weekends and weekday evenings available to work on my project, due to me pursuing an internship over the summer. Therefore, I should be able to devote at least 30 hours to the project every week, maybe more.
 ). I am aware the deadline is tomorrow already. Apologies for being so late in adding some comments.
). I am aware the deadline is tomorrow already. Apologies for being so late in adding some comments.