Personal Information
-
Name : Vansika Pareek
-
IRC nick: pristine__
-
E-mail: vansikapareek2001@gmail.com
-
Github: https://github.com/vansika
-
Time Zone: UTC+0530
Overview
ListenBrainz has recently shifted its statistics infrastructure from Google BigQuery to Apache Spark. Apart from delivering statistics/graphs to end user, using Spark’s cluster computing, its MLlib can be effectively exploited to build an open-source music recommendation system to promote artists across the globe and not just a sect.
Project Details
Since February, I under the guidance of Robert Kaye and Param Singh (MetaBrainz members) have been contributing to building prerequisites for the recommendation system. Creating a pipeline using RabbitMQ to exchange data (statistics) between ListenBrainz Server and ListenBrainz Playground is a major contribution. Also, setting up Spark configurations to minimize the data processing time has been taken care of by the team. During summers the project would kick-start with building a simple recommendation system and then gradually moving on to a complex one.
Recommendations: ‘Daily Delight’
-
For an existing user, the under-mentioned algorithm shall be used to create a playlist of songs; ‘Daily Delight’, on the basis of the daily history of a user.
-
A new playlist shall not be generated if the users have not visited their ‘Daily Delight’.
-
A playlist comprising of top trending or staff picks shall be recommended to a new user till history of the user is obtained.
As an extension, more than one playlist shall be generated for the users by grouping history on the basis of genres, language etc. and then extracting recommendations.
Algorithm to be used
Collaborative filtering is a technique used by recommender systems to make automatic predictions about the taste of a user by using preferences/ratings of other similar users (neighbourhood of the given user). The listens of a user are equivalent to their preferences/ratings. To find the neighbourhood of the user, a notion of similarity between the users should be defined.
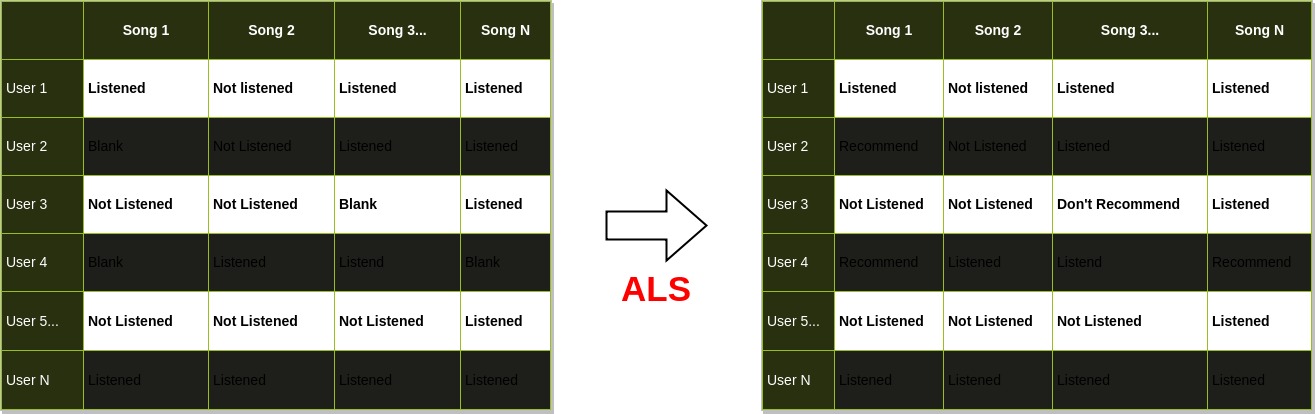
In the figure, (user 1 and user2), (user 3 and user 5) and (user 4 and user N) are similar.
Spark’s MLlib uses Alternating Least Squares (ALS) algorithm to predict the missing ratings. Given a matrix/table R of user ratings, ALS will factor R into two smaller matrices namely U and P which if multiplied together produce an approximation of the original matrix R with blank spaces filled using internal algorithms.
Schema change
Table ‘daily_delight’’ would be added in ListenBrainz server.
CREATE TABLE daily_delight (user_id integer, playlist JSONB, last_updated TIMESTAMP WITH TIME ZONE NOT NULL DEFAULT NOW());
Recommendations would be requested for those users whose timestamp value is not null i.e. users have listened to their playlist.
Flow of data

During summers, I would like to build a pipeline similar to the one discussed above in project details which would work as follows:
ListenBrainz server would create recommendation requests which would go to the Spark cluster via RabbitMQ. The Spark cluster would then create recommendations by fetching listens from hdfs and the recommendations would be passed over to ListenBrainz server using a different queue where they will be stored in the database.
Timeline
A broad timeline of the work to be done is as follows:
Community Bonding (May 5 - May 29)
Spend this time to do everything that needs to be done before starting the GSOC work and discuss design decisions with mentor.
Phase 1 (May 30 - June 25)
This phase would involve creation of daily playlist for the users and showing them on the ListenBrainz website. Ideally, we would have daily playlist in the production site by the end of this phase.
Phase 2 (June 26 - July 30)
In this phase I would mainly work on establishing pipeline to exchange requests and recommendations between ListenBrainz Server and ListenBrainz Playground.
Phase 3 (August 1 - August 29)
Work with the team to get open PRs merged before the summer is over is how this phase would evolve . Also, start work on weekly playlist (generating recommendations by monitoring history over a week) if time permits.
After Summer of Code
Continue working on ListenBrainz as I have been since January and would try to improve recommendation system as a whole.
Here is a more detailed week-by-week timeline of the 13 week GSoC coding period to keep me on track:
-
Week 1: Begin with setting up environment, spark credentials etc.
-
Week 2: Create new tables for postgres and start working on RabbitMQ
-
Week 3: Implement Collaborative filtering algorithm and generate recommendations.
-
Week 4: Work on generating precise “Daily Delight”. PHASE 1 evaluation here
-
Week 5: Taking mentor evaluation into account, fix stuff in code written so far and continue coding.
-
Week 6: Establish pipeline to send recommendation request to ListenBrainz Playground from ListenBrainz Server.
-
Week 7: Establish pipeline to send actual recommendations from Playground to Server.
-
Week 8: CUSHION WEEK: If behind on stuff, then catch up. If not, then continue with plan, with an intent to get some optional ideas. PHASE 2 evaluation here
-
Week 9: Continue to improvise the recommendation algorithm.
-
Week 10: Show recommendations on ListenBrainz website.
-
Week 11: Evaluate performance and fix bugs.
-
Week 12: CUSHION WEEK: If behind on stuff, then catch up. If not, then work on optional ideas.
-
Week 13: Pencils down week. Work on final submission and make sure that everything is okay.
Detailed Information about yourself.
I am a junior CS undergrad at the National Institute of Technology, Hamirpur. I’ve been helping out in development work in ListenBrainz Server and ListenBrainz Playgorund since this January. Here is a list of pull requests made in server and list of pull requests made in playground over time, most notable of which is the Consumer for ListenBrainz-server which creates a channel to consume statistics from Listenbrainz-playground.
Question: Tell us about the computer(s) you have available for working on your SoC project!
Answer: I have a Lenovo laptop with an Intel i5 processor and 4 GB RAM, running Ubuntu 18.04.1.
Question: When did you first start programming?
Answer: I have been programming since 11th grade, mostly in Java. I started with Python in my second year of high school.
Question: What type of music do you listen to?
Answer: I listen mostly to sufi, along with some hip hop etc. Favorites of mine (with links to MusicBrainz) include Ali Sethi, Javed Bashir , [Vince Staples] (Log in - MusicBrainz) and OneRepublic.
Question: What aspects of ListenBrainz interest you the most?
Answer: The fact the data is open and is slowly being used to recognize artists from all sects interest me the most.
Question: Have you ever used MusicBrainz to tag your files?
Not yet.
Question: Have you contributed to other Open Source projects? If so, which projects and can we see some of your code?
ListenBrainz is my first Open Source project.
Question: What sorts of programming projects have you done on your own time?
I have worked on Bucket Series , a program that tells you when the next episodes of your favorite TV shows are airing.
Question: How much time do you have available, and how would you plan to use it?
I have holidays during most of the coding period and can work full time (45-50 hrs per week) on the project.